

如何在英特尔® 平台上实现高效的大语言模型训练后量化
描述
本文介绍了可提升大语言模型的训练后量化表现的增强型 SmoothQuant 技术,说明了这项技术的用法,并证明了其在准确率方面的优势。此方法已整合至英特尔 Neural Compressor 1 中。英特尔 Neural Compressor 是一个包含量化、剪枝(稀疏性)、蒸馏(知识提炼)和神经架构搜索等多种常用模型压缩技术的开源 Python 库。目前,诸如 TensorFlow、英特尔 Extension for TensorFlow2、PyTorch、英特尔 Extension for PyTorch3、ONNX Runtime 和 MXNet等主流框架,都能与之兼容。
英特尔 Neural Compressor 已经支持多款英特尔 架构的硬件,比如英特尔 至强 可扩展处理器4、英特尔 至强 CPU Max 系列5、英特尔 数据中心 GPU Flex 系列6和英特尔 数据中心 GPU Max 系列7。本文涉及的实验基于第四代英特 至强 可扩展处理器8 进行。
 大语言模型
大语言模型
大语言模型 (Large Language Model, LLM) 需基于海量数据集进行训练,可能拥有数十亿权重参数。其先进的网络结构和庞大的参数量,使它们能够很好地应对自然语言本身的复杂性。完成训练后的大语言模型,可针对各种下游的自然语言处理 (NLP) 和自然语言生成 (NLG) 任务进行调优,让其更适合对话式聊天机器人(如 ChatGPT)、机器翻译、文本分类、欺诈检测和情感分析等任务场景。
大语言模型部署面临的挑战
大语言模型在执行自然语言处理和自然语言生成任务方面表现出色,但其训练和部署颇为复杂,主要面临以下挑战:
AI 与内存墙9 瓶颈问题:算力每两年提高 3.1 倍,内存带宽却只提高 1.4 倍;
网络带宽挑战:训练大语言模型需要采用分布式系统,这对网络带宽提出了较高要求;
系统资源有限:训练后的模型往往会部署在算力和内存资源均有限的系统上。
因此,采用训练后量化的方法来为大语言模型瘦身,对于实现低时延推理至关重要。
大语言模型的量化
量化是一种常见的压缩操作,可以减少模型占用的内存空间,提高推理性能。采用量化方法可以降低大语言模型部署的难度。具体来说,量化是将浮点矩阵转换为整数矩阵:
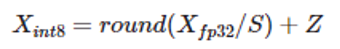
其中 X_fp32、S 和 Z 分别为输入矩阵、比例因子和整数零点。 有关每通道 (per-channel) 量化策略虽然可能会减少量化损失,但不能用于激活值量化的原因,请参看 SmoothQuant 相关文档10 。不过,激活值量化误差损失却是导致模型量化准确率下降的重要因素。为此,人们提出了很多方法来降低激活值量化损失,例如:SPIQ11 、Outlier Suppression12 和 SmoothQuant13 。这三种方法思路相似,即把激活值量化的难度转移到权重量化上,只是三者在转移难度的多少上有所不同。
增强型 SmoothQuant
SmoothQuant 引入了一个超参数 α 作为平滑因子来计算每个通道的量化比例因子,并平衡激活值和权重的量化难度。
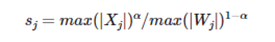
其中 j 是输入通道索引。
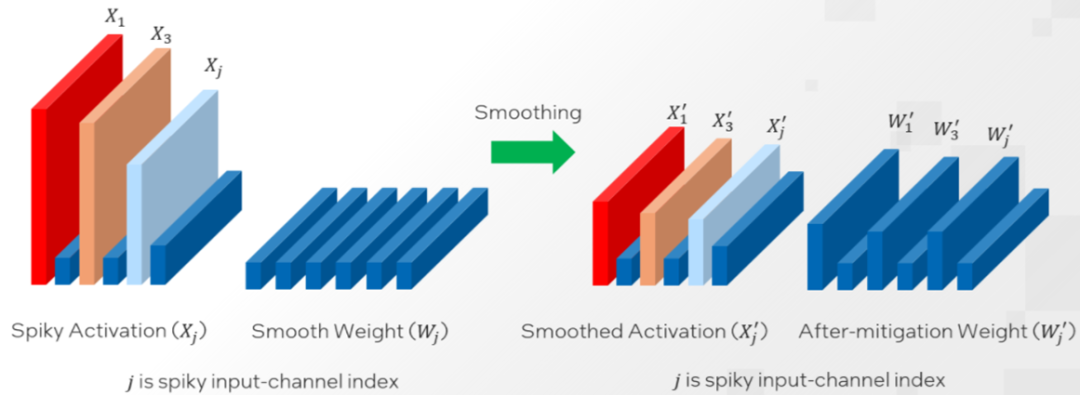
对于OPT 和 BLOOM 等大多数模型来说,α=0.5 是一个能够较好实现权重和激活值量化难度分割的平衡值。模型的激活异常值越大,就越需要使用更大的 α 值来将更多的量化难度转移到权重上。 原始的 SmoothQuant 旨在通过针对整个模型使用一个固定值 α 来分割权重和激活值的量化难度。然而,由于激活异常值的分布不仅在不同模型之间存在差异,而且在同一模型的不同层之间也不尽相同,因此,本文推荐使用英特尔 Neural Compressor 的自动调优能力,逐层获取最佳 α 值。
相关方法包括以下五个主要步骤(伪代码如下所示):
-
通过特殊的回调函数 register_forward_hook 捕获 (hook) 模型各层的输入和输出值。
-
根据用户定义的 α 范围和步长生成一个 α 值列表。
-
根据给定的 α 值重新计算平滑因子并调整参数(权重值和激活值)。
-
对权重执行每通道量化与反量化 (quantization_dequantization),对输入值执行每张量 (per-tensor) 量化与反量化,以预测与给定 α 值对应的每层输出值。
-
计算相对实际输出值的均方损失,将调整后的参数恢复回来,并保存每层的最佳 α 值。

本文提出的方法支持用多个标准(如最小值、最大值和平均值)来确定 Transformer 块的输入层归一化 (LayerNorm) 操作的 α 值。实验发现,将 α 范围设为 [0.3, 0.7],步长设为 0.05,对大多数模型来说都能达到很好的平衡。 这一方法有两个显著特点:一是全自动化,二是比原始方法支持的融合模式多。 下图提供了在 BLOOM-1b7 模型上执行 SmoothQuant α 值自动调优的样例代码:
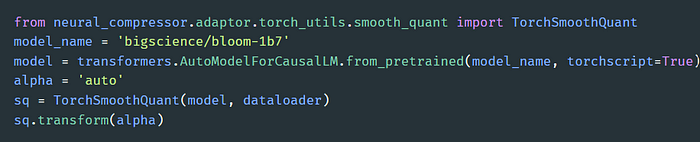
启用增强型 SmoothQuant 的样例代码
用户只需传递一个模型名称 (model_name) 和一个数据加载器。值得注意的是,模型分析主要依靠的是 Torch JIT。用户可以在加载Hugging Face 模型14 时将 torchscript 设置为 True,或将 return_dict 设置为 False。更多信息请参阅英特尔 Neural Compressor 文档10 。
结果
本文提出的增强型 SmoothQuant 的主要优势在于提高了准确率。 经过对多种主流大语言模型的评估,具备自动调优能力的 INT8 SmoothQuant 最后一个词元 (last-token) 的预测准确率要高于原始 INT8 SmoothQuant 和 FP32 基线方法。详见下图: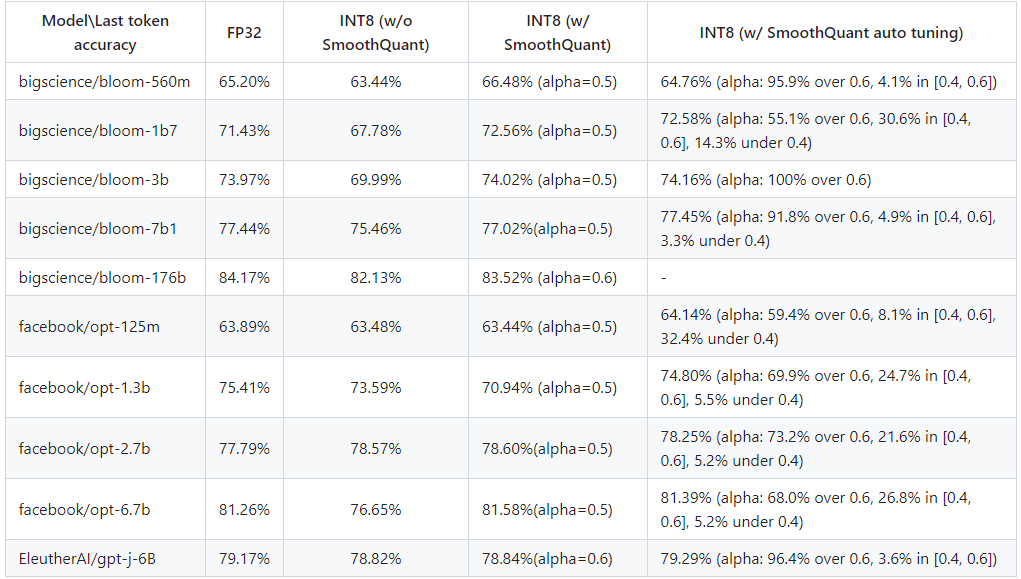
FP32 基线方法、INT8(启用和不启用 SmoothQuant)以及 INT8(启用本文提出的增强型 SmoothQuant)的准确率对比
从上图可以看出,在 OPT-1.3b 和 BLOOM-1b7 模型上,本文提出的增强型 SmoothQuant 的准确率比默认的 SmoothQuant 分别高 5.4% 和 1.6%。量化后的模型也缩小到 FP32 模型的四分之一,大大减少了内存占用空间,从而有效地提升大模型在英特尔 平台上的推理性能。 更全面的结果请见 GitHub 存储库10 。同时,也欢迎您创建拉取请求或就 GitHub 问题15 发表评论。期待听到您的反馈意见和建议。 作者
他们都在从事模型量化
及压缩的研究与优化工作
注释:
本文主要介绍在英特尔平台上提升大语言模型的训练后量化表现的增强型SmoothQuant技术,说明了这项技术的用法,并证明了其在准确率方面的优势。 本文中列出的链接和资源。需要说明的是,将SmoothQuant适配到英特尔平台并实现它在英特尔平台上的增强,是英特尔的原创。1. 英特尔 Neural Compressor
https://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/neural-compressor.html2. 英特尔 Extension for TensorFlowhttps://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/optimization-for-tensorflow.html3. 英特尔 Extension for PyTorchhttps://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/optimization-for-pytorch.html4. 英特尔 至强 可扩展处理器https://www.intel.cn/content/www/cn/zh/products/details/processors/xeon/scalable.html5. 英特尔 至强 CPU Max 系列https://www.intel.cn/content/www/cn/zh/products/details/processors/xeon/max-series.html6. 英特尔 数据中心 GPU Flex 系列https://www.intel.cn/content/www/cn/zh/products/details/discrete-gpus/data-center-gpu/flex-series.html7. 英特尔 数据中心 GPU Max 系列https://www.intel.com/content/www/us/en/products/details/discrete-gpus/data-center-gpu/max-series.html8. 第四代英特尔 至强 可扩展处理器https://www.intel.cn/content/www/cn/zh/events/accelerate-with-xeon.html9. AI 与内存墙https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b810. SmoothQuant 相关文档 / 英特尔 Neural Compressor 文档 / GitHub 存储库https://github.com/intel/neural-compressor/blob/master/docs/source/smooth_quant.md11. SPIQhttps://arxiv.org/abs/2203.1464212. Outlier Suppressionhttps://arxiv.org/abs/2209.1332513. SmoothQuanthttps://arxiv.org/abs/2211.1043814. Hugging Face 模型https://huggingface.co/models15. GitHub 问题https://github.com/intel/neural-compressor/issues-
#高通 #英特尔 #Elite 高通X Elite芯片或终结苹果、英特尔的芯片王朝深圳市浮思特科技有限公司 2023-10-27
-
英特尔多款平板电脑CPU将于明年推出2013-12-19 0
-
OpenCL平台和英特尔Stratix 10 FPGA的结合使用2019-07-17 0
-
为什么选择加入英特尔?2019-07-25 0
-
适用于英特尔性能设备平台的RMC2019-08-20 0
-
苹果Mac弃用英特尔芯片的原因2020-06-23 0
-
英特尔重点发布oneAPI v1.0,异构编程器到底是什么2020-10-26 0
-
英特尔Context Sensing SDK跨平台上下文感知体验2018-11-07 3487
-
由Gayathri Murali设计英特尔平台上的Android2020-05-31 2293
-
英特尔百度携手研发Nervana神经网络训练处理器 极速训练深度学习2019-07-05 959
-
英特尔正式面向中国市场推出第11代英特尔vPro平台2021-03-19 2493
-
英特尔平台固件恢复设计的代码公布2021-05-20 2457
-
英特尔四大层面,提升DeepRec训练和推理能力2022-07-10 1099
-
使用PyTorch在英特尔独立显卡上训练模型2024-11-01 445
-
使用英特尔AI PC为YOLO模型训练加速2024-12-09 298
全部0条评论

快来发表一下你的评论吧 !
