

DPU软件栈五层模型系列(一)DPU异构计算架构五层开发模型
描述
一般说来,异构计算的核心目的是解决特定应用场景下算力不足的问题,并且大幅度提升整体系统的计算性能。在整体架构上,它的分层逻辑从应用场景出发,通过上层的需求来定义下层的功能,而每一层是对特定功能的抽象与封装。在定义每一层功能时,要达到以下几个目标:
各层职责单一
层间边界清晰
层内功能实现独立
灵活易扩展
基于上述目标,将一个异构计算的系统抽象为五层(如下图所示),自下而上分别是:1)DSA设备层(DSA Device Layer),2)DSA操作层 (DSA Operating Layer),3)计算引擎层(Scheduling Operating Layer),4)应用服务层(Application Service Layer)和5)业务开发层 (Business Development Layer),详述如下。
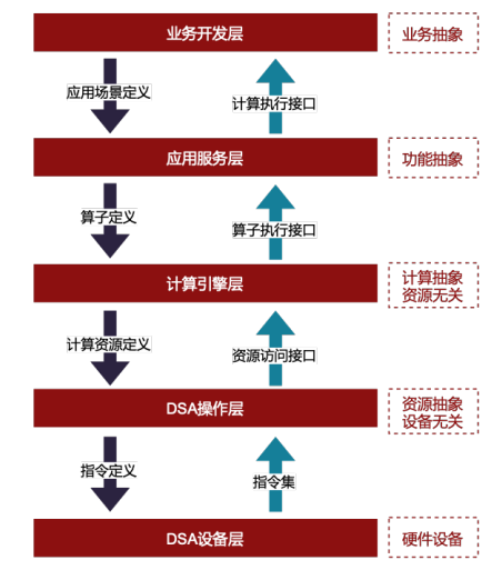 图 异构计算系统抽象模型
图 异构计算系统抽象模型一、DSA设备层
DSA设备层代表的是执行异构计算的DSA处理器以及集成了该处理器的硬件设备,例如,以DPU或GPU为处理器的异构计算设备。异构计算设备需要具备以下两个核心能力:1)提供支持专用计算操作的指令集(Instruction Set),2)CPU或其他DSA设备的标准通信接口,如PCIe数据传输标准。
二、DSA操作层
DSA操作层是对DSA处理器的指令集的管理以及基础开发平台的整合,该层完成了对硬件资源的抽象,从而使上层软件对底层设备透明;DSA操作层是对DSA设备层计算设备的抽象和计算资源的封装,是软件与硬件、逻辑与物理的边界。它基于如DPU芯片等DSA处理器提供的指令集,以更加抽象和编程友好的方式对上层提供了异构计算开发和访问的软件接口、以及设备监控管理的接口。该层内部有四个必要的模块,分别是设备驱动器,指令集管理器,资源访问接口,开发和管理平台。
- 设备驱动器:设备驱动器是硬件设备的软件抽象,它基于操作系统标准的驱动框架及PCIe协议,实现了对计算设备的物理访问,主要包括设备处理器的指令执行和设备存储的读写。
- 指令集管理器:指令管理器的作用是对计算设备所提供的指令集进行统一管理,通过对指令集的封装及组合,提供更加友好的编程接口。
- 资源访问接口:基于设备驱动器和指令集管理器的功能,该模块完成对整个计算资源访问的抽象和封装,它以编程接口的方式对上层提供资源访问入口,服务于上层计算逻辑和控制逻辑的执行。
- 开发和管理平台:除了上述运行时所需的能力外,还需要针对开发人员提供友好的编程工具,如指令集编译工具、监控管理工具、日志工具、异构计算卡模拟器等。
三、计算引擎层
计算引擎层是对计算逻辑的封装,为上层提供通用的计算能力。与DSA操作层的对计算资源封装不同,计算引擎层是对计算逻辑的封装,它基于DSA操作层提供的资源访问接口,根据上层应用层软件对算力的需求,提供了可复用的算子集合及执行接口。
算子抽象
算子定义为实现某一特定功能或算法的函数或独立的服务,它是对计算逻辑的抽象。例如,根据指定条件对数据进行过滤的函数可以是一个算子,称它为“过滤算子”。在标准的数据库软件中,它的算子有Scan, Join, GroupBy等,而在网络处理软件中,特有的算子会是以BSD Socket,NVMe等标准服务的形式呈现。由于异构计算的“异构”特性,每个算子在不同设备上的具体实现有所不同,所以针对每一个支持的算子,都要有多种不同设备平台上的实现,如ScanOnDPU、ScanOnGPU。
计算优化器
异构计算追求的是计算性能的提升,相应的需要一个计算优化器来对上层的计算请求做优化。它的基本策略是根据应用场景、上下文、数据规模等因素来动态的选择最优的算子实现进行计算。
四、应用服务层
应用服务层是数据处理的应用服务软件,也是算力的需求侧。应用服务层代表具有通用功能的软件系统,这些软件系统可以利用计算引擎提供的算子进行异构计算,从而达到计算性能提升的目的。常见的应用层软件系统有分布式计算领域的Spark, Flink, Hadoop;数据库领域的PostgreSQL, MySQL;分布式网络中的gPRC,Network Gateway,Nginx;以及存储服务中的Ceph等等,基本上通用服务型的系统都属于该层的范畴。
在实际开发中,针对应用服务层中的软件,需要解决以下几个关键问题:
- 性能瓶颈的识别:通常应用软件的性能瓶颈会在高并发、大吞吐的情况下出现,这些瓶颈一般源于CPU计算资源的竞争、CPU计算性能的不足、网络传输的延迟以及磁盘I/O的延迟等。识别出应用软件的性能瓶颈是算力卸载的第一步。
- 异构计算的有效性边界:在定位到软件的性能瓶颈后,需要从中识别出哪些是可以通过异构计算来解决的。通常,CPU成为瓶颈的原因会有两类,一类是算力的问题,另一类是算法的问题。针对算力的问题,可以通过异构计算来解决,而算法的问题则不然。
- 算子的高效调用: 算子是异构计算的执行单元,只有把算子集成到应用软件的执行路径中,算力卸载才算完成。考虑到性能的优化,还需要根据实际情况优化算子的执行策略,例如,数据在主机端与设备端内存之间的数据拷贝策略、各算子执行序列的编排策略等等。
- 应用软件的向前兼容性:在整合应用软件与异构计算的算子时,要确保应用软件的向前兼容性,以保证应用服务层的软件迭代对正在运行的上层业务系统是透明的,从而提高整个架构的稳定性与可维护性。
五、业务开发层
业务开发层是在某特定领域的业务系统。业务开发层是最贴近实际业务场景的软件系统,通常它是针对某个特定行业的具体业务需求定制的软件系统,如金融行业的交易系统,互联网行业的数据分析系统等等。整个异构计算架构本质上就是解决业务层的性能瓶颈问题,所以在实际开发过程中,应该从业务端出发,寻找要解决的根本问题,然后驱动整个异构系统的构建。同时,整体架构也要保证底层构建对具体的业务系统完全透明,达到对各行业业务软件系统的无缝支撑和业务逻辑开发的隔离。
- 相关推荐
- DPU
-
《数据处理器:DPU编程入门》DPU计算入门书籍测评2023-12-24 0
-
异构计算的前世今生2021-12-26 0
-
业内首部白皮书《DPU技术白皮书》——中科院计算所主编2022-03-14 0
-
专⽤数据处理器 (DPU) 技术⽩⽪书2022-03-14 0
-
请问模型推理只用到了kpu吗?可以cpu,kpu,fft异构计算吗?2023-09-14 0
-
【KV260视觉入门套件试用体验】部署DPU镜像并开发一个图像识别程序2023-09-18 0
-
【书籍评测活动NO.23】数据处理器:DPU编程入门2023-10-24 0
-
什么是DPU?2023-11-03 0
-
异构计算:架构与技术2018-09-18 862
-
异构计算发展趋势的助力2021-10-27 2466
-
什么是DPU 未来的DPU智能⽹卡硬件形态2021-11-02 7000
-
PrimeSimSPICE:异构计算模型实现数量级性能突破2023-05-24 947
-
DPU 技术发展概况系列(一)什么是DPU2022-03-24 1323
-
DPU 技术发展概况系列(三) DPU的发展背景2022-04-06 901
-
DPU软件栈五层模型(二)典型软件框架案例2022-06-13 1703
全部0条评论

快来发表一下你的评论吧 !
