

自动驾驶中基于图搜索的常用路径规划算法介绍
描述
自动驾驶汽车从A点行驶到B点,需要轨迹规划算法来进行全局规划,而具体都有哪些算法呢?这篇文章想和大家分享一下一类最常用的轨迹规划算法,基于图搜索的规划算法。
在开始介绍图搜索算法之前,先简单介绍一下自动驾驶中的规划问题:规划模块处于自动驾驶软件框架中的中间位置,其接收感知、定位、地图发来的上游信息,输出一条安全、平稳、舒适的轨迹给到控制模块,因此起到了一个承上启下的作用,可以说是影响自动驾驶中舒适性及安全性最重要的一环。而传统意义上的规划问题可以分为两个步骤。
前端负责粗粒度的路径查找,搜索出一条可行路径;后端负责细粒度的轨迹生成,生成出一条控制模块可以很好执行的平滑轨迹。而这篇文章想要探讨的,就是前端路径搜索中一种最常用的方法,基于图搜索的路径规划算法。
图搜索基础
图是数据结构中非常重要的一个概念,包含了节点和边。在自动驾驶中,通常可以将地图存储为栅格地图,每一格就代表了图的节点,格与格之间的连线就代表了边。
上图展示了一种无向图,即节点之间的连线是没有指向的。而在实际场景中,往往每条边(道路)不仅仅需要考虑距离信息,还需要考虑方向信息、路口拥堵情况、车流量等等,因此自动驾驶中往往构建的为有向图、权重图等等。除此之外,合理地对自动驾驶场景下的地图进行分割也是保证规划效果的一个很重要的基础,不能分割太密集导致规划搜索的效率太低,也不能太粗略从而导致某些场景下明明存在可行解却无法搜索到。 构建完图之后,具体的规划过程其实就是一个搜索的过程,即如何在给定起点及终点的条件下快速搜索出一条满足期望的最优路径。在代码实现上,整个过程需要维护一个容器(container),具体的操作分为三个步骤:移除、扩展、塞入,以此不停循环,直至搜索到终点。下面介绍几种最常用的搜索算法。
搜索算法DFS & BFS
了解了图搜索的基础之后,接下来介绍两种最基础的搜索算法:深度优先搜索(DFS)和广度优先搜索(BFS)。深度优先顾名思义,从起点开始,按照某个顺序一条路走下去,直至不能再继续为止,然后回到上一节点,再换另一条路走下去;而广度优先则是每一步都扩展同一层的所有可能节点,一层一层扩展下去,直到某一层搜索到终点为止。可以看到深度优先搜索的过程是一条路走到底后,最后访问的节点最先拿来处理,整个过程可以用栈(stack)来表示,符合“后进先出”的原则;而广度优先搜索的过程是一层中先访问的节点拿来处理,可以用队列(queue)来表示,符合“先进先出”的原则。
那对于搜索算法来说,哪一种算法好一些呢?可以看下下面这张图,相同的场景下,BFS可以给出一条最短路径,而DFS虽然速度很快,但随机性很大,无法给出一条最优路径,这一缺陷使得我们不得不抛弃DFS,目前的主流基于图搜索的规划算法,原理其实都是基于BFS延伸出来的。
但是BFS其实也有一个很严重的问题,就是其遍历的无效节点过多,从而导致搜索效率太慢,上面左图中的深灰色格点就展示了在搜索过程中,所需要访问的节点,可以看出大多数的访问其实都是无用的,不能给最终的搜索提供任何帮助。针对这一缺陷,就引入了Heuristic Search(启发式搜索),即加入终点信息,从而使得搜索的目标更明确,避免过多的无效搜索。而基于这一改进提出的算法就是GBFS(Greedy Breath-First Search)。
BFS和DPS是根据先入或者后入的顺序来选择要处理的节点,之中不考虑任何终点相关的信息,而GBFS则是将与终点的距离考虑进来,构造一个规则来挑选依次要访问的节点。与终点的距离有多种形式,最常用的三种为Euclidean Distance、Manhattan Distance以及Diagonal Distance。
举个例子,在实现BFS算法时,上图中起点周围的8个邻居节点会一起存储进容器中,由于右上角的节点距离终点更近,因此再弹出时首先弹出该节点,基于该节点再进行扩展,从而加快了搜索效率。从下图中可以看出,算法过程中所访问的节点减少了很多,搜索的目标性更加明确,从而极大提升了搜索效率。
Dijkstra算法和A*算法
有了上面的基础,理解路径规划中的Dijkstra和A*算法就很容易了。Dijkstra算法其实BFS的进阶版,其可以用于处理带权重边的地图,因此更适合在实际场景中使用。在该算法中,通常采用优先队列(priority queue)来作为访问容器,这是由于优先队列(《key, value》这种形式)可以根据设定的key值自动进行排序,在Dijkstra中key值可以设定为和起点的距离,由于没考虑和终点的距离信息,因此还不能显示出优先队列的优势,但之后的A*算法里可以看出利用这种结构的方便性。Dijkstra算法的伪代码如下图所示:
A*算法和Dijkstra算法的唯一区别就在于优先队列中排序的依据不同,即key值不同。不同于Dijkstra,A*在存储节点时,还会考虑和终点的距离(可以类比GBFS之于BFS),其key值计算可以表示为:
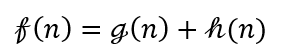
其中即为Heuristic Function,有了这个指向信息,A*算法可以更快地找到终点,避免了许多的无效搜索。其伪代码如下图所示:
这里我们可以看出优先队列的优势了,我们只需要每次计算的值并将其存储进优先队列,它就会自动根据其值进行排序,因此每次就可以取出容器的顶部值即为的最小值。在同一场景下,它们的实际效果如下图所示,可以看出由于A*避免了许多无效节点的访问,效率提升很多。 而这又引出了另一个问题,Dijkstra由于无差别的搜索可以保证最短路径,A*带有强指向型的搜索方式,能保证结果最优吗?这其实取决于A*的启发函数设定,为了保证最优性,需要保证启发函数是admissible的,即启发函数的值需要小于等于实际上该点到终点的距离。
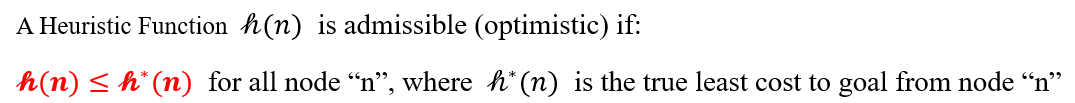
如果启发式函数是admissible的,那么A*的最终搜索结果就是最优的。其实这也很好理解,因为如果启发函数的选择实际上大于到终点的实际距离,那么依据该规则进行的排序搜索,必然会漏掉距离最短的那条路。因此如果我们需要A*给出最短路径的话,我们可以将启发函数设定为欧式距离或者对角距离,而不是曼哈顿距离。
以上就是基于图搜索的常用路径规划算法介绍,欢迎大家交流指正。
原文标题:技术|自动驾驶规划算法解析——图搜索篇
文章出处:【微信公众号:汽车工程师】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
#硬声创作季 LeTS-Drive:自动驾驶中不确定场景下的实时路径规划算法Mr_haohao 2022-10-12
-
UWB主动定位系统在自动驾驶中的应用实践2018-12-14 0
-
自动驾驶车辆中AI面临的挑战2021-02-22 0
-
你知道有哪几种常见的车辆路径规划算法吗?2021-06-17 0
-
基于路径跟踪方法的路径规划算法2017-12-04 1334
-
自动驾驶中避障动态路径规划2017-12-05 790
-
自动驾驶汽车四种常用的路径规划算法解析2020-03-08 17055
-
解析自动驾驶汽车路径规划算法2020-07-28 4857
-
水下航行器自主巡航的路径规划算法实现2021-04-09 978
-
A星路径规划算法完整代码资料汇总2021-12-03 725
-
自动驾驶之路径规划2023-06-01 295
-
自动驾驶决策规划算法第一章笔记2023-06-02 312
-
自动驾驶轨迹规划之路径规划总结2023-06-07 461
-
机器人基于搜索和基于采样的路径规划算法2023-10-13 373
-
机器人技术中常用的路径规划算法的开源库2023-10-21 1108
全部0条评论

快来发表一下你的评论吧 !
