

谈谈大数据时代中数据架构的变迁
描述
一、前大数据时代
人人都知道罗马不是一天建成的,但没人告诉过你罗马是怎样一天天建成的。你看见罗马时,它就已经是罗马了。当我进阿里时,正是这样的感觉。
我没有经历过阿里数据架构(包括平台工具)从0到1的过程。我相信很多阿里老员工也没有未见得全经历过。因为从行业视角来看,这是一个长达二三十年的过程,阿里作为先行者本身也是摸着石头过河。很多年轻一些的阿里员工看到当前的架构设计,他们的感受大概就是:“不就该是这样吗?不然还能怎样?”
鲁迅就有话说了:“从来如此,便对么?”
好在我前些年辗转了多家公司,有幸在一线接触到了国内外各种不同业务不同类型的数据团队及架构,再加上自己翻阅资料,才基本梳理清楚了数据架构的发展脉络。
BI系统
现在人们身处大数据时代的洪流之中,数据产品日新月异,令人应接不暇。阿里还出过一本书——《大数据之路》,里面详细介绍了大数据从采集到消费等各个环节的方法论和案例。那么,在大数据时代之前,人们也进行数据分析吗?那时的人们又使用的是怎样的工具和方法论呢? 这就要介绍一位熟悉又陌生的老朋友——BI系统。说它熟悉,是因为数据侧的同学几乎天天都会和BI系统打交道,比如阿里的FBI。说它陌生,是因为现在的BI系统与上世纪九十年代的初代BI系统并不完全是一回事。
BI(Business Intelligence,商业智能)的概念很早就有了(正如AI这一概念一样)。早期它的内涵相对模糊,按照百度百科的解释:“商业智能描述了一系列的概念和方法,通过应用基于事实的支持系统来辅助商业决策的制定。“随着人们实践不断深入,BI系统的样貌也逐渐清晰。
到了上世纪九十年代,BI系统迎来了它的第一个辉煌时期,Gartner将各种类型的类BI系统全部统称为BI,BI产品也基本确定为了是一套集数据清洗、数据分析、数据挖掘、报表展示等功能于一体的完整解决方案,数据仓库也基于此建立。从此BI系统一统江湖,江湖上再也没了DSS(Decision Support System, 决策支持系统)、EIS(Executive Information System, 主管信息系统)的名字。如果大家翻阅出版于上世纪八九十年代的数据仓库领域的书籍,就会发现里面频繁出现DSS、EIS、DW/BI等概念,例如William H.Inmon所著的《数据仓库(Building the Data Warehouse)》、Ralph Kimball所著的《数据仓库生命周期工具箱(The Data Warehouse Lifecycle Toolkit)》等,即便它们经历了多次翻译和再版,但其中的概念还是得以保留,大家一定要注意辨析其中很多概念实际上早已过时。
事实上,与中国许多工业领域的发展一样,正由于我们起步晚,因此反而没有历史包袱,我国绝大多数企业都没有经历过初代BI的时代,因此除非对技术历史感兴趣也实在没有必要去了解这些概念。 那时虽然没有大数据的概念,但数据分析、商业分析显然是人们长久以来都有的需求,也积累了相当多的方法论。
当数据量不是主要矛盾时,BI系统能够支持的分析方法、UI等层面就成为了核心竞争力。BI系统的核心是Cube,它是一个业务模型抽象,在Cube上可以上钻、下钻、切片,为了更方便多维分析,还配套了MDX查询语言。当然,大多数BI系统都构建在关系型数据库之上,或者说很多BI系统本就是商业关系型数据库的配套产品,因此也都是支持SQL语言的。在计算和存储上可能类似于开源框架Apache Kylin。
初代BI系统没落的原因主要是:
1.底层构建在传统关系型数据库之上,因为存在数据一致性约束等问题,支持不了大数据。(这也暗合了网传了很多年的阿里技术规范中提到的一条——不要设置外键,要通过其他技术手段保证数据一致性。)
2.不支持非结构化数据。
说它没落,但是它也并未消亡,在欧洲、澳大利亚、东南亚等不少地区还有不少传统企业仍然在使用这项技术。因此人们常说这些地方技术落后国内互联网大厂二十年,这就是一典型案例。而中国伴随着经济的快速发展、互联网技术的迅速普及、开源大数据技术的引进和国务院《促进大数据发展行动纲要》的印发,除了阿里等少数企业,几乎是一步到位直接进入了大数据时代。
下面就谈谈大数据时代中数据架构的变迁。
二、大数据架构的演变
传统大数据架构
为了解决上述问题,一些公司开始研发分布式的计算引擎和分布式的存储平台。其中最成功、最知名的便是Google研发的分布式文件系统与MapReduce计算引擎,后来这套技术被开源重写为了Hadoop体系的多个项目,其生态圈也不断扩大。
下图是一个典型的传统大数据架构:
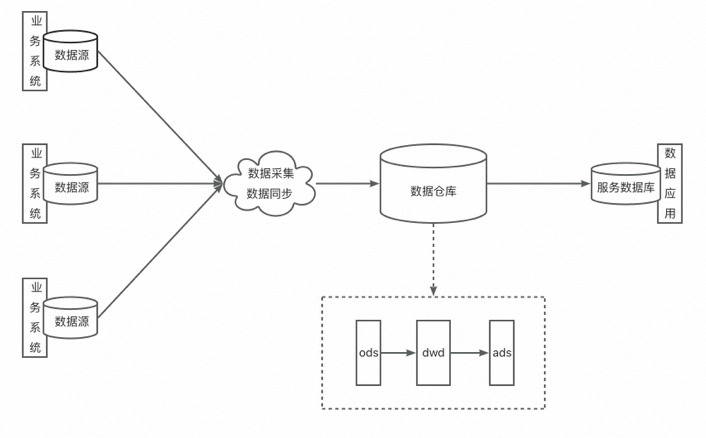
虽然我在上文提到了Hadoop体系,但我还是需要做一点澄清——本文提到的架构与具体的技术选型没有必然联系。比如上图的传统大数据架构,它的业务系统数据源可能是关系型数据库MySQL,也可能是平面文件,也可能是任意未知的源;数据采集和数据同步工具也是视具体的业务和上下游技术选型而定;接下来数据会进入数据仓库,大致上会依次经过ODS层、DWD层和ADS层,最终提供给消费方使用。
在Miravia的技术选型中,通常业务数据通过binlog同步到TT,或者流量日志直接上报到日志服务器,再同步到TT。TT定期将一个时间区间内的数据同步到ODPS,ODPS再通过每日调度的任务对这些数据进行处理,最终落到ADS层的表。结果表的数据再同步到Holo或Lindorm等介质中,供消费方使用。因此单看这整个流程,实际上就是典型的传统大数据架构的一种实现。但需要注意的是,该架构并没有对输入数据有结构化的要求,也没有规定ETL过程使用的工具和编程语言。
在这种架构下,业务系统和分析系统的隔离性做得更好了,而且无论输入数据是什么,最终提供给消费方的都是标准的结构化数据。它的缺点是整个过程不再有完整的解决方案,需要做大量的定制化工作。
流式架构
正应了汤师爷那句话:“步子大了,容易……”
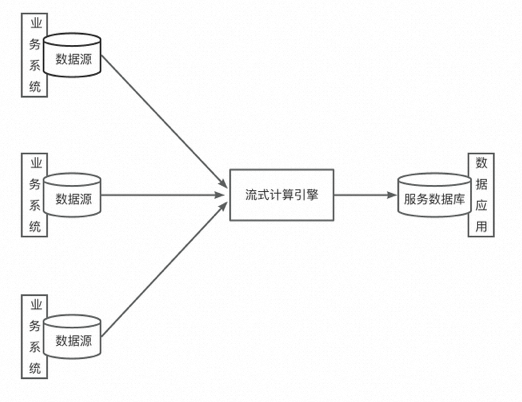
流式架构就是典型代表。
流式架构的思路相当激进。虽然传统大数据架构在技术选型上与BI系统比已经算是脱胎换骨,但其精神还是一脉相承。流式架构干脆扔掉一整套离线的数据采集、数据同步和ETL工作,直接让流式计算引擎消费业务数据库产生的增量数据,并直接输出给消费方,以此提供实时的计算结果。
而早期的技术储备明显不足以同时高质量保证实时性和结果的准确性,因此只被用在了极少数对结果实时性十分敏感却对准确性要求不高的场景中。随着技术的进步和业务复杂度的提高,这种架构也基本销声匿迹了。
下图是流式架构的典型代表:
Lambda架构
在早期技术无法同时支持结果的实时性和准确性的情况下,有没有办法可以通过架构的设计,同时满足两者呢?有一位叫做Nathan Marz的大佬提出了Lambda架构。
先看Lambda架构的示意图:
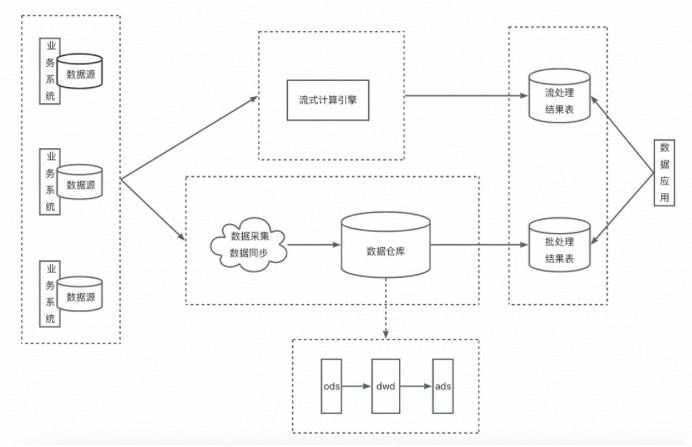
Lambda架构的逻辑是,流任务与批任务读取相同的数据源,实时计算结果由流任务产出;批任务通常按天执行,计算T-1的数据,并写入到结果表中。最终数据应用根据自己的需要对两个结果表的结果进行合并。其核心思路是:用流任务保证结果的实时性,同时用批任务保证结果的最终一致性。
据我观察,凡是对结果有实时性要求的业务团队,在数据侧基本都采用的是这种架构。但Lambda架构有几个显而易见的缺点:
1.需要开发、维护两套系统,成本太大。
2.两套系统难以保证计算口径的一致。甚至不同计算引擎提供的计算语义完全不同。
总之,Lambda架构在满足了部分业务需求的同时,给开发和运维同学也带来了“深重的灾难”。懂的都懂。
因此,我每每看到Lambda架构这种硬把批和流杂糅在一起的架构,都不免想起周星驰《少林足球》中的台词:
“少林功夫+唱歌跳舞,你说有没有搞头啊。”
”没搞头。“
”不试试你怎么知道没搞头。“
说完还边唱边跳:“少林功夫好耶,真是好。”
如果说流式架构好比是人用一条腿走路,存在先天性的不足,那么Lambda架构就是走路时一条腿长一条腿短。
Kappa架构
虽然Lambda架构存在这么多缺点,但有行业大佬背书,并且在现有技术限制下,也很难提出更好的解决方案,故天下数(据)开(发),不敢言而敢怒,只等某一天“戍卒叫,函谷举”。终于等到了另一位大佬Jay Kreps提出了一种新的架构方案——Kappa架构。
在流处理技术不成熟的时期,主要问题之一就是吞吐量上不去。随着Kafka等大数据消息队列的出现,吞吐量不再是瓶颈。Kappa架构的主要贡献之一就是引入了分布式消息队列。如下图所示:
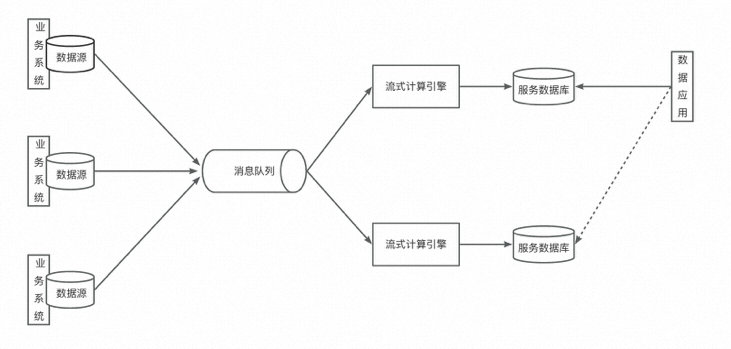
与Lambda架构不通,Kappa架构只保留了流处理层,完全舍弃了批处理层。让其中一个流处理层正常运行,数据应用读取它的输出;当数据出现错误,或是业务逻辑发生变更时,启动另一个流处理层,利用消息队列的重播机制,重新消费先前的数据并输出到另一个结果表中,当确定可以替换线上表时,完成替换。
当然,在实际生产中这个过程会复杂得多。而且受限于消息队列数据生命周期的限制,这种架构在生产中被应用得较少。
不过,Kappa架构的另一贡献是启发了人们用单一系统去实现曾经需要两套系统才能实现的需求。人们开始思考:为什么流式计算引擎不能提供结果的准确性?是哪些环节出了问题?如果流处理能够保证结果准确性,是否意味着重启流任务的需要大大降低,是否意味着Kappa架构能够彻底取代Lambda架构?流处理引擎是否可以实现批处理引擎等价的语义?
后续文章将会通过对Flink底层技术细节的介绍来回答上述问题。在此之前,让我们先脱离具体技术选型,来看看流批一体与上述架构的关系。
三、流批一体与数据架构的关系
流批一体听起来很简单,但内涵却十分复杂。它包含了计算语义、编程模型、API、调度、执行、shuffle等各个方面的统一,不过对于我们数据开发的同学来说,我认为流批一体最终想要达到的效果可以这样描述:给定确定的数据源(可以是物理的也可以是逻辑上的),编写一套代码(Java代码或SQL),执行引擎能够根据需要(例如根据用户配置“STREAMING/BATCH”或自动识别)将代码转换为流任务(增量地读取、流式地处理)或批任务(全量地读取、批式地处理),并输出相同的结果。
可以认为这是计算引擎发展到一定阶段后固有的一个能力,用户可以使用也可以不使用,可以通过配置将其当作单纯的流式/批式计算引擎也是一种选择。
现在我们讨论的,是在同一个应用中,同时使用两种模式(手动配置或自动识别/切换)。而具体如何使用流批一体,要根据应用类型而定,这既决定了流批一体与数据架构的关系,也体现了流批一体在不同场景下的价值。
数据分析型应用
数据侧的同学开发的绝大多数应用都属于数据分析型应用。上一节的所有数据架构也基本是为这种应用设计的。在这种应用中,流批一体与Lambda架构结合得最为自然。如下图所示:
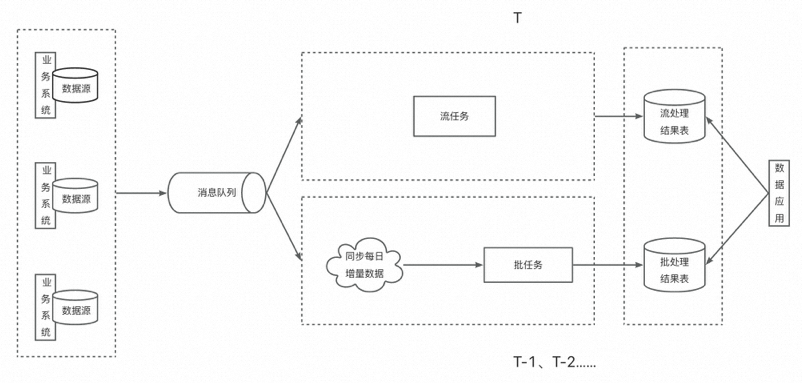
这里引入了消息队列,算是Jay Kreps在提出Kappa架构时给我们提供的改进思路。由于流任务和批任务用的是同一套代码,我们默认计算引擎内部已经实现了语义的统一,因此核心问题在于如何上输入统一。输出结果可以是不同的表,也可以是相同的表,根据需要而定,这并没有太大影响。
因为流任务和批任务对输入的要求是不一样的,前者一般读取的都是类似Kafka这样的消息流,后者则读取的是数据库在某一刻的全量快照,所以我们暂且认为两个任务需要用不同的连接器读取不同的数据源。为了保证输入统一,我们可以让流任务直接读取消息队列中的数据,这样它就在一刻不停地读取业务上的增量数据;在离线侧,我们周期性地将消息队列中的数据落盘,然后每日单独处理当天的增量数据,由此批任务也达成了周期性处理增量数据的效果。理想情况下,当批任务把T-1的数据输出时,结果应与流任务先前输出的T-1的结果相同。
这就是流批一体在数据分析型应用中的典型案例,它是Lambda架构的一种高级实现,解决了原Lambda架构中需要开发两套代码、维护两套系统、计算逻辑口径不一致的问题。Dataphin提供给大家的解决方案就是针对这种应用而来的。
不过要特别注意的是,计算逻辑口径一致不是因为你使用了相同的代码,而是基于相同的代码,计算引擎内部将其翻译成批任务和流任务时在语义、编程模型等方面达到了统一。如果计算引擎内部没有做到这一点,即便写了相同的代码也是无济于事的。
数据管道型应用
除了数据分析型应用,还有一类应用,比如数据同步,这部分工作其实也可以通过计算引擎来实现,流批一体在这其中还能发挥大作用。这类应用可以叫做数据管道型应用。
比如需求是将一个线上数据库中的数据迁移到另一个数据库中,在同步的过程中线上数据库仍然会继续发生增删改查等业务操作。以往的方式往往是先通过一个离线同步工具同步全量数据,再通过另一个增量同步工具不断地同步新增数据。在这个过程中选择从哪一时刻开始增量同步是一大难点。如果在同步的过程中需要对数据做一些清洗或转换,则难度又大了一截。
而通过计算引擎的流批一体能力和对应的connector,则可以解决上述问题。我们可以直接通过写SQL的方式声明数据转换的逻辑,配合connector的能力,计算引擎会先批量读取数据,然后在某一时刻自动切换成流任务增量读取后续数据,而计算引擎内部流批一体的能力保证了语义的相同。
例如Flink CDC项目就是在做这样的事。不过在此场景中Flink runtime是否有流和批的区别,这一点我并没有核实。
不管怎么说,这也可以算是广义的流批一体的应用。并且,利用此技术,还可以实现实时数仓的建设,这在后续文章中或许会提到,大家也可以直接参考其他文章。
四、总结
数据架构经历了如下演变:
早期BI系统 --> 传统大数据架构(解决数据量的问题,但业务延迟高)
传统大数据架构 --> 流式架构(解决业务延迟问题,但数据准确性低)
流式架构 --> Lambda架构(解决数据准确性低的问题,用实时层保证低延迟,用离线层保证数据最终一致性,但架构复杂、计算逻辑口径难以一致)
Lambda架构 --> Kappa架构(解决架构冗余问题和计算逻辑口径不一致的问题,但消息队列数据生命周期短)
最终,在Lambda架构的基础上采用了流批一体实现方案,使得系统复杂度降低,计算逻辑口径达成一致。
流批一体当然也能用在其他架构中,以Flink为例,利用Flink CDC技术还能有更多玩法,但Lambda架构这一案例在我看来是能够最直观展示流批一体这一技术在数据架构中的位置和作用的。
审核编辑:刘清
-
未来,是大数据的时代2014-09-24 0
-
探寻大数据时代的商业变革2017-05-27 0
-
如何从零学大数据?2018-03-01 0
-
常见大数据应用有哪些?2018-03-13 0
-
基于阿里云数加MaxCompute的企业大数据仓库架构建设思路2018-03-15 0
-
大数据时代数据库-云HBase架构&生态&实践2018-05-29 0
-
DKHadoop大数据平台架构详解2018-10-17 0
-
大数据在未来的优势2019-04-29 0
-
图解大数据处理架构2019-05-09 0
-
大数据的定义及其应用2021-07-12 0
-
什么是大数据?大数据的特点有哪些2021-07-12 0
-
什么是大数据2021-08-31 0
-
大数据时代 存储厂商如何应对2015-10-22 1714
-
基于大数据的RTL架构2017-11-07 1450
-
大数据时代有什么样的利与弊2021-02-28 1790
全部0条评论

快来发表一下你的评论吧 !
