

如何在KV260上快速体验Vitsi AI图像分类示例程序
描述
本文首先将会对Vitis统一软件平台和Vitsi AI进行简单介绍,然后介绍如何在KV260上部署DPU镜像,最后在KV260 DPU镜像上运行Vitis AI自带的图像分类示例。通过本文,你将会对Vitis软件平台、Vitsi AI架构有初步认识,并知道如何在KV260上快速体验Vitsi AI图像分类示例程序。
01一、背景简介
开始本文的实操环节之前,这里我先介绍一些背景知识,分别是Vitis统一软件平台和Vitis AI。
1.1 Vitis 统一软件平台简介
来自Xilinx官网的简介,Vitis 统一软件平台包括:
全面的内核开发套件,可无缝构建加速应用
完整的硬件加速开源库,针对 AMD FPGA 和 Versal 自适应 SoC 硬件平台进行了优化
插入特定领域的开发环境,可直接在熟悉的更高层次框架中进行开发
不断发展的硬件加速合作伙伴库和预建应用生态系统
Vitis Model Composer 是一款基于模型的设计工具,不仅可在 MathWorks MATLAB 和 Simulink 环境中实现快速设计探索与验证 ,而且还可加速 AMD 器件的生产进程。
Vitis Networking P4 允许创建软定义网络。VitisNetP4 数据平面构建器生成的系统可以针对从简单的数据包分类到复杂的数据包编辑的各种数据包处理功能进行编程。
来自官网的Vitis统一软件平台架构图:
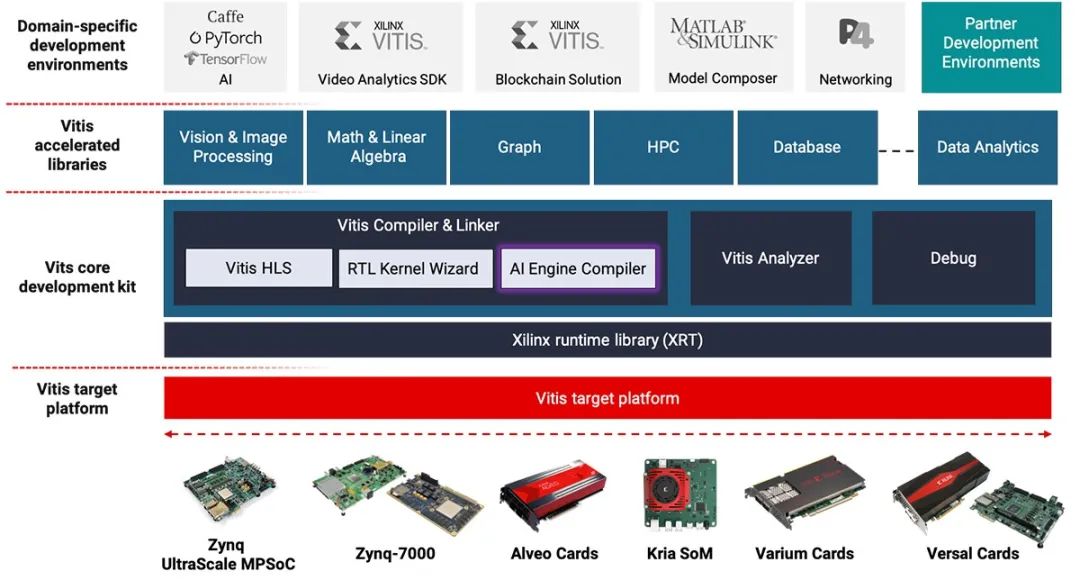
从官网的介绍页面我们也可以看到,Vitis 统一软件平台包括如下组件:
Vitis AI
Vitis 视频分析SDK
Vitis 库
Vitis HLS
Vitis Model Composer
今天我们将会重点介绍Vitis AI。
1.2 Vitsi AI简介
本节内容主要参考了自官方github.io文档。
AMD Vitis AI 是一个集成开发环境,可用于加速 AMD 平台上的 AI 推理。该工具链提供优化的IP、工具、库、模型以及资源,例如示例设计和教程,可在整个开发过程中为用户提供帮助。它在设计时充分考虑了高效率和易用性,在 AMD 自适应 SoC 和 Alveo 数据中心加速卡上释放了 AI 加速的全部潜力。
Vitis AI 解决方案由三个主要组件组成:
深度学习处理器单元 (DPU),用于优化 ML 模型推理的硬件引擎。
模型开发工具,用于为 DPU 编译和优化 ML 模型。
模型部署库和 API,用于从软件应用程序在 DPU 引擎上集成和执行 ML 模型。
Vitis AI 解决方案的打包和交付方式如下:
AMD 开放下载:集成 DPU 的预构建目标映像(以下简称“DPU镜像”)
Vitis AI Docker容器:模型开发工具
Vitis AI github 存储库:模型部署库、设置脚本、示例和参考设计
02二、部署DPU镜像到KV260
2.1 下载DPU镜像
在KV260开发板上正式体验Vitis AI之前,需要将上一节中提到的DPU镜像下载下来并烧录到SD上。
支持KV260的最新DPU镜像下载链接:https://china.xilinx.com/member/forms/download/design-license-xef.html?filename=xilinx-kv260-dpu-v2022.2-v3.0.0.img.gz
2.2 写入DPU镜像到SD卡
下载完成后,解压压缩包,通过Rufus将解压的wic文件写入SD卡。使用Rufus选择文件时,需要注意将右侧的默认文件类型修改为全部文件,否则默认不支持wic文件:
写入过程显示进度:
2.3 启动DPU镜像系统
完成DPU镜像写入SD卡后,将SD卡读卡器从PC移除后,将SD卡插入到开发板,插好串口线,打开串口终端,波特率设置为115200,就可以准备上电开机了。
启动之后会自动登录root账号(默认密码为root):
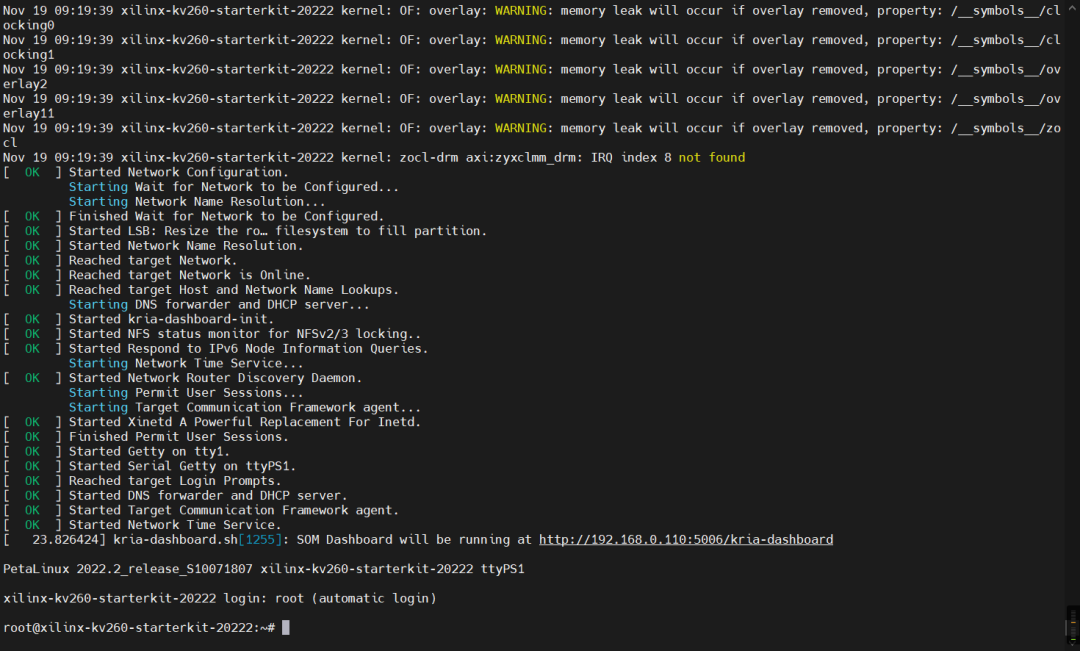
插上网线的话,启动后还可以看到输出了dashborad访问链接:
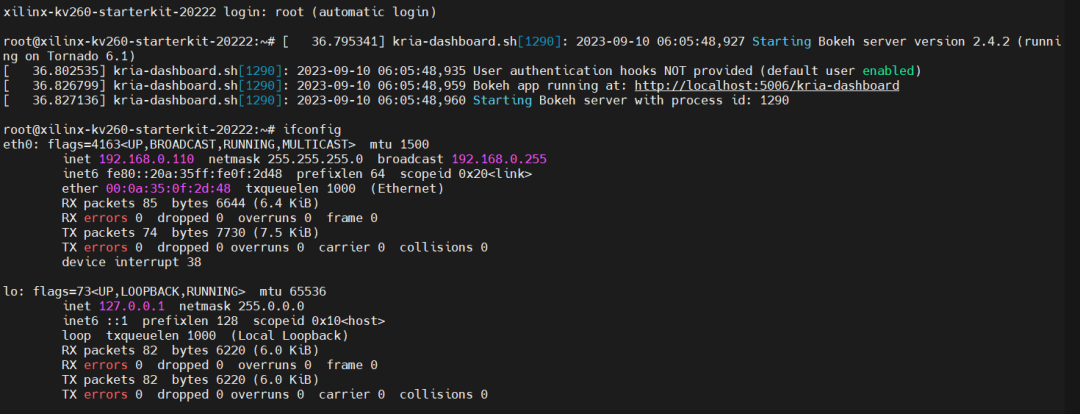
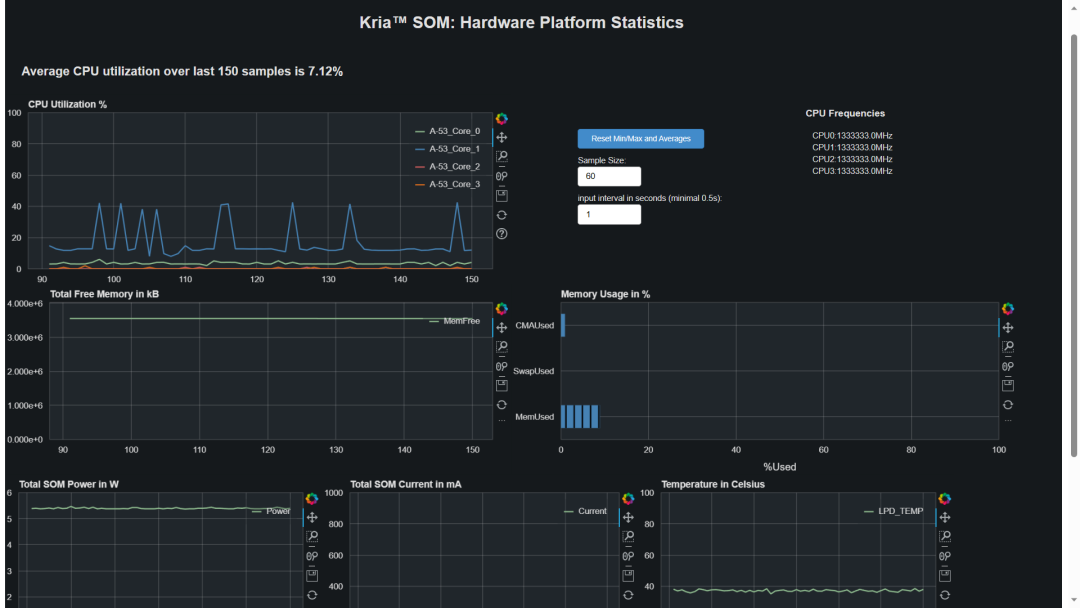
根据ifconfig查看的IP地址,浏览器访问dashboard链接,可以看到实时状态监控:
03三、运行Vitsi AI图像分类示例
3.1 DPU镜像自带的一些文件介绍
DPU镜像默认带有SSH服务,并且是开机启动的,因此可以使用MobaXterm的SSH客户端通过网络登录KV260,如下图所示:
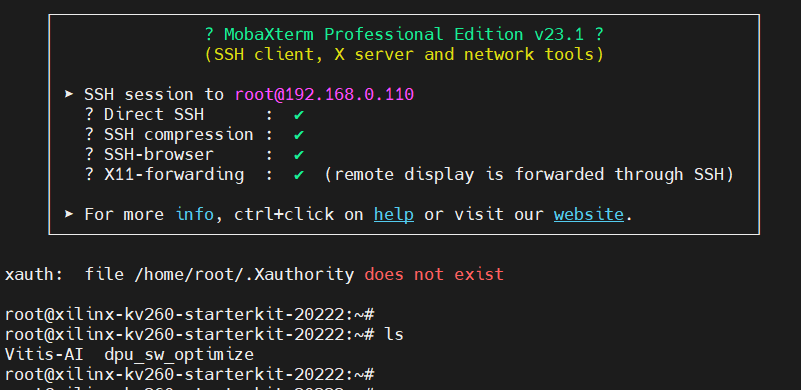
MobaXterm的SSH客户端时带有X11-forwarding功能的,支持将远程程序界面通过SSH协议显示在本地。
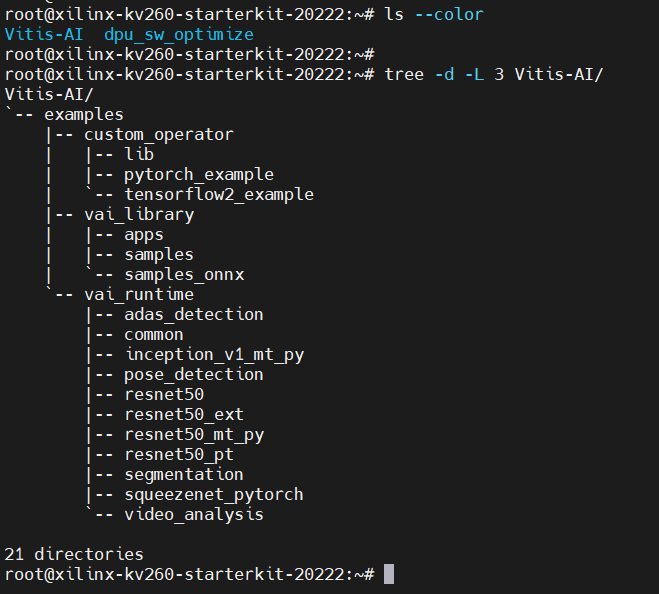
登录系统后,可以看到,/home/root目录下已经有了两个目录。
使用tree命令,可以看到Vitis-AI目录结构:
接下来我们将会尝试运行vai_runtime下的resnet50示例程序,我们先看看这个目录下的文件结构:
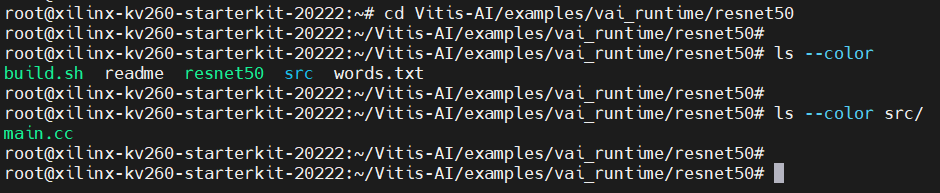
里面有文件的作用分别为:
build.sh,编译脚本,里面包含编译src/main.cc的命令
resnet50,已经编译好的可执行程序,由src/main.cc编译生成
readme,说明文件
words.txt,分类标签
src/main.cc,示例程序源码
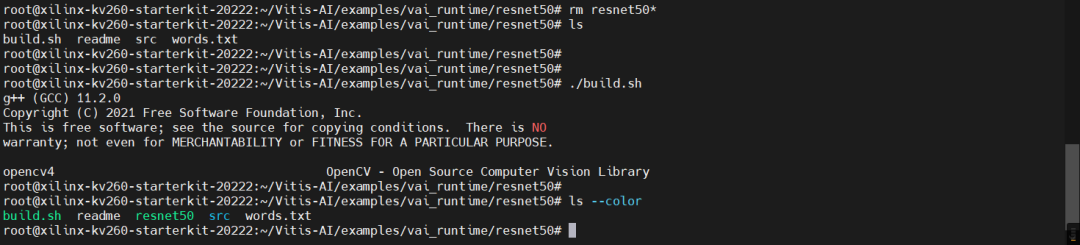
DPU镜像默认已经安装了gcc,直接运行build.sh就可以编译src/main.cc,并生成resnet50可执行文件。可以尝试将resnet50可执行文件删除掉,再运行build.sh脚本,观察是否重新生成了resnet50。
3.2 下载resnet50测试图片
通过以下命令,下载并解压resnet50测试图片:
cd ~ wget https://china.xilinx.com/bin/public/openDownload?filename=vitis_ai_runtime_r3.0.0_image_video.tar.gz -O vitis_ai_runtime_r3.0.0_image_video.tar.gz mkdir vitis_ai_runtime_r3.0.0_image_video tar -C vitis_ai_runtime_r3.0.0_image_video -xzvf vitis_ai_runtime_r3.0.0_image_video.tar.gz
(左右移动查看全部内容)
3.3 运行resnet50示例程序
接下来,通过如下命令,运行resnet50示例程序:
cd ~/Vitis-AI/examples/vai_runtime/resnet50 ./resnet50 /usr/share/vitis_ai_library/models/resnet50/resnet50.xmodel
(左右移动查看全部内容)
运行结果如下:

报错说../images目录找不到。
创建../images目录,并将刚刚下载的resnet50测试图片拷贝到该目录中:
mkdir -v ../images cp -vr ~/vitis_ai_runtime_r3.0.0_image_video/images/* ../images/
(左右移动查看全部内容)
运行输出如下:

再次运行resnet50示例程序:

成功识别了。
命令行第二个参数 /usr/share/vitis_ai_library/models/resnet50/resnet50.xmodel 是resnet50的DPU模型文件,该文件在DPU镜像中已经有了,因此不需要手动下载。
3.4 使用金鱼图片进行测试
words.txt 文件中是resnet50识别结果的分类标签,可以看到前面几行中包含金鱼(goldfish)分类:
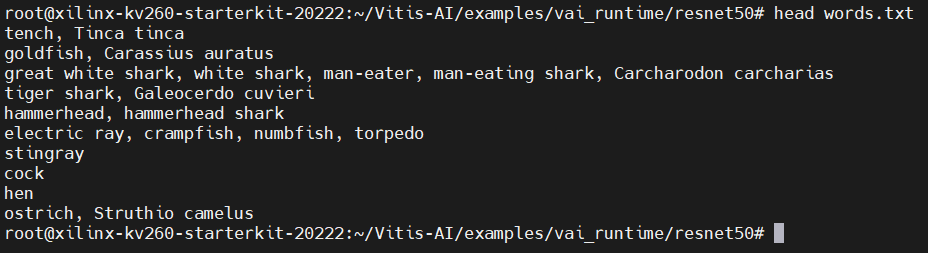
因此,可以找一个金鱼图片进行测试。
随便找了一张:
通过MobaXterm左侧边栏的上传功能传到开发板上:
默认上传位置为HOME目录(~)。
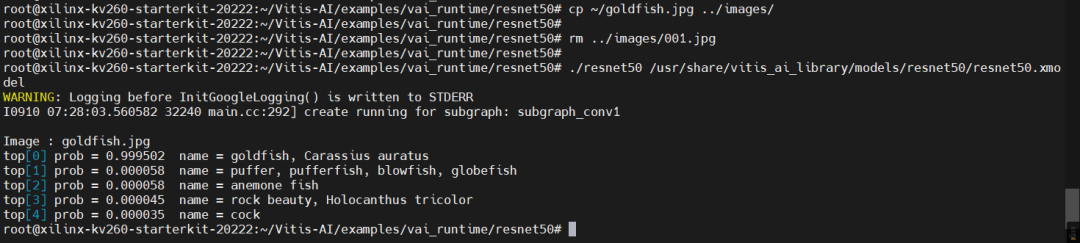
接下来,将金鱼图片拷贝到../images目录,并将原来的测试图片删除掉,重新运行resnet50示例程序,可以看到成功识别了金鱼:
04四、示例程序源码解读
接下来我们看看resnet50目录下的src/main.cc文件内容。
4.2 main函数
首先是main函数:
/**
* [url=home.php?mod=space&uid=2666770]@Brief[/url] Entry for runing ResNet50 neural network
*
* [url=home.php?mod=space&uid=1902110]@NOTE[/url] Runner APIs prefixed with "dpu" are used to easily program &
* deploy ResNet50 on DPU platform.
*
*/
int main(int argc, char* argv[]) {
// Check args
if (argc != 2) {
cout << "Usage of resnet50 demo: ./resnet50 [model_file]" << endl;
return -1;
}
auto graph = xir::deserialize(argv[1]);
auto subgraph = get_dpu_subgraph(graph.get());
CHECK_EQ(subgraph.size(), 1u)
<< "resnet50 should have one and only one dpu subgraph.";
LOG(INFO) << "create running for subgraph: " << subgraph[0]->get_name();
/*create runner*/
auto runner = vart::create_runner(subgraph[0], "run");
// ai::XdpuRunner* runner = new ai::XdpuRunner("./");
/*get in/out tensor*/
auto inputTensors = runner->get_input_tensors();
auto outputTensors = runner->get_output_tensors();
/*get in/out tensor shape*/
int inputCnt = inputTensors.size();
int outputCnt = outputTensors.size();
TensorShape inshapes[inputCnt];
TensorShape outshapes[outputCnt];
shapes.inTensorList = inshapes;
shapes.outTensorList = outshapes;
getTensorShape(runner.get(), &shapes, inputCnt, outputCnt);
/*run with batch*/
runResnet50(runner.get());
return 0;
}
(左右移动查看全部内容)
其中:
auto graph = xir::deserialize(argv[1]); 用于加载模型
auto runner = vart::create_runner(subgraph[0], "run"); 用于创建Runner对象
auto inputTensors = runner->get_input_tensors(); 用于获取输入Tensor对象
auto outputTensors = runner->get_output_tensors(); 用于获取输出Tensor对象
最后的 runResnet50(runner.get()); 运行模型
4.2 runRestnet50函数
接下来我们看看runReset50函数:
/**
* @brief Run DPU Task for ResNet50
*
* [url=home.php?mod=space&uid=3142012]@param[/url] taskResnet50 - pointer to ResNet50 Task
*
* [url=home.php?mod=space&uid=1141835]@Return[/url] none
*/
void runResnet50(vart::Runner* runner) {
/* Mean value for ResNet50 specified in Caffe prototxt */
vector kinds, images;
/* Load all image names.*/
ListImages(baseImagePath, images);
if (images.size() == 0) {
cerr << "
Error: No images existing under " << baseImagePath << endl;
return;
}
/* Load all kinds words.*/
LoadWords(wordsPath + "words.txt", kinds);
if (kinds.size() == 0) {
cerr << "
Error: No words exist in file words.txt." << endl;
return;
}
float mean[3] = {104, 107, 123};
/* get in/out tensors and dims*/
auto outputTensors = runner->get_output_tensors();
auto inputTensors = runner->get_input_tensors();
auto out_dims = outputTensors[0]->get_shape();
auto in_dims = inputTensors[0]->get_shape();
auto input_scale = get_input_scale(inputTensors[0]);
auto output_scale = get_output_scale(outputTensors[0]);
/*get shape info*/
int outSize = shapes.outTensorList[0].size;
int inSize = shapes.inTensorList[0].size;
int inHeight = shapes.inTensorList[0].height;
int inWidth = shapes.inTensorList[0].width;
int batchSize = in_dims[0];
std::vector> inputs, outputs;
vector imageList;
int8_t* imageInputs = new int8_t[inSize * batchSize];
float* softmax = new float[outSize];
int8_t* FCResult = new int8_t[batchSize * outSize];
std::vector inputsPtr, outputsPtr;
std::vector> batchTensors;
/*run with batch*/
for (unsigned int n = 0; n < images.size(); n += batchSize) {
unsigned int runSize =
(images.size() < (n + batchSize)) ? (images.size() - n) : batchSize;
in_dims[0] = runSize;
out_dims[0] = batchSize;
for (unsigned int i = 0; i < runSize; i++) {
Mat image = imread(baseImagePath + images[n + i]);
/*image pre-process*/
Mat image2; //= cv::Mat(inHeight, inWidth, CV_8SC3);
resize(image, image2, Size(inHeight, inWidth), 0, 0);
for (int h = 0; h < inHeight; h++) {
for (int w = 0; w < inWidth; w++) {
for (int c = 0; c < 3; c++) {
imageInputs[i * inSize + h * inWidth * 3 + w * 3 + c] =
(int8_t)((image2.at(h, w)[c] - mean[c]) * input_scale);
}
}
}
imageList.push_back(image);
}
/* in/out tensor refactory for batch inout/output */
batchTensors.push_back(std::shared_ptr(
xir::create(inputTensors[0]->get_name(), in_dims,
xir::DataType{xir::XINT, 8u})));
inputs.push_back(std::make_unique(
imageInputs, batchTensors.back().get()));
batchTensors.push_back(std::shared_ptr(
xir::create(outputTensors[0]->get_name(), out_dims,
xir::DataType{xir::XINT, 8u})));
outputs.push_back(std::make_unique(
FCResult, batchTensors.back().get()));
/*tensor buffer input/output */
inputsPtr.clear();
outputsPtr.clear();
inputsPtr.push_back(inputs[0].get());
outputsPtr.push_back(outputs[0].get());
/*run*/
auto job_id = runner->execute_async(inputsPtr, outputsPtr);
runner->wait(job_id.first, -1);
for (unsigned int i = 0; i < runSize; i++) {
cout << "
Image : " << images[n + i] << endl;
/* Calculate softmax on CPU and display TOP-5 classification results */
CPUCalcSoftmax(&FCResult[i * outSize], outSize, softmax, output_scale);
TopK(softmax, outSize, 5, kinds);
/* Display the impage */
bool quiet = (getenv("QUIET_RUN") != nullptr);
if (!quiet) {
cv::imshow("Classification of ResNet50", imageList[i]);
cv::waitKey(10000);
}
}
imageList.clear();
inputs.clear();
outputs.clear();
}
delete[] FCResult;
delete[] imageInputs;
delete[] softmax;
}
(左右移动查看全部内容)
其中,关键代码行如下:
ListImages(baseImagePath, images); 用于列出../images目录中的图片文件
LoadWords(wordsPath + "words.txt", kinds); 用于读取words.txt中的分类标签
Mat image = imread(baseImagePath + images[n + i]); 用于读取图片
resize(image, image2, Size(inHeight, inWidth), 0, 0); 用于将图片缩放为模型需要的尺寸
auto job_id = runner->execute_async(inputsPtr, outputsPtr); 开始异步执行模型推理
runner->wait(job_id.first, -1); 等待异步执行完成
cv::imshow("Classification of ResNet50", imageList[i]); 显示图片
cv::waitKey(10000); 等待键盘按键10秒
好了本篇内容就到这里了,感谢阅读,下次再会。
审核编辑:汤梓红
-
[KV260视觉入门套件试用体验]+KV260 开发套件使用初体验2023-07-31 0
-
【KV260视觉入门套件试用体验】运行SmartCamera示例程序2023-08-20 0
-
【KV260视觉入门套件试用体验】KV260 开发套件使用体验(二、接通摄像头)2023-09-03 0
-
【KV260视觉入门套件试用体验】部署DPU镜像并运行Vitis AI图像分类示例程序2023-09-10 0
-
【KV260视觉入门套件试用体验】KV260开发板初使用2023-09-18 0
-
【KV260视觉入门套件试用体验】Vitis-AI加速的YOLOX视频目标检测示例体验和原理解析2023-10-06 0
-
【KV260视觉入门套件试用体验】+03.SmartCamera人脸识别示例程序(zmj)2023-10-15 0
-
【KV260视觉入门套件试用体验】KV260开箱及镜像烧写2023-10-16 0
-
【KV260视觉入门套件试用体验】四、KV260 视觉入门套件和固件更新2023-10-17 0
-
贸泽备货Xilinx Kria KV260视觉AI入门套件,助力快速开发视觉应用2021-06-28 2483
-
Kria KV260上的动态交通灯系统2022-10-26 500
-
使用Xilinx Kria KV260进行AI火灾探测2022-10-27 828
-
Kria KV260 AI视觉套件入门2022-11-15 1111
-
Vitis ai 1.4 KV260镜像开源2023-06-14 691
-
Kria KV260视觉AI入门套件用户指南2023-09-14 335
全部0条评论

快来发表一下你的评论吧 !
