

GPU引擎增强了超声检测到的大脑运动计算
描述
多普勒超声是一种医学超声模式,用于观察沿从超声探头发出的轴或在由这种探头扫描的平面区域中的运动。虽然多普勒超声通常用于检查血流,但也可用于检测组织微搏动。这种组织脉动源于低速血液灌注,它是周期性的,与每次心跳同步。研究人员报告了对亚微米级运动的敏感性。了解这些脑组织脉动可能有助于识别大脑中的出血或缺血(缺乏血流)。
测量组织位移
科学家经常使用换能器来发射和检测高频声波。向换能器内部的压电晶体施加高压发射脉冲,以产生短脉冲的超声波能量。当这种超声波脉冲在组织中传播时,它会遇到不同组织结构之间的界面。在这些交界处,超声波脉冲中的一些能量被反射为回波,而另一些则继续向组织深处传播。每个波分量的相对幅度是组织之间声阻抗失配程度的函数。具有相似成分的组织区域具有低程度的不匹配,因此允许更多的超声脉冲穿透更深。
在这项研究中,我们使用 2 MHz 超声波检查大脑。该频率低到足以穿透颅骨,但又高到足以提供容易检测到的来自血流和组织的回波。2 MHz 处的波长 ( λ ) 约为 0.8 mm,比我们观察到的组织运动大一个数量级以上。识别随时间的相位变化允许使用该波长在微米级检测组织运动。π 的相位变化导致通过多普勒样本体积λ /4 或约 0.2 mm 的位移。可以轻松完成分辨率为 π/1,000 的角度测量,从而获得一微米或以下的位移分辨率。
本应用中使用的系统以 2 MHz 的载波频率和以 6.25 kHz 的脉冲重复频率发射的八周期发射突发运行。发射突发大小导致大约 3 mm 的轴向分辨率(样本量)。轴向分辨率不应与上一段中讨论的位移计算的角分辨率相混淆。当超声脉冲在组织中传播时,它会跟踪散射体的运动。重要的是样本体积大小不能与独立移动的组织元素的大小不匹配;否则,多个移动组织元素可能导致净位移为零。此外,由于一组超声脉冲上的散射体去相关,小样本体积中的大组织偏移会产生不确定性。
每个脉冲重复周期的多普勒频移信号是通过放大接收到的回波并使用 16 位 A/D 转换器以 32 MSps 将其数字化,然后在现成的 DSP 卡(TigerSHARC 引擎)中解调和抽取来获得的。 因此,每个脉冲周期从 5,120 个回波样本开始,并转换为 320 个解调的 IQ 值,它们以 0.4 mm 的间隔均匀分布(即载波的λ/2)。然后将这 320 个 IQ 值重新采样为 64 个 IQ 样本,这些样本以 1.1 mm 的间隔将深度范围从 20 到 90 mm 分层。以这种方式,在每个门深度以 6.250 kHz 采样复数多普勒频移信号。
64 个门中每个门的局部大脑运动是在 MATLAB 中通过 Jacket 使用具有 Jacket 的 gsingle 数据类型的 NVIDIA GTX 280 显卡计算的。位移源自使用公式 1 计算的 IQ 信号的展开瞬时相位。公式 2 捕获了相位和位移之间的关系。

图 1 中所示的 16 个门跨越距离探头 20 到 90 mm 的范围,间隔为 4.5 mm。这些门是 64 个样本门的子集,每个都被处理成位移波形。图 1 中的所有位移波形共享一个共同的 x 轴,它以秒为单位表示时间。y 轴以微米为单位显示每条曲线的局部位移大小。
图 1:可以使用 2 MHz 超声波束检测随时间变化的大脑位移,并通过 Jacket 在 MATLAB 中进行计算。
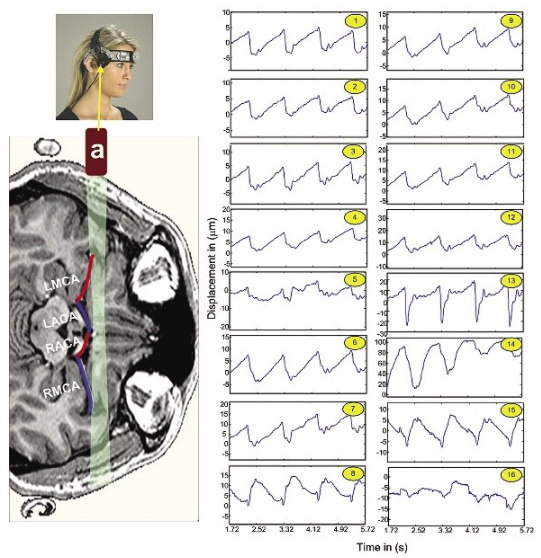
图 1 的左上角显示了 Marc 600 头架,其中装有传感器 (a),传感器 (a) 牢固地放置在大脑的时间声学窗口上。换能器显示在典型大脑的 MRI 图像旁边,其中重叠描绘了与超声波束路径相邻的主要前动脉路径。从威利斯环分支的动脉包括右大脑中动脉 (RMCA)、右大脑前动脉 (RACA)、左大脑前动脉 (LACA) 和左大脑中动脉 (LMCA)。右侧显示了距离探头 20 至 90 mm 处的多普勒门的位移波形(y 轴以微米为单位)与时间(x 轴以秒为单位)的关系。
这些大脑位移图具有很强的心脏周期存在。曲线还显示,在舒张末期和收缩峰值后不久测量的总偏移量的位移值低至 20 微米。(请注意,心脏在舒张期放松,而在收缩期泵血。)在每个心脏周期中,大脑通常从收缩期开始向一个方向移动,并从收缩期末开始向相反方向移动。查看任何给定时间的所有深度显示具有不同幅度的正位移值和负位移值,表明心脏周期中组织运动的异质性。
计算性能的基础
凭借 1 GB 的片上 RAM 和 240 个处理内核,本研究中使用的 GTX 280 GPU 能够处理 1,000 GFLOPS。对于这个应用程序,我们将数据划分为 64 个多普勒门,乘以 2 秒的数据矩阵,从而得到一个 64 x 12,800 个复杂数据值的输入矩阵。使用 MATLAB 在 CPU 和使用 Jacket 的 GPU 中计算位移(使用公式 1 和 2)进行比较。报告的时间测量值是 50 次试验的平均值。
平均而言,GPU 计算位移的时间为 51.50 毫秒,而 CPU 计算的时间为 621.5 毫秒。凭借其高度并行的架构,GPU 的性能比 CPU 高出 12 倍。梳理 GPU 时序测量进一步显示 CPU 和 GPU 之间的内存传输需要 41 毫秒(占总时间的 80%),而实际计算仅耗时 10.5 毫秒(占总时间的 20%)。
在使用 Jacket 和 GPU 技术取得积极成果后,我们预计该软件将为远远超过最先进的 DSP 性能的计算性能奠定基础。此功能对于实时处理作为深度函数的组织微脉动至关重要,这是我们研究的基本目标。我们还希望使用 Jacket 软件能够提高我们以高效方式设计和测试算法的能力,并有助于降低开发成本。
关于作者:
Asanka S. Dewaraja是 Spencer Technologies 的学生研究员。她的研究兴趣包括以超声波为重点的生物医学信号处理。她拥有华盛顿大学生物工程学士学位和硕士学位,目前正在攻读博士学位。
Travis M. Rothlisberger是 Spencer Technologies 的一名工程师。他的兴趣包括多普勒超声、嵌入式系统和可编程逻辑。他在华盛顿大学获得计算机工程学士学位。
Robert S. Giansiracusa是 Spencer Technologies 的一名工程师。他的兴趣包括信号处理和硬件设计。他获得了加州大学伯克利分校的电气工程学士学位和麻省理工学院的电气工程硕士学位。
Steven M. Swedenburg是 Spencer Technologies 的一名工程师。他拥有 30 多年的电子硬件设计工程师经验,曾为从车库初创公司到财富 500 强的公司工作。他的专长包括在动态市场中快速设计和实施尖端威廉希尔官方网站 和硬件。
Gene A. Saxon是 Spencer Technologies 的一名工程师。他的研究兴趣包括多普勒超声和图形用户界面。他在英国布里斯托大学获得机械工程学士学位/硕士学位,在华盛顿大学获得医学工程硕士学位。
Mark A. Moehring是 Spencer Technologies 的产品开发副总裁。他的兴趣包括随机信号处理的生物医学应用,重点是使用超声波进行生理测量。他在哈维穆德学院获得物理学学士学位,在华盛顿大学获得电气工程硕士学位和博士学位。他是 IEEE 医学和生物学工程学会西雅图分会的主席。
审核编辑:郭婷
-
ADXL345无法检测到落体运动如何解决?2023-12-29 0
-
《CST Studio Suite 2024 GPU加速计算指南》2024-12-16 0
-
超声波检测小管径2015-12-14 0
-
GPU2016-01-16 0
-
有没有什么传感器能检测到空间物体的运动?2017-10-27 0
-
程序员的大脑有什么不同?2018-10-25 0
-
威廉希尔官方网站 增强了开关组件中的隔离2019-05-30 0
-
为什么减压器降低了电压却增强了电流?2019-06-17 0
-
基于GPU的并行化运动目标检测方法的研究2017-11-15 662
-
一种实时运动目标检测与跟踪算法2017-12-12 793
-
基于SIFT特征匹配的运动目标检测及跟踪方法2018-01-09 1427
-
分享一个超声波运动检测器威廉希尔官方网站2022-07-02 2561
-
GPU引擎增强了超声检测到的大脑运动计算2022-10-26 467
-
超声波运动检测器的威廉希尔官方网站 图分享2023-03-19 3653
-
GPU:量化理论计算的新引擎2024-04-16 475
全部0条评论

快来发表一下你的评论吧 !
