

Linux内核的物理内存组织结构详解
嵌入式技术
描述
Linux中内存管理子系统使用 节点(node)、区域(zone)和页(page) 三级结构描述物理内存。
内存节点
内存节点分两种情况:UMA和NUMA。
从管理内存的方法上区分,计算机可以分为两种类型:UMA和NUMA。
UMA:一致性内存访问,uniform memory access
NUMA:非一致性内存访问,non-uniform memory access
两种类型示意图:
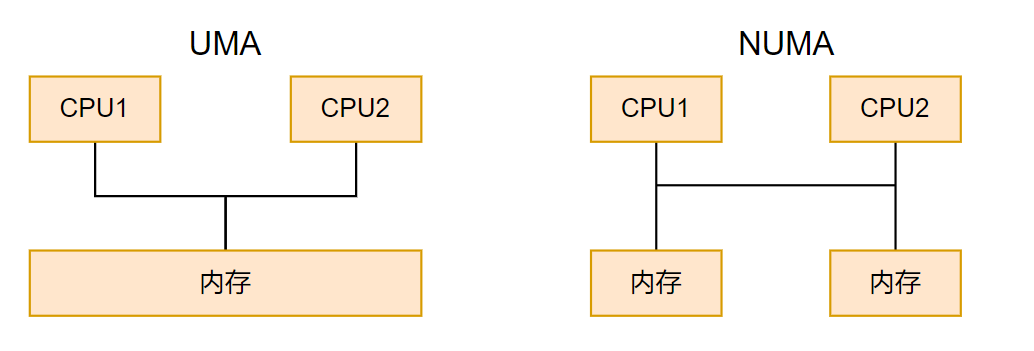
对UMA来说,每一个CPU访问的都是同一块内存,因此各CPU对内存的访问不存在性能差异
对NUMA来说,各内存和各CPU通过总线连在一起,每个CPU都有一个本地内存,访问速度快,CPU也可以访问其他CPU的本地内存,但速度稍慢
Linux为了统一这两种平台,在内存组织中,将最高层次定义为内存节点 .
可以看到,图中UMA只有一个内存节点,而NUMA有两个内存节点。
实际上,UMA其实是NUMA的一个特例,所以内核可以将内存都看做NUMA类型的。
区域
每个内存节点都划分为多个区,Linux内核中定义了以下几个区:
include/linux/mmzone.h
enum zone_type{
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdefi CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
ZONE_DMA
DMA是“Direct Memory Access”的缩写,直接内存访问。
该区域用于ISA设备的DMA操作,范围是0-16MB。
如果有些设备不能直接访问所有内存,则需要使用DMA区域。例如旧的工业标准体系结构(Industry Standard Architecture, ISA)总线只能直接访问16MB以下的内存。
只适用于Intel x86架构,ARM架构没有这个内存管理区。
ZONE_DMA32
在64位的系统上使用32位地址寻址的适合DMA操作的内存区。
例如在AMD64系统上,该区域为低4GB的空间。在32位系统上,本区域通常是空的。
ZONE_NORMAL
常规内存区,指的是可以直接映射到内核空间的内存。
也常称为“ 普通区域 ”“ 直接映射区域 ”“ 线性映射区域 ”。
所谓线性映射就是物理地址和映射后的虚拟地址存在一种简单的关系,即 虚拟地址=物理地址+固定偏移 。
在32位系统上,内核空间和用户空间按1:3划分,那么这个固定偏移就是: 0xC0000000 - 物理内存起始地址 。
既然存在一种线性关系,那还需要使用页表对物理地址和虚拟地址做映射吗?
不同处理器架构实现不一样,ARM需要使用页表映射,MIPS则不需要。
ZONE_HIGHMEM
高端内存区,32位时代的产物。在32位系统上,指的是高于896M的物理内存。
32位系统中,内核和用户地址空间按1:3划分,内核地址空间只有1GB,所以不能把1GB以上的内存直接映射到内核地址空间,因此就把不能直接映射的内存划分到了高端内存区。
要将高于896MB的物理内存映射在内核空间的话,需要通过单独的映射来完成,并且这类映射不能保证物理地址和虚拟地址之间存在固定的对应关系(例如ZONE_NORMAL的固定偏移)。
ZONE_DMA、ZONE_DMA32、ZONE_NORMAL通常都统称为低端内存区。
64位系统中没有这个区域,即没有高端内存。因为64系统的内核虚拟地址空间非常大,不再需要高端内存区域。
ZONE_MOVABLE
一个伪内存区,用来防止内存碎片。
ZONE_DEVICE
为支持持久内存(persistent memory)热拔插增加的内存区域
页
站在处理器的角度来看,管理物理内存的最小单位是页面。
现在的处理器都采用分页机制来管理内存,在处理器内部有一个MMU硬件,它会处理虚拟内存到物理内存的映射,也就是做页表的翻译工作。
Linux内核中使用一个page数据结构来描述一个物理页面。
页的大小通常是4KB ,但有个的架构的处理器可以支持大于4KB的页,例如8KB、16KB或者64KB的页。
目前Linux内核默认使用4KB的页面。
所以,Linux内核的用三级结构来管理物理内存,简言之就是 内存首先划分成若干个大的节点,每个节点又包含若干个区,每个区有包含若干页。 Linux内核按页管理内存,最基本的内存分配和释放都是按页进行的。
-
Linux内核结构详解2019-07-11 0
-
Linux内核地址映射模型与Linux内核高端内存详解2018-05-08 3457
-
高端内存的详解:linux用户空间与内核空间2019-04-28 994
-
详解Linux的物理内存2020-01-18 2416
-
一文解析Linux内存系统2020-09-01 2444
-
Linux内核GPIO操作函数的详解分析2021-01-22 739
-
Linux内核内存管理之内核非连续物理内存分配2024-02-23 972
-
Linux0.11-内存组织和进程结构2019-05-15 1117
-
STM32MP157 Linux系统移植开发篇7:Linux内核目录结构详解2021-12-17 580
-
一文详解Linux内核源码组织结构2022-05-10 5765
-
Linux的内存管理是什么,Linux的内存管理详解2022-05-11 6062
-
走进Linux内存系统探寻内存管理的机制和奥秘2023-01-05 1631
-
Linux内核之物理内存组织结构2023-02-08 966
-
Linux内核内存泄漏怎么办2023-07-04 824
-
Linux内核的内存管理详解2023-08-31 791
全部0条评论

快来发表一下你的评论吧 !
