

机器人移动过程中基于概率模型的SLAM方法
机器人
描述
在智能服务机器人逐渐成为行业风口浪尖的今天,移动机器人的身影越来越多地出现在人们身边。相信随着传感技术、智能技术和计算技术等的不断提高,智能移动机器人一定能够在生产和生活中融入人类生活中。其中,在自主定位导航技术中扮演着关键角色的SLAM 技术也成为关注的焦点。那么,究竟是什么是SLAM 技术?SLAM技术究竟是如何实现的?它的核心步骤和难点是什么?今天,小编就来和大家聊聊在机器人自主移动过程中有着重要作用的SLAM技术。
什么是SLAM技术?
SLAM 是同步定位与地图构建 (Simultaneous Localization And Mapping) 的缩写,最早是由 Hugh Durrant-Whyte 和 John J.Leonard 在1988年提出的。SLAM与其说是一个算法不如说它是一个概念更为贴切,它被定义为解决“机器人从未知环境的未知地点出发,在运动过程中通过重复观测到的地图特征(比如,墙角,柱子等)定位自身位置和姿态,再根据自身位置增量式的构建地图,从而达到同时定位和地图构建的目”的问题方法的统称。
SLAM技术的核心步骤
大体上而言,SLAM包含了:感知、定位、建图这三个过程。
感知——机器人能够通过传感器获取周围的环境信息。
定位——通过传感器获取的当前和历史信息,推测出自身的位置和姿态。
建图——根据自身的位姿以及传感器获取的信息,描绘出自身所处环境的样貌。
举个例子,有天张三和朋友们一起喝酒,张三喝高了,李四送他回家,但是没有张三的钥匙啊,怎么办,只好送回自己的家里面。那么问题来了,第二天早上张三醒来后,如何知道自己是在谁家里呢?
这个问题很简单,看看房子周围的环境就知道了。没错,张三观察房屋信息的过程就是感知的过程,这时候张三需要提取房子里面对自己有效的信息,例如:房子的面积、墙壁的颜色、家具的特征等等,运气好的话,看到了李四本人,基本上就知道自己是在谁家里了。这个确定是在谁家里的过程,就是定位。
那么建图呢,张三在意识到自己在李四家之后,自然地就把“李四家”和李四家观察到的特征关联起来了,这个就是建图。酒醒后,张三从李四家出来,在回家的路上,张三一路观察周围的环境,估算自己走了多少个街区(定位),一路在脑海里生成这一路走来周围的环境(建图)。
以上就是SLAM的核心步骤。从上面的例子可以发现,感知是SLAM的必要条件,只有感知到周围环境的信息才能够可靠地进行定位以及构建环境的地图。
而定位和建图则是一个相互依赖的过程:定位依赖于已知的地图信息,张三只有知道李四家的位置,才知道自己离开李四家的距离;建图依赖于可靠地定位,知道自己离开多远后,才知道左边的建设银行离李四家的距离。
当然定位和建图的数据必然包含了张三一路上观察感知到的自己的相对位移以及对位移的修正。
说了这么多废话,感觉SLAM其实也不是很复杂嘛,是的,这是因为人的大脑很聪明,在潜意识中解决了SLAM中的核心问题——特征提取和追踪、以及最优后验估计。
SLAM的核心问题
大体而言,SLAM问题基本上可以分为前端和后端两个部分。前端主要处理传感器获取的数据,并将其转化为相对位姿或其他机器人可以理解的形式;后端则主要处理最优后验估计的问题,即位姿、地图等的最优估计。
机器人所拥有的传感器主要有:深度传感器(超声波、激光雷达、立体视觉等),视觉传感器(摄像头、信标),惯性传感器(陀螺仪、编码器、电子罗盘)以及绝对坐标(WUB,GPS)等。
不像人对环境的感知,机器人从这些传感器中获取的信息非常有限,不能充分地表征机器人周围地环境。例如常用的2D激光雷达仅能获取一个平面的深度信息;摄像头获得的图像数据机器人不能像人脑那样充分地分辨出每个物体的属性、特征甚至其他联想。
正如上图所示,在人的视野里看到的情况如图(1)所示,但对于只装配了2D激光雷达的机器人而言,它看到的世界却是图(2)中的样子。因此,前端如何充分可靠地的获取更多的有效信息一直是众多SLAM研究者所研究的一个话题。
同时,传感器均会存在噪声,无论是传感器本身固有的噪声还是获取的错误数据,均会对SLAM造成影响。故SLAM的另一个核心问题是:如何从这些带有噪声的信息中,最优地估计出机器人的位姿以及地图信息。
目前SLAM处理后端的方法可大致分为两类:基于概率模型的方法和基于优化的方法。基于概率模型的SLAM是2D-SLAM中比较主流的方法,比较具有代表性的有EKF、UKF以及PF等,这方面的研究已经相对比较成熟,也逐渐地被应用在了商业场景中;
基于优化是近些年SLAM研究地主流方向,大多应用在VSLAM领域,比较具有代表性的有TORO、G2O等。
SLAM技术的实现方法
正如上文所述,SLAM后端优化的主流方法目前主要分为基于概率模型的方法和基于优化方法两种。作为SLAM“古典时期“的经典方法,基于概率模型的SLAM有着一套十分完备的理论体系,并以其优良的性能,至今仍活跃在SLAM应用领域中。
作为SLAM入门必学经典,小编下面就跟大致大家介绍下基于概率模型的SLAM方法。
基于概率模型的SLAM基本上都可以源自贝叶斯估计,通俗的说,贝叶斯估计就是通过基于假设的先验概率、给定假设下观察到的不同数据的概率以及观察到的数据本身求出后验概率的方法。其公式如下:
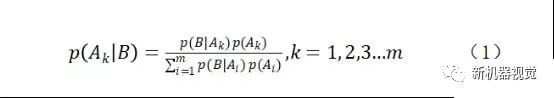
看到这里可能会有点懵,让我们再次请出张三同学为大家现场示范。张三从李四家走出来没多久,由于酒还没怎么醒,有点不记得自己到底走了几个街区了。这时候张三发现自己右边有个建设银行,这样走过多少个街区就可以推测出个八九不离十了。
接下来,张三祭出了传说中的“贝叶斯估计“大法,来算算自己看到右手边有个建设银行后,自己处在第各个街区的概率,标记为p(A|B)。
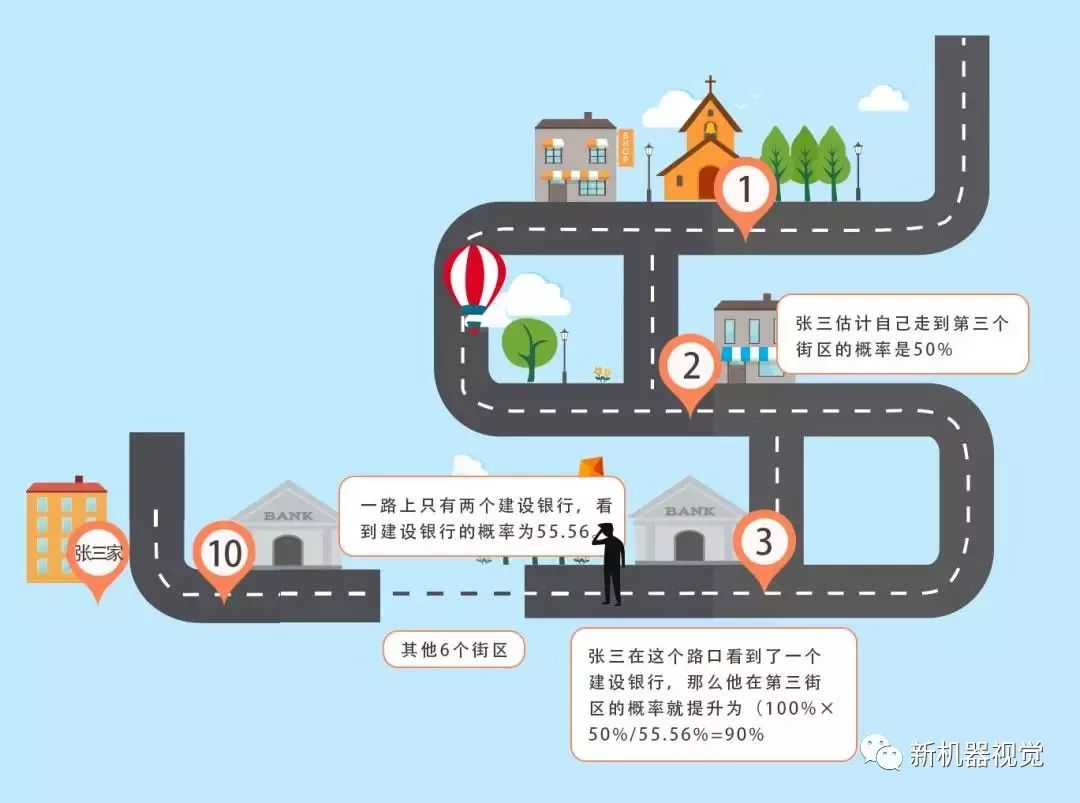
张三用于估计自身位置的有效信息是右手边有个建设银行这个事件,假设张三看到右手边有个建设银行的概率记为p(B),那么条件概率p(B|Ai)的含义就是假设张三处在第i街区,看到自己右手边是建设银行的概率。p(Ai)的含义是张三处在第i街区的概率。
从张三到李四家共十个街区,在第三街区的概率p(A3)=10%。但是观察到右手边有个建设银行了就不一样了:一路上总共有两个建设银行,那么这一路看到建行的概率p(B)=2/10=20%,但假设自己在第三街区,那么看到建行的概率就是p(B|A3)=100%了。
那么在观察到建行的情况下,张三处在第三街区的概率就提升到了100%×10%/20%=50%了。
如果张三比较确信没观察到建行之前自己处在第三街区的概率为50%,其余街区的概率均匀分布,那么一路看到建行的概率
p(B)=100%×50%+100%×5.55%+0%×5.55%×8=55.55%,
则在观察到建行的结果下,张三处于第四街区的概率上升为:100%×50%/55.55%=90%了。
由此可见,贝叶斯估计提供了一种通过先验估计结合观测信息来获得后验估计的方法。
说了这么多,贝叶斯估计究竟是如何应用在SLAM方法中的呢?
对于一个经典的SLAM问题,假设xt是t时刻的状态量,z1:t为时刻的观测量,u1:t是1:t时刻的控制量,m是地图,则SLAM需要求解的是在已知控制量、观测量概率分布的情况下,机器人的位姿状态以及地图最优估计的问题。即:
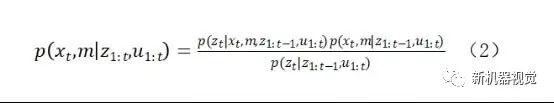
由于p(zt|z1:t-1,u1:t)不依赖于x,对任何后验概率p(zt|z1:t-1,u1:t)都是相同的,可以看作一个常量。在这里假设系统模型的状态转移服从一阶马尔科夫模型,即当前状态xt仅与上一状态xt-1有关,故有:
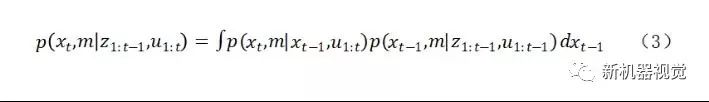
根据式(2)和式(3)可知,在一阶马尔科夫模型的假设下,通过贝叶斯估计可以将当前状态和地图的最优后验估计转化为观测数据的假设条件概率和状态转移方程以及上一状态后验估计的函数。因此对状态和地图的最优后验估计可以通过迭代求解。
以上为一个经典SLAM问题的例子,对于这类问题的解答,有很多方法,比如经典的卡尔曼滤波(KF)、扩展卡尔曼滤波(EKF),无迹卡尔曼滤波(UKF),R-B粒子滤波器(FastSLAM)以及信息滤波(SEIF)等等。他们均是基于概率模型的SLAM问题的求解方法,本质是求出最优后验估计。
以上就是本期关于SLAM算法的初步内容,实际上,要通过 SLAM算法实现到机器人在实际中的运动功能,还是有非常多的工作要做。下面几期小编会给大家介绍“基于概率模型的SLAM方法”中几个比较具有代表性的方法。
编辑:黄飞
-
深度解析|机器人自主移动的秘密(二)2017-06-30 0
-
深度解析|机器人自主移动的秘密(三)2017-08-01 0
-
机器人的主要技术参数2017-08-15 0
-
在未知环境中,机器人如何定位、建图与移动?2017-09-21 0
-
工业机器人的工作原理2017-12-15 0
-
SLAM不等于机器人自主定位导航2018-08-24 0
-
服务机器人是如何实现自主定位导航的?2018-10-10 0
-
机器人、协作机器人和移动机器人,你分的清楚吗2018-10-30 0
-
让机器人完美建图的SLAM 3.0到底是何方神圣?2019-01-21 0
-
机器人基础书籍2019-05-22 0
-
激光SLAM技术在机器人运动控制系统中的应用是什么2021-07-30 0
-
差速移动机器人轨迹跟踪控制方法2021-09-01 0
-
基于SLAM的移动机器人设计2021-11-08 0
-
SLAM技术:机器人自主移动的关键技术2018-08-27 3150
-
为什么自主移动机器人无法绕开SLAM?2019-12-13 2415
全部0条评论

快来发表一下你的评论吧 !
