

etcd的原理和应用
描述
etcd介绍
etcd是什么
etcd 是云原生架构中重要的基础组件,由 CNCF 孵化托管。etcd 在微服务和 Kubernates 集群中不仅可以作为服务注册于发现,还可以作为 key-value 存储的中间件。
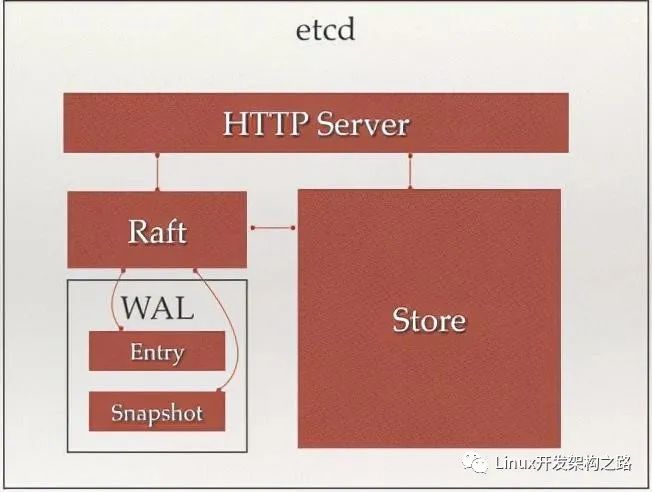
http server:用于处理用户发送的API请求及其他etcd节点的同步与心跳信息请求
store:用于处理etcd支持的各类功能的事务,包括:数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是etcd对用户提供大多数API功能的具体实现
raft:强一致性算法,是etcd的核心
wal(write ahead log):预写式日志,是etcd的数据存储方式。除了在内存中存有所有数据的状态及节点的索引外,还通过wal进行持久化存储。
- 在wal中,所有的数据提交前都会事先记录日志
- entry是存储的具体日志内容
- snapshot是为了防止数据过多而进行的状态快照
etcd的特点
etcd的目标是构建一个高可用的分布式键值(key-value)数据库。具有以下特点:
- 简单:安装配置简单,而且提供了 HTTP API 进行交互,使用也很简单
- 键值对存储:将数据存储在分层组织的目录中,如同在标准文件系统中
- 监测变更:监测特定的键或目录以进行更改,并对值的更改做出反应
- 安全:支持 SSL 证书验证
- 快速:根据官方提供的 benchmark 数据,单实例支持每秒 2k+ 读操作
- 可靠:采用 raft 算法,实现分布式系统数据的可用性和一致性
etcd 采用 Go 语言编写,它具有出色的跨平台支持,很小的二进制文件和强大的社区。etcd 机器之间的通信通过 raft 算法处理。
etcd的功能
etcd 是一个高度一致的分布式键值存储,它提供了一种可靠的方式来存储需要由分布式系统或机器集群访问的数据。它可以优雅地处理网络分区期间的 leader 选举,以应对机器的故障,即使是在 leader 节点发生故障时。
从简单的 Web 应用程序到 Kubernetes 集群,任何复杂的应用程序都可以从 etcd 中读取数据或将数据写入 etcd。
etcd的应用场景
最常用于服务注册与发现,作为集群管理的组件使用
也可以用于K-V存储,作为数据库使用
关于etcd的存储
etcd 是一个键值存储的组件,其他的应用都是基于其键值存储的功能展开。
etcd 的存储有如下特点:
1、采用kv型数据存储,一般情况下比关系型数据库快。
2、支持动态存储(内存)以及静态存储(磁盘)。
3、分布式存储,可集成为多节点集群。
4、存储方式,采用类似目录结构。
- 只有叶子节点才能真正存储数据,相当于文件。
- 叶子节点的父节点一定是目录,目录不能存储数据。
服务注册与发现
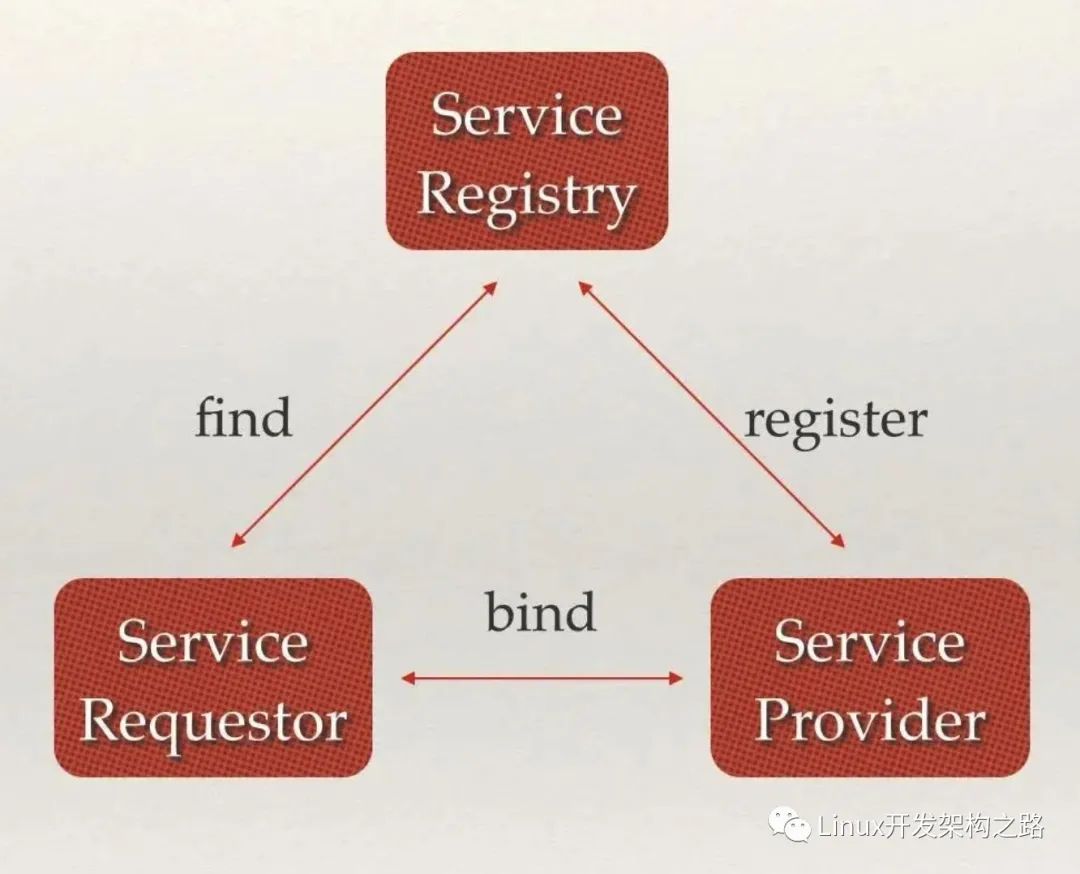
分布式系统中最常见的问题之一:在同一个分布式集群中的进程或服务如何才能找到对方并建立连接
服务发现就可以解决此问题。
从本质上说,服务发现就是要了解集群中是否有进程在监听 UDP 或者 TCP 端口,并且通过名字就可以进行查找和链接
服务发现的三大支柱
强一致性、高可用的服务存储目录。基于 Raft 算法的 etcd 天生就是这样一个强一致性、高可用的服务存储目录。
一种注册服务和服务健康状况的机制。用户可以在 etcd 中注册服务,并且对注册的服务配置 key TTL,定时保持服务的心跳以达到监控健康状态的效果。
一种查找和连接服务的机制。通过在 etcd 指定的主题下注册的服务业能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个 Proxy 模式的 etcd,这样就可以确保访问 etcd 集群的服务都能够互相连接。
etcd2 中引入的 etcd/raft 库,是目前最稳定、功能丰富的开源一致性协议之一。作为 etcd、TiKV、CockcorachDB、Dgraph 等知名分布式数据库的核心数据复制引擎,etcd/raft 驱动了超过十万个集群,是被最为广泛采用一致性协议实现之一
消息发布与订阅
在多节点、分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅,即:
- 即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。通过这种方式可以做到分布式系统配置的集中式管理与动态更新

应用中用到的一些配置信息放到etcd上进行集中管理。这类场景的使用方式通常是:
- 应用在启动的时候主动从etcd获取一次配置信息。
- 同时,在etcd节点上注册一个Watcher并等待
- 以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的
分布式搜索服务中,索引的元信息和服务器集群机器的节点状态存放在etcd中,供各个客户端订阅使用。使用etcd的key TTL功能可以确保机器状态是实时更新的。
etcd中使用了Watcher机制,通过注册与异步通知机制,实现分布式环境下不同系统之间的通知与协调,从而对数据变更做到实时处理。实现方式:
- 不同系统都在etcd上对同一个目录进行注册,同时设置Watcher观测该目录的变化(如果对子目录的变化也有需要,可以设置递归模式)
- 当某个系统更新了etcd的目录,那么设置了Watcher的系统就会收到通知,并作出相应处理。
etcd集群的部署
为了整个集群的高可用,etcd一般都会进行集群部署,以避免单点故障。
引导etcd集群的启动有以下三种机制:
- 静态
- etcd动态发现
- DNS发现
静态启动etcd集群
单机安装
如果想要在一台机器上启动etcd集群,可以使用 goreman 工具(go语言编写的多进程管理工具,是对Ruby下官方使用的foreman的重写)
操作步骤:
- 安装Go运行环境
- 安装goreman:go get github.com/mattn/goreman
- 配置goreman的配置加农本 Procfile:

etcd1: etcd --name infra1 --listen-client-urls http://127.0.0.1:12379 --advertise-client-urls http://127.0.0.1:12379 --listen-peer-urls http://127.0.0.1:12380 --initial-advertise-peer-urls http://127.0.0.1:12380 --initial-cluster-token etcd-cluster-1 --initial-cluster 'infra1=http://127.0.0.1:12380,infra2=http://127.0.0.1:22380,infra3=http://127.0.0.1:32380' --initial-cluster-state new --enable-pprof --logger=zap --log-outputs=stderr
etcd2: etcd --name infra2 --listen-client-urls http://127.0.0.1:22379 --advertise-client-urls http://127.0.0.1:22379 --listen-peer-urls http://127.0.0.1:22380 --initial-advertise-peer-urls http://127.0.0.1:22380 --initial-cluster-token etcd-cluster-1 --initial-cluster 'infra1=http://127.0.0.1:12380,infra2=http://127.0.0.1:22380,infra3=http://127.0.0.1:32380' --initial-cluster-state new --enable-pprof --logger=zap --log-outputs=stderr
etcd3: etcd --name infra3 --listen-client-urls http://127.0.0.1:32379 --advertise-client-urls http://127.0.0.1:32379 --listen-peer-urls http://127.0.0.1:32380 --initial-advertise-peer-urls http://127.0.0.1:32380 --initial-cluster-token etcd-cluster-1 --initial-cluster 'infra1=http://127.0.0.1:12380,infra2=http://127.0.0.1:22380,infra3=http://127.0.0.1:32380' --initial-cluster-state new --enable-pprof --logger=zap --log-outputs=stderr
参数说明:
- –name:etcd集群中的节点名,这里可以随意,可区分且不重复即可
- –listen-peer-urls:监听的用于节点之间通信的url,可监听多个,集群内部将通过这些url进行数据交互(如选举,数据同步等)
- –initial-advertise-peer-urls:建议用于节点之间通信的url,节点间将以该值进行通信。
- –listen-client-urls:监听的用于客户端通信的url,同样可以监听多个。
- –advertise-client-urls:建议使用的客户端通信 url,该值用于 etcd 代理或 etcd 成员与 etcd 节点通信。
- –initial-cluster-token:etcd-cluster-1,节点的 token 值,设置该值后集群将生成唯一 id,并为每个节点也生成唯一 id,当使用相同配置文件再启动一个集群时,只要该 token 值不一样,etcd 集群就不会相互影响。
- –initial-cluster:也就是集群中所有的 initial-advertise-peer-urls 的合集。
- –initial-cluster-state:new,新建集群的标志
启动:goreman -f /opt/etcd/etc/procfile start
docker启动集群
etcd 使用
gcr.io/etcd-development/etcd 作为容器的主要加速器, quay.io/coreos/etcd 作为辅助的加速器:
- docker pull bitnami/etcd:3.4.7
- docker image tag bitnami/etcd:3.4.7 quay.io/coreos/etcd:3.4.7
镜像设置好之后,启动 3 个节点的 etcd 集群,脚本命令如下:
- 该脚本是部署在三台机器上,每台机器置行对应的脚本即可。
REGISTRY=quay.io/coreos/etcd
# For each machine
ETCD_VERSION=3.4.7
TOKEN=my-etcd-token
CLUSTER_STATE=new
NAME_1=etcd-node-0
NAME_2=etcd-node-1
NAME_3=etcd-node-2
HOST_1= 192.168.202.128
HOST_2= 192.168.202.129
HOST_3= 192.168.202.130
CLUSTER=${NAME_1}=http://${HOST_1}:2380,${NAME_2}=http://${HOST_2}:2380,${NAME_3}=http://${HOST_3}:2380
DATA_DIR=/var/lib/etcd
# For node 1
THIS_NAME=${NAME_1}
THIS_IP=${HOST_1}
docker run
-p 2379:2379
-p 2380:2380
--volume=${DATA_DIR}:/etcd-data
--name etcd ${REGISTRY}:${ETCD_VERSION}
/usr/local/bin/etcd
--data-dir=/etcd-data --name ${THIS_NAME}
--initial-advertise-peer-urls http://${THIS_IP}:2380 --listen-peer-urls http://0.0.0.0:2380
--advertise-client-urls http://${THIS_IP}:2379 --listen-client-urls http://0.0.0.0:2379
--initial-cluster ${CLUSTER}
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
# For node 2
THIS_NAME=${NAME_2}
THIS_IP=${HOST_2}
docker run
-p 2379:2379
-p 2380:2380
--volume=${DATA_DIR}:/etcd-data
--name etcd ${REGISTRY}:${ETCD_VERSION}
/usr/local/bin/etcd
--data-dir=/etcd-data --name ${THIS_NAME}
--initial-advertise-peer-urls http://${THIS_IP}:2380 --listen-peer-urls http://0.0.0.0:2380
--advertise-client-urls http://${THIS_IP}:2379 --listen-client-urls http://0.0.0.0:2379
--initial-cluster ${CLUSTER}
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
# For node 3
THIS_NAME=${NAME_3}
THIS_IP=${HOST_3}
docker run
-p 2379:2379
-p 2380:2380
--volume=${DATA_DIR}:/etcd-data
--name etcd ${REGISTRY}:${ETCD_VERSION}
/usr/local/bin/etcd
--data-dir=/etcd-data --name ${THIS_NAME}
--initial-advertise-peer-urls http://${THIS_IP}:2380 --listen-peer-urls http://0.0.0.0:2380
--advertise-client-urls http://${THIS_IP}:2379 --listen-client-urls http://0.0.0.0:2379
--initial-cluster ${CLUSTER}
--initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN}
动态发现启动etcd集群
在实际环境中,集群成员的ip可能不会提前知道。这种情况下需要使用自动发现来引导etcd集群,而不是事先指定静态配置
协议原理
discovery service protocol 帮助新的 etcd 成员使用共享 URL 在集群引导阶段发现所有其他成员。
该协议使用新的发现令牌来引导一个唯一的 etcd 集群。一个发现令牌只能代表一个 etcd 集群。只要此令牌上的发现协议启动,即使它中途失败,也不能用于引导另一个 etcd 集群。
获取 discovery 的 token:
- 生成将标识新集群的唯一令牌:UUID=$(uuidgen)
- 指定集群的大小:curl -X PUT http://:2379/v2/keys/discovery/6c007a14875d53d9bf0ef5a6fc0257c817f0fb83/_config/size -d value=3
- 将该url地址,作为 --discovery 参数来启动etcd,节点会自动使用该url目录进行etcd的注册和发现服务。
在完成了集群的初始化后,当再需要增加节点时,需要使用etcdctl进行操作,每次启动新的etcd集群时,都使用新的token进行注册。
DNS自发现模式
etcd核心API
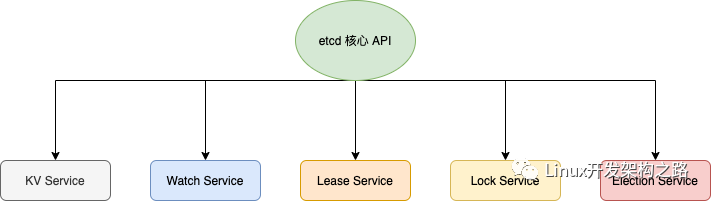
- KV 服务,创建,更新,获取和删除键值对。
- 监视,监视键的更改。
- 租约,消耗客户端保持活动消息的基元。
- 锁,etcd 提供分布式共享锁的支持。
- 选举,暴露客户端选举机制。
etcd典型应用场景(K8s)
什么是k8s?
开源的,用于管理云平台中多个主机上的容器化应用。
与传统应用部署方式的区别:
传统部署:
- 通过插件或脚本的方式安装应用。这样做的缺点是应用的运行、配置、管理、所有生存周期将与当前操作系统绑定,不利于应用的升级更新、回滚等操作。
- 由于资源利用不足而无法扩展,并且组织维护大量物理服务器的成本很高。
虚拟化部署:
- 虚拟化功能,允许在单个物理服务器的cpu上运行多个虚拟机(VM)
- 应用程序在VM之间隔离,提供安全级别
- 虚拟机非常重,可移植性、扩展性差
容器化部署:
- 通过容器的方式实现部署,每个容器之间相互隔离,每个容器有自己的文件系统,容器之间进程不会相互影响,能区分计算资源。
- 相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统是解耦的,所以它能在不同的云、不同版本操作系统之间进行迁移。
- 容器占用资源少、部署快,每个应用都可以被打包成一个容器镜像,每个应用与容器之间形成一对一的关系。每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境的基础结构,这使得从研发–>测试–>生产能提供一致的环境。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(
img-fm4iUxNG-1607939778399)(https://d33wubrfki0l68.cloudfront.net/26a177ede4d7b032362289c6fccd448fc4a91174/eb693/images/docs/container_evolution.svg)]
K8s提供了一个可弹性运行分布式系统的框架,可以满足实际生产环境所需要的扩展要求、故障转移、部署模式等
K8s提供如下功能:
- 服务发现与负载均衡
- 存储编排
- 自动部署和回滚
- 自动二进制打包:K8s允许指定每个容器所需CPU和内存(RAM),当容器制定了资源请求时,K8s可以做出更好的决策来管理容器的资源。
- 自我修复:K8s重新启动失败的容器,替换容器,杀死不响应用户定义的运行状况检查的容器,并且在准备好服务之前将其通告给客户端
- 密钥与配置管理
K8s的特点
可移植: 支持公有云,私有云,混合云,多重云(multi-cloud)
可扩展: 模块化,插件化,可挂载,可组合
自动化: 自动部署,自动重启,自动复制,自动伸缩/扩展
K8s组件
master(主节点)组件:
kube-apiserver:对外提供调用的开放接口服务
ETCD:提供默认的存储系统,保存所有集群数据
kube-controller-manager:运行管理控制器,是集群中处理常规任务的后台线程,包括:
- 节点控制器:
- 副本控制器:负责维护系统中每个副本中的pod(pod是最小的,管理,创建,计划的最小单元)
- 端点控制器:填充endpoints对象(连接service 和 pods)
- service account和token控制器:
cloud-controller-manager:云控制器管理器负责与底层云提供商的平台交互
kube-scheduler:监视新创建没有分配到node的pod,为pod选择一个node
插件 addons:实现集群pod和service功能
- DNS
- 用户界面
- 容器资源监测
- Cluster-level Logging
node(计算节点)组件:
kubelet:主要的节点代理,它会监视已分配给节点的pod
kube-proxy:通过在主机上维护网络规则并执行连接转发来实现k8s服务抽象
docker:运行容器
RKT:运行容器,作为docker工具的替代方案
supervisord:一个轻量级监控系统,用于保障kubelet和docker的运行
fluentd:守护进程,可提供cluster-level logging
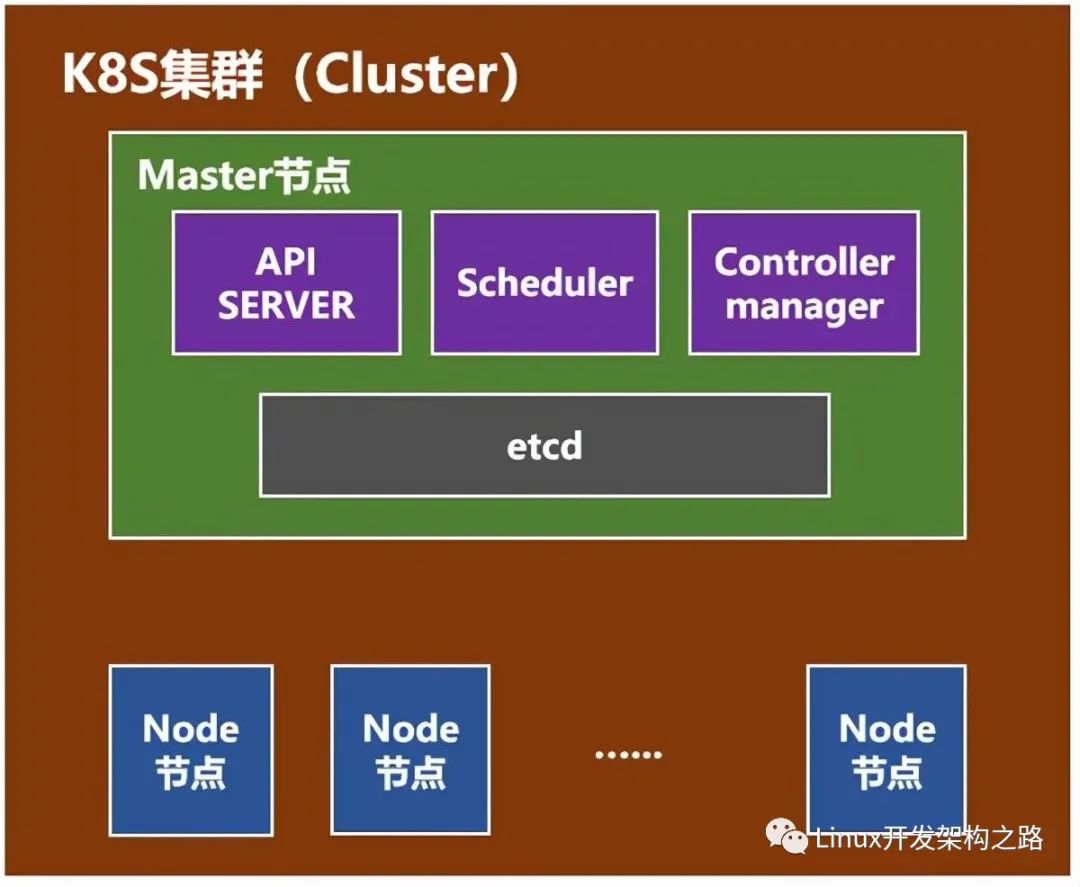
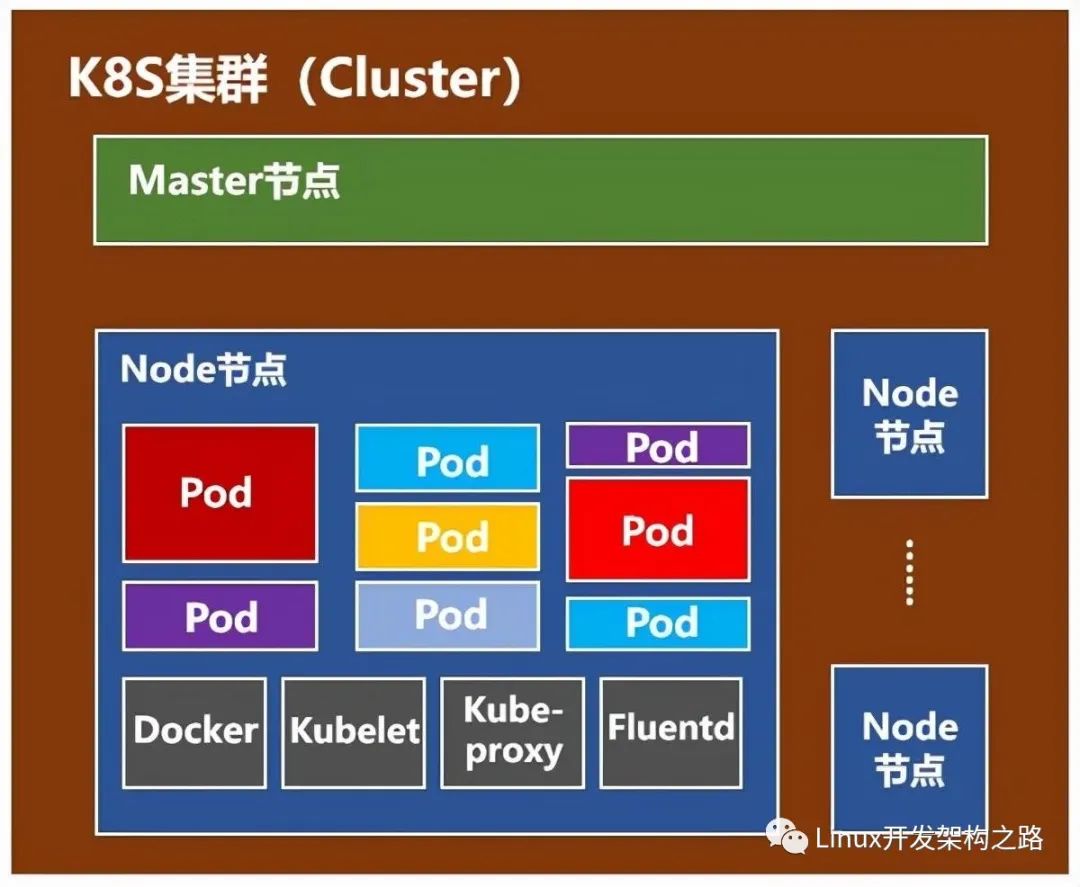
K8s典型架构图
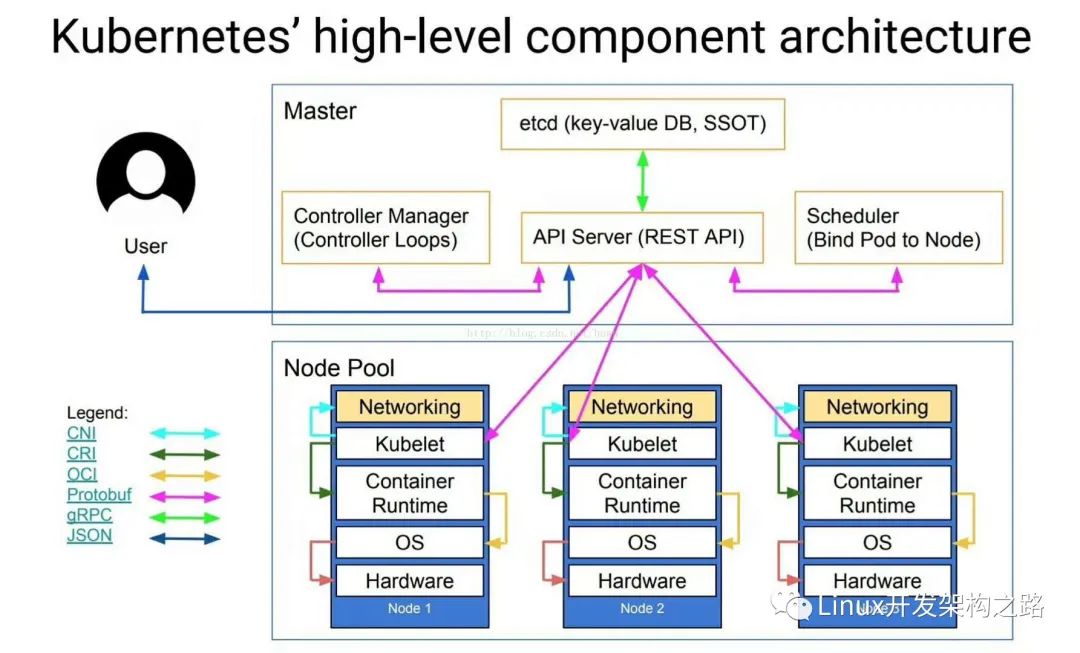
说明:
CNI:CNI(容器网络接口)是Cloud Native Computing Foundation项目,由一个规范和库(用于编写用于在Linux容器中配置网络接口的插件)以及许多受支持的插件组成。CNI仅涉及容器的网络连接以及删除容器时删除分配的资源,通过json的语法定义了CNI插件所需要的输入和输出。
CRI:容器运行时接口,一个能让kubelet无需编译就可以支持多种容器运行时的插件接口。CRI包含了一组protocol buffer。gRPC API相关的库。
OCI:主要负责是容器的生命周期管理,OCI的runtime spec标准中对于容器状态的描述,以及对容器的创建、删除、查看等操作进行了定义。runc是对OCI标准的一个参考实现
-
ETCD集群的工作原理和高可用技术细节介绍2021-02-23 9153
-
降低 80% 的读写响应延迟!我们测评了 etcd 3.4 新特性(内含读写发展史)2019-09-23 0
-
ARM Neoverse IP的AWS实例上etcd分布式键对值存储性能提升2022-07-06 0
-
比较AWS M6g实例与M5实例上的etcd吞吐量和延迟性能2022-09-13 0
-
阿里巴巴持续投入,etcd 正式加入 CNCF2018-12-20 199
-
Kstone etcd一站式治理平台2022-04-28 602
-
公司为啥用ETCD作为配置中心呢2022-09-06 5386
-
多层面分析 etcd 与 PostgreSQL数据存储方案的差异2023-03-20 367
全部0条评论

快来发表一下你的评论吧 !
