

基于机器翻译增加的跨语言机器阅读理解算法
描述
作者: 阿里云云栖号
链接:https://my.oschina.net/yunqi/blog/10319964
近日,阿里云人工智能平台 PAI 与华南理工大学朱金辉教授团队、达摩院自然语言处理团队合作在自然语言处理顶级会议 EMNLP2023 上发表基于机器翻译增加的跨语言机器阅读理解算法 X-STA。通过利用一个注意力机制的教师来将源语言的答案转移到目标语言的答案输出空间,从而进行深度级别的辅助以增强跨语言传输能力。同时,提出了一种改进的交叉注意力块,称为梯度解缠知识共享技术。此外,通过多个层次学习语义对齐,并利用教师指导来校准模型输出,增强跨语言传输性能。实验结果显示,我们的方法在三个多语言 MRC 数据集上表现出色,优于现有的最先进方法。
背景
大规模预训练语言模型的广泛应用,促进了 NLP 各个下游任务准确度大幅提升,然而,传统的自然语言理解任务通常需要大量的标注数据来微调预训练语言模型。但低资源语言缺乏标注数据集,难以获取。大部分现有的 MRC 数据集都是英文的,这对于其他语言来说是一个困难。其次,不同语言之间存在语言和文化的差异,表现为不同的句子结构、词序和形态特征。例如,日语、中文、印地语和阿拉伯语等语言具有不同的文字系统和更复杂的语法系统,这使得 MRC 模型难以理解这些语言的文本。
为了解决这些挑战,现有文献中通常采用基于机器翻译的数据增强方法,将源语言的数据集翻译成目标语言进行模型训练。然而,在 MRC 任务中,由于翻译导致的答案跨度偏移,无法直接使用源语言的输出分布来教导目标语言。
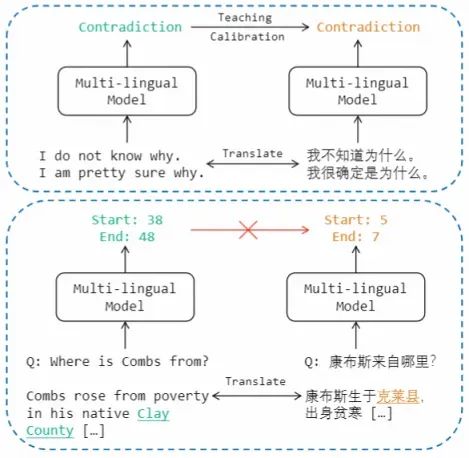
因此,本文提出了一种名为 X-STA 的跨语言 MRC 方法,遵循三个原则:共享、教导和对齐。共享方面,提出了梯度分解的知识共享技术,通过使用平行语言对作为模型输入,从源语言中提取知识,增强对目标语言的理解,同时避免源语言表示的退化。教导方面,本方法利用注意机制,在目标语言的上下文中寻找与源语言输出答案语义相似的答案跨度,用于校准输出答案。对齐方面,多层次的对齐被利用来进一步增强 MRC 模型的跨语言传递能力。通过知识共享、教导和多层次对齐,本方法可以增强模型对不同语言的语言理解能力。
算法概述
X-STA 模型框架图如下所示:
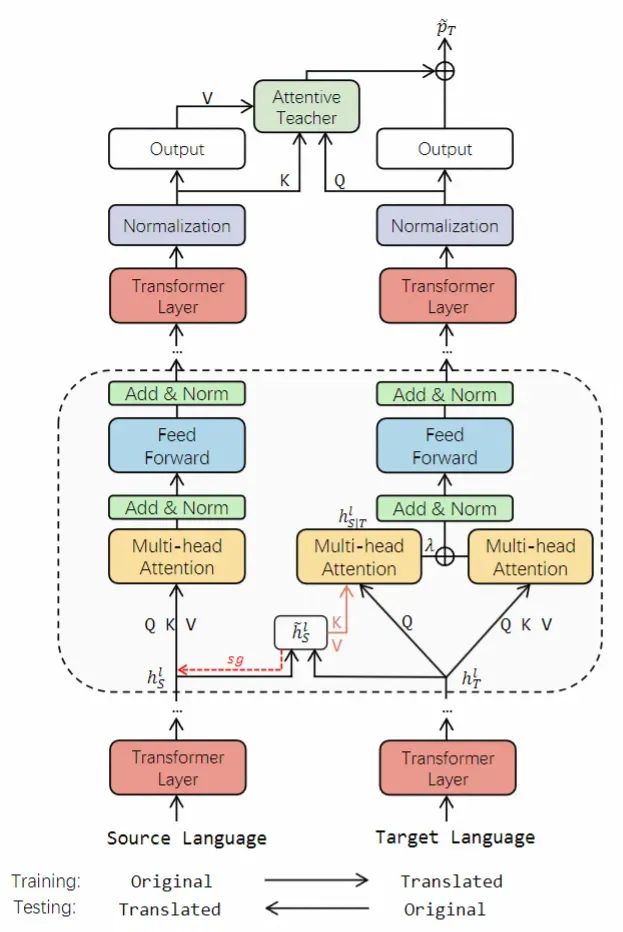

具体流程如下:
先将源语言的目标数据翻译到各个目标语言,目标语言的测试数据也翻译回源语言。
每项数据包含问题 Q 和上下文段落 C。
构建并行语言对 ={源语言训练数据,目标语言训练数据} 送入模型并使用反向传播进行模型训练。
将并行语言对 ={源语言测试数据,目标语言测试数据} 送入模型获取答案的预测。
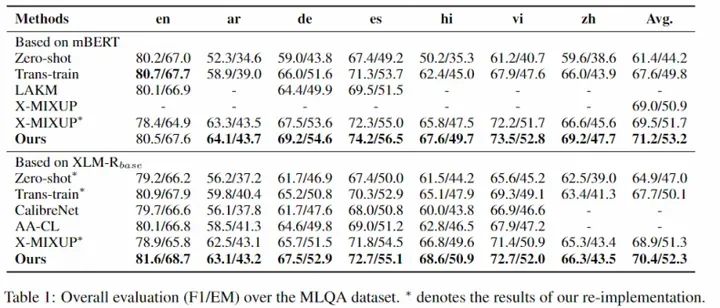
算法精度评测
为了验证 X-STA 算法的有效性,我们在三个跨语言 MRC 数据集上进行了测试,效果证明 X-STA 对精度提升明显:
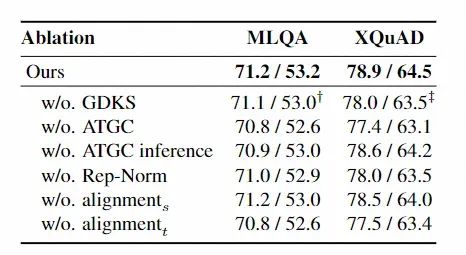
我们也对算法的模块进行了详细有效性分析,我们可以发现各模块均对模型有一定贡献。
为了更好地服务开源社区,这一算法的源代码即将贡献在自然语言处理算法框架 EasyNLP 中,欢迎 NLP 从业人员和研究者使用。
-
机器翻译三大核心技术原理 | AI知识科普2018-07-06 0
-
机器翻译三大核心技术原理 | AI知识科普 22018-07-06 0
-
神经机器翻译的方法有哪些?2020-11-23 0
-
阿里巴巴机器翻译在跨境电商场景下的应用和实践2018-07-31 421
-
换个角度来聊机器翻译2019-04-24 3493
-
科大讯飞机器翻译首次达到专业译员水平 机器阅读超越人类平均水平2019-05-24 8316
-
机器翻译走红的背后是什么2019-07-14 1022
-
MIT和谷歌开发失传语言的机器翻译系统2019-07-17 625
-
未来机器翻译会取代人工翻译吗2020-12-29 5029
-
多语言翻译新范式的工作:机器翻译界的BERT2021-03-31 2984
-
基于短语的汉语维吾尔语机器翻译系统2021-05-11 721
-
基于DNN与规则学习的机器翻译算法综述2021-06-29 693
-
借助机器翻译来生成伪视觉-目标语言对进行跨语言迁移2022-10-14 865
-
大语言模型的多语言机器翻译能力分析2023-05-17 2025
-
机器翻译研究进展2023-07-06 805
全部0条评论

快来发表一下你的评论吧 !
