

基于视觉的机器人抓取系统设计
描述
作者 | ljc_coder @CSDN
0导读
抓取综合方法是机器人抓取问题的核心,本文从抓取检测、视觉伺服和动态抓取等角度进行讨论,提出了多种抓取方法。各位对机器人识别抓取感兴趣的小伙伴,一定要来看一看!千万别错过~
1引言
找到理想抓取配置的抓取假设的子集包括:机器人将执行的任务类型、目标物体的特征、关于物体的先验知识类型、机械爪类型,以及最后的抓取合成。
注:从本文中可以学习到视觉伺服的相关内容,用于对动态目标的跟踪抓取或自动调整观察姿态。因为观察的角度不同,预测的抓取框位置也不同:抓取物品离相机位置越近,抓取预测越准。
1.1 抓取综合方法
抓取综合方法是机器人抓取问题的核心,因为它涉及到在物体中寻找最佳抓取点的任务。这些是夹持器必须与物体接触的点,以确保外力的作用不会导致物体不稳定,并满足一组抓取任务的相关标准。
抓取综合方法通常可分为分析法和基于数据的方法。
分析法是指使用具有特定动力学行为的灵巧且稳定的多指手构造力闭合
基于数据的方法指建立在按某种标准的条件下,对抓取候选对象的搜索和对象分类的基础上。(这一过程往往需要一些先验经验)
1.2 基于视觉的机器人抓取系统
基于视觉的机器人抓取系统一般由四个主要步骤组成,即目标物体定位、物体姿态估计、抓取检测(合成)和抓取规划。
一个基于卷积神经网络的系统,一般可以同时执行前三个步骤,该系统接收对象的图像作为输入,并预测抓取矩形作为输出。
而抓取规划阶段,即机械手找到目标的最佳路径。它应该能够适应工作空间的变化,并考虑动态对象,使用视觉反馈。
目前大多数机器人抓取任务的方法执行一次性抓取检测,无法响应环境的变化。因此,在抓取系统中插入视觉反馈是可取的,因为它使抓取系统对感知噪声、物体运动和运动学误差具有鲁棒性。
2抓取检测、视觉伺服和动态抓取
抓取计划分两步执行:
首先作为一个视觉伺服控制器,以反应性地适应对象姿势的变化。
其次,作为机器人逆运动学的一个内部问题,除了与奇异性相关的限制外,机器人对物体的运动没有任何限制。
2.1 抓取检测
早期的抓取检测方法一般为分析法,依赖于被抓取物体的几何结构,在执行时间和力估计方面存在许多问题。
此外,它们在许多方面都不同于基于数据的方法。
基于数据的方法:Jiang、Moseson和Saxena等人仅使用图像,从五个维度提出了机器人抓取器闭合前的位置和方向表示。
如下图,该五维表示足以对抓取姿势的七维表示进行编码[16],因为假定图像平面的法线近似。因此,三维方向仅由 给出。
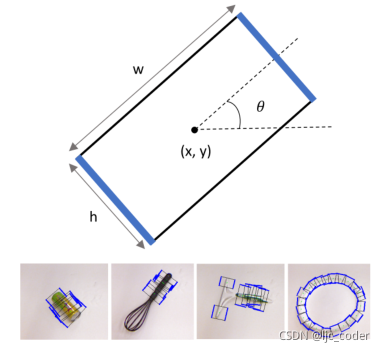
本文的工作重点是开发一种简单高效的CNN,用于预测抓取矩形。
在训练和测试步骤中,所提出的网络足够轻,可以联合应用第二个CNN,解决视觉伺服控制任务。因此,整个系统可以在机器人应用中实时执行,而不会降低两项任务的精度。
2.2 视觉伺服控制
经典的视觉伺服(VS)策略要求提取视觉特征作为控制律的输入。我们必须正确选择这些特征,因为控制的鲁棒性与此选择直接相关。
最新的VS技术探索了深度学习算法,以同时克服特征提取和跟踪、泛化、系统的先验知识以及在某些情况下处理时间等问题。
Zhang等人开发了第一项工作,证明了在没有任何配置先验知识的情况下,从原始像素图像生成控制器的可能性。作者使用Deep Q-Network ,通过深度视觉运动策略控制机器人的3个关节,执行到达目标的任务。训练是在模拟中进行的,没有遇到真实的图像。
遵循强化学习方法的工作使用确定性策略梯度设计新的基于图像的VS或Fuzzy Q-Learning,依靠特征提取,控制多转子空中机器人。
在另一种方法中,一些研究视觉伺服深度学习的工作是通过卷积神经网络进行的。CNN的泛化能力优于RL,因为RL学习的参数是特定于环境和任务的。
本文设计了四种卷积神经网络模型作为端到端视觉伺服控制器的潜在候选。网络不使用参考图像和当前图像以外的任何类型的附加信息来回归控制信号。
因此,所提出的网络作为实际上的控制器工作,预测速度信号,而不是相对姿态。
2.3 动态抓取
学习感知行为的视觉表征,遵循反应范式,直接从感觉输入生成控制信号,无需高级推理,有助于动态抓取。
强化学习方法适用于特定类型的对象,并且仍然依赖于某种先验知识,因此,最近大量研究探索了将深度学习作为解决闭环抓取问题的方法。
Levine等人提出了一种基于两个组件的抓取系统。第一部分是预测CNN,其接收图像和运动命令作为输入,并输出通过执行这样的命令,所产生的抓取将是令人满意的概率。第二个部分是视觉伺服功能。这将使用预测CNN来选择将持续控制机器人成功抓取的命令。这称为是深度强化学习,需要很久的训练时间。
2019年,Morrison, Corke 和 Leitner 开发了一种闭环抓取系统,在这种系统中,抓取检测和视觉伺服不是同时学习的。作者使用完全CNN获取抓取点,并应用基于位置的视觉伺服,使抓取器的姿势与预测的抓取姿势相匹配。
3本文实现的方法
VS的目的是通过将相机连续获得的图像与参考图像进行比较,引导操纵器到达机器人能够完全看到物体的位置,从而满足抓取检测条件。因此,该方法的应用涵盖了所有情况,其中机器人操作器(相机安装在手眼模式下)必须跟踪和抓取对象。
该系统包括三个阶段:设计阶段、测试阶段和运行阶段。第一个是基于CNN架构的设计和训练,以及数据集的收集和处理。在第二阶段,使用验证集获得离线结果,并根据其准确性、速度和应用领域进行评估。第三阶段涉及在机器人上测试经过训练的网络,以评估其在实时和现实应用中的充分性。
在运行阶段,系统运行的要求是事先获得目标对象的图像,该图像将被VS用作设定点。只要控制信号的L1范数大于某个阈值,则执行控制回路。
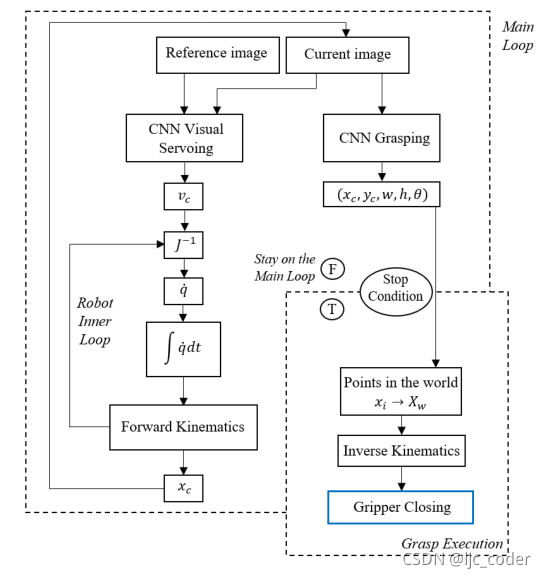
单个参考图像作为视觉伺服CNN的输入之一呈现给系统。相机当前获取的图像作为该网络的第二个输入,并作为抓取CNN的输入。这两个网络都连续运行,因为抓取CNN实时预测矩形以进行监控,VS网络执行机器人姿势的实时控制。
VS CNN预测一个速度信号,该信号乘以比例增益 ,以应用于相机中。机器人的内部控制器寻找保证相机中预测速度的关节速度。在每次循环执行时,根据机器人的当前位置更新当前图像,只要控制信号不收敛,该循环就会重复。
当满足停止条件时,抓取网络的预测映射到世界坐标系。机器人通过逆运动学得到并到达预测点,然后关闭夹持器。
3.1 网络体系结构
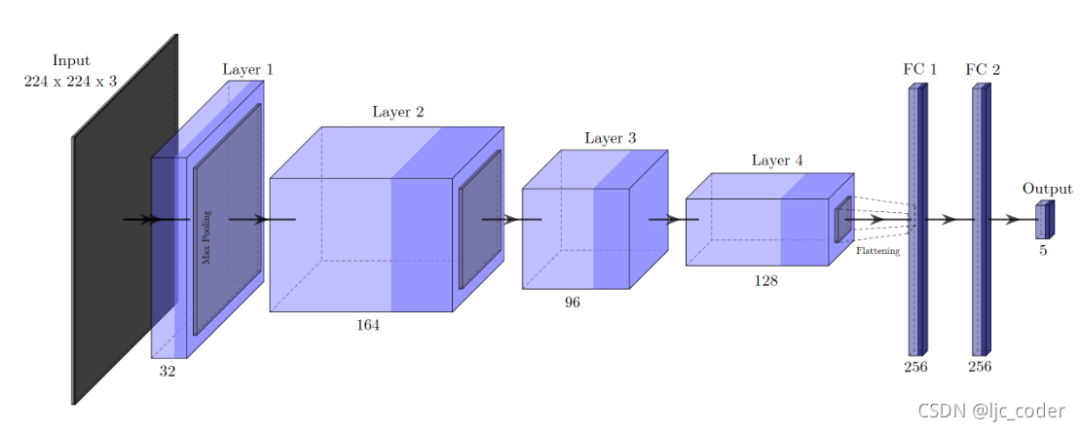
该卷积网络架构被用于抓取检测。网络接收224×224×3的RGB图像作为输入,无深度信息。
layer 1 由32个3×3卷积组成,layer 2 包含164个卷积。在这两种情况下,卷积运算都是通过步长2和零填充(zero-padding)执行的,然后是批标准化(batch normalization)和2×2最大池化。layer 3 包含96个卷积,其中卷积使用步长1和零填充执行,然后仅执行批标准化。layer 4 ,也是最后一层,卷积层由128个卷积组成,以步长1执行,然后是2×2最大池化。
在最后一层卷积之后,生成的特征映射在包含4608个元素的一维向量中被展开,进一步传递到两个全连接(FC)层,每个层有256个神经元。在这些层次之间,训练期间考虑50%的dropout rate。
最后,输出层由5个神经元组成,对应于编码抓取矩形的** 值。在所有层中,使用的激活函数都是ReLU**,但在输出层中使用线性函数的情况除外。
3.2 Cornell 抓取数据集
为了对数据集真值进行编码,使用四个顶点的 和 坐标编译抓取矩形。
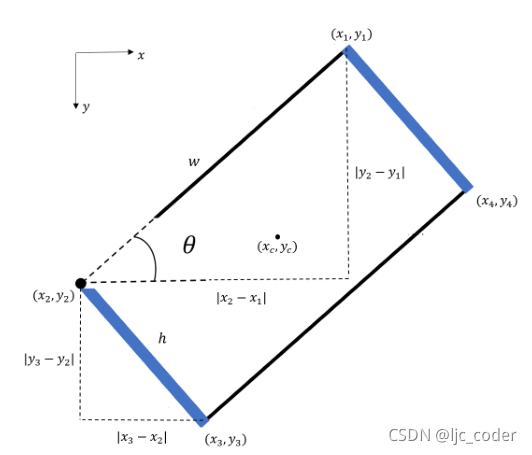
和 参数分别表示矩形中心点的 和 坐标,可从以下公式获得:

计算夹持器开口 和高度 ,同样根据四个顶点计算:
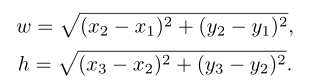
最后,表示夹持器相对于水平轴方向的 由下式给出:
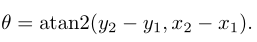
3.3 结果评估
预测矩形( )和真值矩形( )之间的角度差 必须在30度以内。
雅卡尔指数(交并比)需要大于0.25,而不是像一般那样“达到0.25即可”。
3.4 视觉伺服网络体系结构
与抓取不同,设计用于执行机械手视觉伺服控制的网络接收两个图像作为输入,并且必须回归六个值,考虑到线性和角度相机速度。
这些值也可以分为两个输出,共有四个模型处理VS任务。
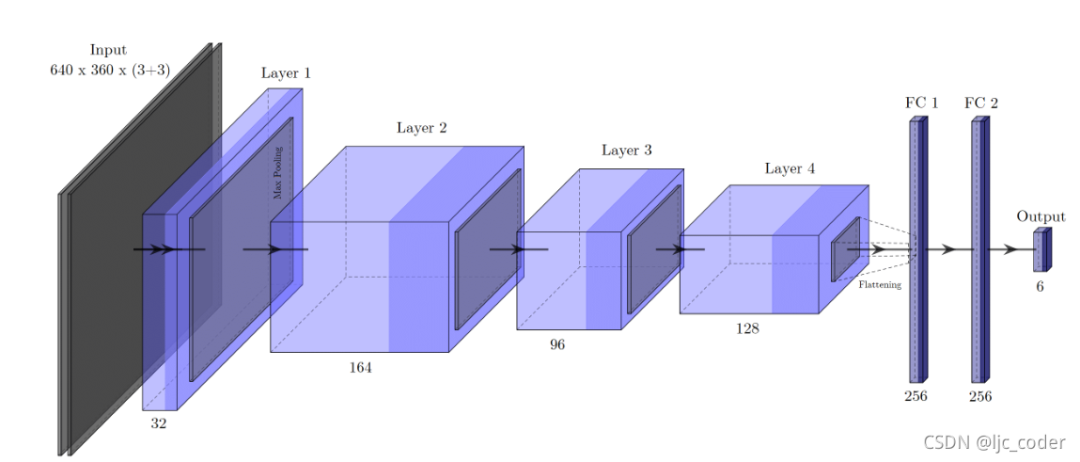
模型1-直接回归(最终实验效果最佳)。它基本上与抓取网络相同,除了在第三卷积层中包含最大池化和不同的输入维度,这导致特征图上的比例差异相同。
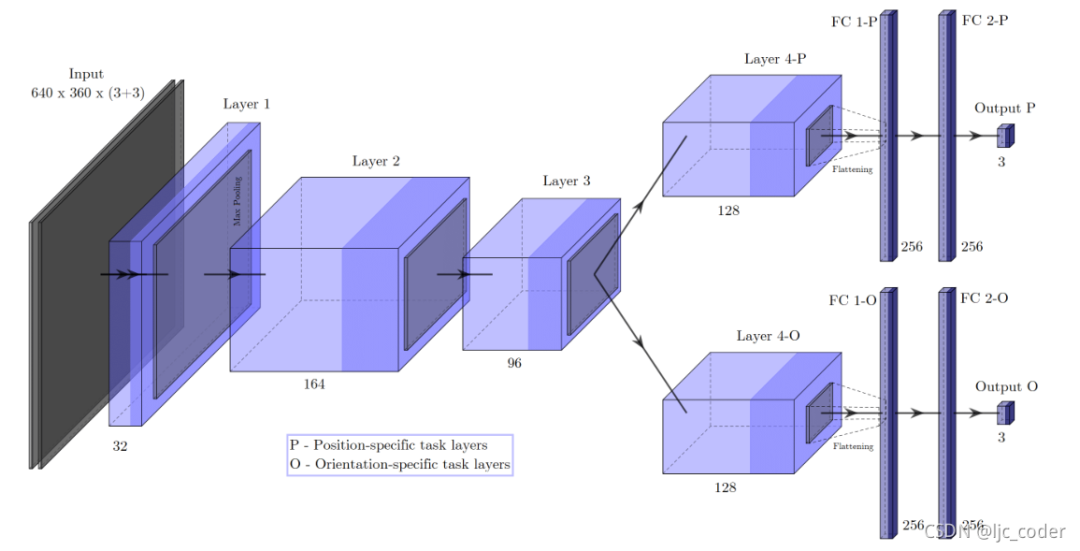
模型2-任务特定回归。网络输入被串联,第三组特征图由两个独立的层序列处理(多任务网络)。因此,网络以两个3D矢量的形式预测6D速度矢量。具体来说,该结构由一个共享编码器和两个特定解码器组成 - 一个用于线速度,另一个用于角速度。
模型3-串联特征的直接回归和模型4-相关特征的直接回归,两个模型的结构类似,通过关联运算符( )区分。
模型3简单连接;模型4使用相关层。
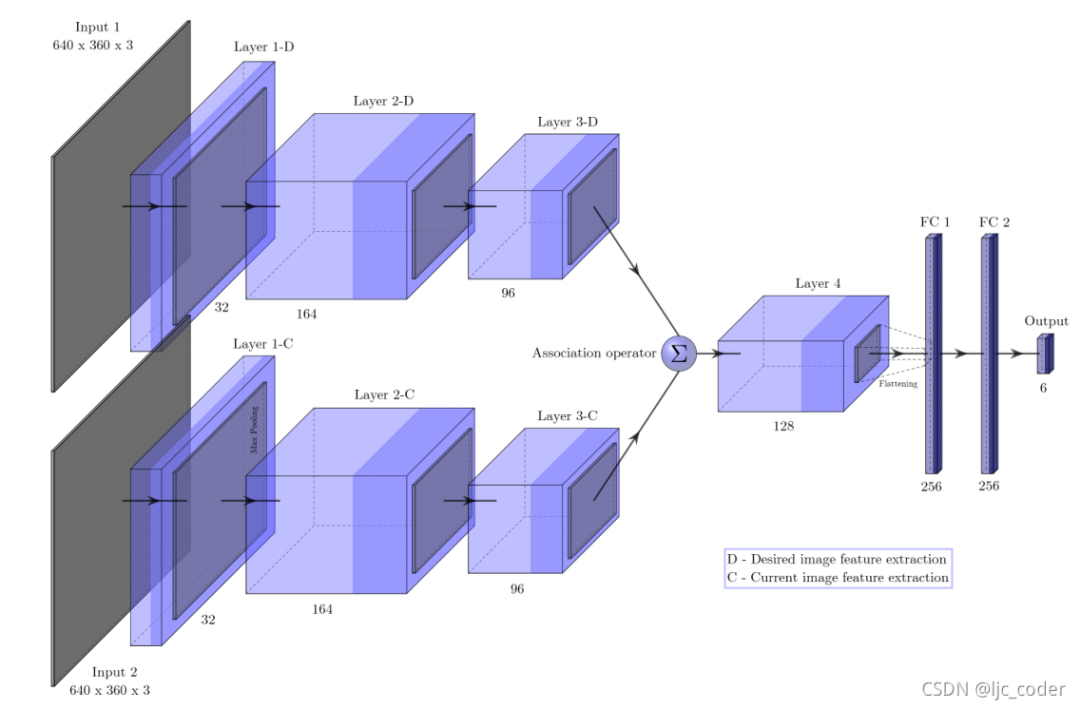
模型3简单地由第三个卷积层产生的特征映射连接,因此第四个层的输入深度是原来的两倍。而模型4有一个相关层,帮助网络找到每个图像的特征表示之间的对应关系。原始相关层是flow network FlowNet的结构单元。
3.5 VS数据集
该数据集能够有效地捕获机器人操作环境的属性,具有足够的多样性,以确保泛化。
机器人以参考姿态为中心的高斯分布的不同姿态,具有不同的标准偏差(SD)。
下表为参考姿势(分布的平均值)和机器人假设的标准偏差集(SD)。
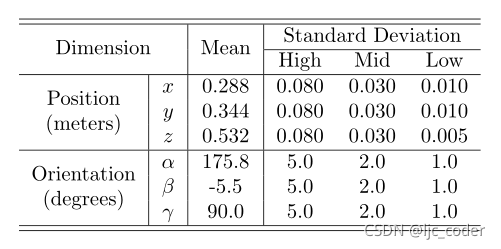
SD选择考虑了机器人在VS期间必须执行的预期位移值。
从高SD获得的图像有助于网络了解机器人产生大位移时图像空间中产生的变化。
当参考图像和当前图像非常接近时,从低SD获得的实例能够减少参考图像和当前图像之间的误差,从而在稳态下获得良好的精度。
平均SD值有助于网络在大部分VS执行期间进行预测。
获得数据后,数据集以** 的形式构造,其中图像为I**,** **是拍摄该图像时对应的相机姿态。
为泰特-布莱恩角内旋(按照 变换)
已处理数据集的每个实例都采用( )表示。 是选择作为所需图像的随机实例; 选择另一个实例作为当前图像; 是二者的变换。
通过齐次变换矩阵形式表示每个姿势(由平移和欧拉角表示)来实现( 和 ),然后获得
最后,对于实际上是控制器的网络,其目的是其预测相机的速度信号,即:E控制信号。 被转化为
是比例相机速度。由于在确定标记比例速度时不考虑 增益,因此使用了周期性项,并且在控制执行期间必须对 增益进行后验调整。
速度 由 表示:
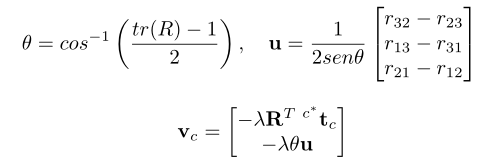
其中, 是旋转矩阵;** **同一矩阵第i行和第j列的元素; 是与当前相机位置到期望相机位置的平移向量; 是比例增益(初始设置为1)。
总市值达到了67.05亿元
-
机器人视觉——机器人的“眼睛”2015-01-23 0
-
机器人与CCD2017-08-18 0
-
【MYD-CZU3EG开发板试用申请】基于机器视觉的工业机器人抓取工作站2019-09-18 0
-
【瑞芯微RK1808计算棒试用申请】基于机器视觉的工业机器人抓取工作站2019-09-18 0
-
基于图像的机器人视觉伺服系统该怎么设计?2019-09-27 0
-
服务机器人的视觉系统怎么设计?2020-04-07 0
-
四元数数控:工业机器人使用机器视觉系统的原因2021-04-29 0
-
工业机器人与视觉实训平台介绍2021-07-01 0
-
工业机器人与智能视觉系统应用实训平台介绍2021-07-01 0
-
ZN-1AI工业机器人与智能视觉系统应用实训平台介绍2021-07-01 0
-
机器人视觉系统研究2021-09-07 0
-
抓取作业机器人3D视觉系统的设计2019-07-25 7229
-
基于视觉的机器人抓取系统2022-05-07 2938
-
浅谈机器人视觉抓取的目的2023-03-30 720
-
基于视觉的自主导航移动抓取机器人搭建方案2023-12-19 741
全部0条评论

快来发表一下你的评论吧 !
