

 HBase集群数据在线迁移方案探索
HBase集群数据在线迁移方案探索
电子说
描述
一、背景
订单本地化系统目前一个月的订单的读写已经切至jimkv存储,对应的HBase集群已下线。但存储全量数据的HBase集群仍在使用,计划将这个HBase集群中的数据全部迁到jimkv,彻底下线这个HBase集群。由于这个集群目前仍在线上读写,本文从原理和实践的角度探索对HBase集群数据的在线迁移的方案,欢迎大家补充。
二、基础理论梳理
HBase整体架构
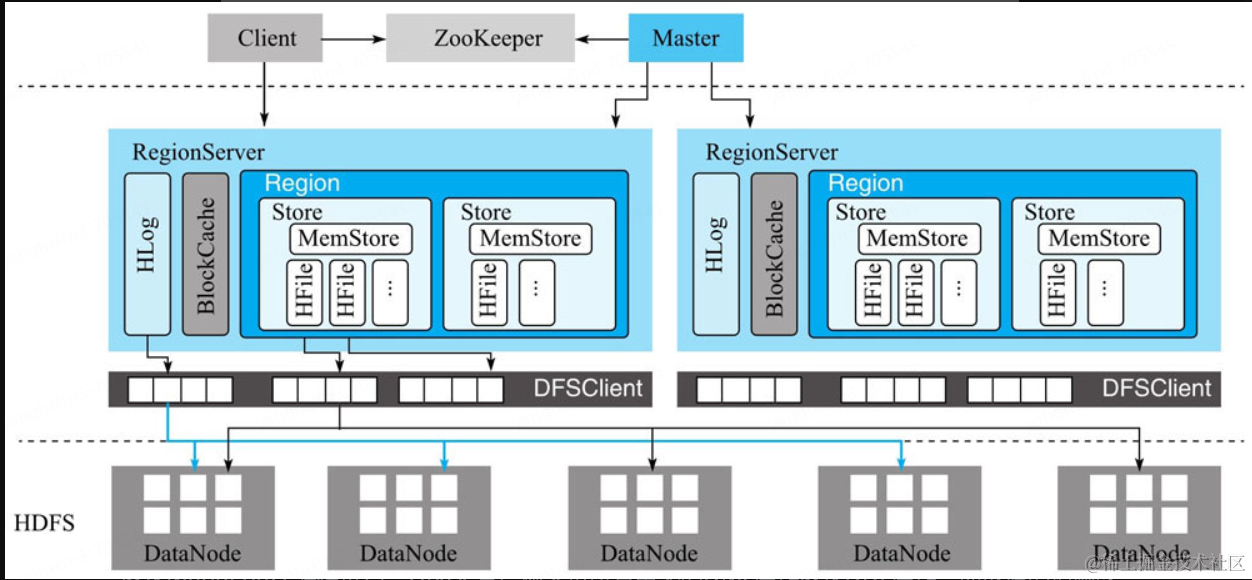
重温一下各个模块的职责
HBase客户端
HBase客户端(Client)提供了Shell命令行接口、原生Java API编程接口、Thrift/REST API编程接口以及MapReduce编程接口。HBase客户端支持所有常见的DML操作以及DDL操作,即数据的增删改查和表的日常维护等。其中Thrift/REST API主要用于支持非Java的上层业务需求,MapReduce接口主要用于批量数据导入以及批量数据读取。HBase客户端访问数据行之前,首先需要通过元数据表定位目标数据所在RegionServer,之后才会发送请求到该RegionServer。同时这些元数据会被缓存在客户端本地,以方便之后的请求访问。如果集群RegionServer发生宕机或者执行了负载均衡等,从而导致数据分片发生迁移,客户端需要重新请求最新的元数据并缓存在本地。
Master
Master主要负责HBase系统的各种管理工作:
•处理用户的各种管理请求,包括建表、修改表、权限操作、切分表、合并数据分片以及Compaction等。
•管理集群中所有RegionServer,包括RegionServer中Region的负载均衡、RegionServer的宕机恢复以及Region的迁移等。
•清理过期日志以及文件,Master会每隔一段时间检查HDFS中HLog是否过期、HFile是否已经被删除,并在过期之后将其删除。
RegionServer
RegionServer主要用来响应用户的IO请求,是HBase中最核心的模块,由WAL(HLog)、BlockCache以及多个Region构成。
•WAL(HLog):HLog在HBase中有两个核心作用——其一,用于实现数据的高可靠性,HBase数据随机写入时,并非直接写入HFile数据文件,而是先写入缓存,再异步刷新落盘。为了防止缓存数据丢失,数据写入缓存之前需要首先顺序写入HLog,这样,即使缓存数据丢失,仍然可以通过HLog日志恢复;其二,用于实现HBase集群间主从复制,通过回放主集群推送过来的HLog日志实现主从复制。
•BlockCache:HBase系统中的读缓存。客户端从磁盘读取数据之后通常会将数据缓存到系统内存中,后续访问同一行数据可以直接从内存中获取而不需要访问磁盘。对于带有大量热点读的业务请求来说,缓存机制会带来极大的性能提升。
对于带有大量热点读的业务请求来说,缓存机制会带来极大的性能提升。BlockCache缓存对象是一系列Block块,一个Block默认为64K,由物理上相邻的多个KV数据组成。BlockCache同时利用了空间局部性和时间局部性原理,前者表示最近将读取的KV数据很可能与当前读取到的KV数据在地址上是邻近的,缓存单位是Block(块)而不是单个KV就可以实现空间局部性;后者表示一个KV数据正在被访问,那么近期它还可能再次被访问。当前BlockCache主要有两种实现——LRUBlockCache和BucketCache,前者实现相对简单,而后者在GC优化方面有明显的提升。
•Region:数据表的一个分片,当数据表大小超过一定阈值就会“水平切分”,分裂为两个Region。Region是集群负载均衡的基本单位。通常一张表的Region会分布在整个集群的多台RegionServer上,一个RegionServer上会管理多个Region,当然,这些Region一般来自不同的数据表。
一个Region由一个或者多个Store构成,Store的个数取决于表中列簇(column family)的个数,多少个列簇就有多少个Store。HBase中,每个列簇的数据都集中存放在一起形成一个存储单元Store,因此建议将具有相同IO特性的数据设置在同一个列簇中。每个Store由一个MemStore和一个或多个HFile组成。MemStore称为写缓存,用户写入数据时首先会写到MemStore,当MemStore写满之后(缓存数据超过阈值,默认128M)系统会异步地将数据f lush成一个HFile文件。显然,随着数据不断写入,HFile文件会越来越多,当HFile文件数超过一定阈值之后系统将会执行Compact操作,将这些小文件通过一定策略合并成一个或多个大文件。
HDFS
HBase底层依赖HDFS组件存储实际数据,包括用户数据文件、HLog日志文件等最终都会写入HDFS落盘。HDFS是Hadoop生态圈内最成熟的组件之一,数据默认三副本存储策略可以有效保证数据的高可靠性。HBase内部封装了一个名为DFSClient的HDFS客户端组件,负责对HDFS的实际数据进行读写访问。
三、数据迁移方案调研
1、如何定位一条数据在哪个region
HBase一张表的数据是由多个Region构成,而这些Region是分布在整个集群的RegionServer上的。那么客户端在做任何数据操作时,都要先确定数据在哪个Region上,然后再根据Region的RegionServer信息,去对应的RegionServer上读取数据。因此,HBase系统内部设计了一张特殊的表——hbase:meta表,专门用来存放整个集群所有的Region信息。
hbase:meta表的结构如下,整个表只有一个名为info的列族。而且HBase保证hbase:meta表始终只有一个Region,这是为了确保meta表多次操作的原子性。
hbase:meta的一个rowkey就对应一个Region,rowkey主要由TableName(业务表名)、StartRow(业务表Region区间的起始rowkey)、Timestamp(Region创建的时间戳)、EncodedName(上面3个字段的MD5 Hex值)4个字段拼接而成。每一行数据又分为4列,分别是info:regioninfo、info:seqnumDuringOpen、info:server、info:serverstartcode。
•info:regioninfo:该列对应的Value主要存储4个信息,即EncodedName、RegionName、Region的StartRow、Region的StopRow。
•info:seqnumDuringOpen:该列对应的Value主要存储Region打开时的sequenceId。
•info:server:该列对应的Value主要存储Region落在哪个RegionServer上。
•info:serverstartcode:该列对应的Value主要存储所在RegionServer的启动Timestamp。
为了解决如果所有的流量都先请求hbase:meta表找到Region,再请求Region所在的RegionServer,那么hbase:meta表的将承载巨大的压力,这个Region将马上成为热点Region这个问题,HBase会把hbase:meta表的Region信息缓存在HBase客户端。在HBase客户端有一个叫做MetaCache的缓存,在调用HBase API时,客户端会先去MetaCache中找到业务rowkey所在的Region。

2、HBase client Scan用法
HBase客户端提供了一系列可以批量扫描数据的api,主要有ScanAPI、TableScanMR、SnapshotScanM
HBase client scan demo
public class TestDemo {
private static final HBaseTestingUtility TEST_UTIL=new HBaseTestingUtility();
public static final TableName tableName=TableName.valueOf("testTable");
public static final byte[] ROW_KEY0=Bytes.toBytes("rowkey0");
public static final byte[] ROW_KEY1=Bytes.toBytes("rowkey1");
public static final byte[] FAMILY=Bytes.toBytes("family");
public static final byte[] QUALIFIER=Bytes.toBytes("qualifier");
public static final byte[] VALUE=Bytes.toBytes("value");
@BeforeClass
public static void setUpBeforeClass() throws Exception {
TEST_UTIL.startMiniCluster();
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
TEST_UTIL.shutdownMiniCluster();
}
@Test
public void test() throws IOException {
Configuration conf=TEST_UTIL.getConfiguration();
try (Connection conn=ConnectionFactory.createConnection(conf)) {
try (Table table=conn.getTable(tableName)) {
for (byte[] rowkey : new byte[][] { ROW_KEY0, ROW_KEY1 }) {
Put put=new Put(rowkey).addColumn(FAMILY, QUALIFIER, VALUE);
table.put(put);
}
Scan scan=new Scan().withStartRow(ROW_KEY1).setLimit(1);
try (ResultScanner scanner=table.getScanner(scan)) {
List< Cell > cells=new ArrayList< >();
for (Result result : scanner) {
cells.addAll(result.listCells());
}
Assert.assertEquals(cells.size(), 1);
Cell firstCell=cells.get(0);
Assert.assertArrayEquals(CellUtil.cloneRow(firstCell), ROW_KEY1);
Assert.assertArrayEquals(CellUtil.cloneFamily(firstCell), FAMILY);
Assert.assertArrayEquals(CellUtil.cloneQualifier(firstCell), QUALIFIER);
Assert.assertArrayEquals(CellUtil.cloneValue(firstCell), VALUE);
}
}
}
}
}
Scan API
使用ScanAPI获取Result的流程如下,在上面的demo代码中,table.getScanner(scan)可以拿到一个scanner,然后只要不断地执行scanner.next()就能拿到一个Result,客户端Scan的核心流程如下

用户每次执行scanner.next(),都会尝试去名为cache的队列中拿result(步骤4)。如果cache队列已经为空,则会发起一次RPC向服务端请求当前scanner的后续result数据(步骤1)。客户端收到result列表之后(步骤2),通过scanResultCache把这些results内的多个cell进行重组,最终组成用户需要的result放入到Cache中(步骤3)。其中,步骤1+步骤2+步骤3统称为loadCache操作。为什么需要在步骤3对RPC response中的result进行重组呢?这是因为RegionServer为了避免被当前RPC请求耗尽资源,实现了多个维度的资源限制(例如timeout、单次RPC响应最大字节数等),一旦某个维度资源达到阈值,就马上把当前拿到的cell返回给客户端。这样客户端拿到的result可能就不是一行完整的数据,因此在步骤3需要对result进行重组。
梳理完scanner的执行流程之后,再看下Scan的几个重要的概念。
•caching:每次loadCache操作最多放caching个result到cache队列中。控制caching,也就能控制每次loadCache向服务端请求的数据量,避免出现某一次scanner.next()操作耗时极长的情况。
•batch:用户拿到的result中最多含有一行数据中的batch个cell。如果某一行有5个cell,Scan设的batch为2,那么用户会拿到3个result,每个result中cell个数依次为2,2,1。
•allowPartial:用户能容忍拿到一行部分cell的result。设置了这个属性,将跳过图4-3中的第三步重组流程,直接把服务端收到的result返回给用户。
•maxResultSize:loadCache时单次RPC操作最多拿到maxResultSize字节的结果集。
缺点:不能并发执行,如果扫描的数据分布在不同的region上面,scan不会并发执行,而是一行一行的去扫,且在步骤1和步骤2期间,client端一致在阻塞等待,所以从客户端视角来看整个扫描时间=客户端处理数据时间+服务器端扫描数据时间。
应用场景:根据上面的分析,scan API的效率很大程度上取决于扫描的数据量。通常建议OLTP业务中少量数据量扫描的scan可以使用scan API,大量数据的扫描使用scan API,扫描性能有时候并不能够得到有效保证。
最佳实践:
1.批量OLAP扫描业务建议不要使用ScanAPI,ScanAPI适用于少量数据扫描场景(OLTP场景)
2.建议所有scan尽可能都设置startkey以及stopkey减少扫描范围
3.建议所有仅需要扫描部分列的scan尽可能通过接口setFamilyMap设置列族以及列
TableScanMR
对于扫描大量数据的这类业务,HBase目前提供了两种基于MR扫描的用法,分别为TableScanMR以及SnapshotScanMR。首先来介绍TableScanMR,具体用法参考官方文档https://hbase.apache.org/book.html#mapreduce.example.read,TableScanMR的工作原理说白了就是ScanAPI的并行化。如下图所示:

TableScanMR会将scan请求根据目标region的分界进行分解,分解成多个sub-scan,每个sub-scan本质上就是一个ScanAPI。假如scan是全表扫描,那这张表有多少region,就会将这个scan分解成多个sub-scan,每个sub-scan的startkey和stopkey就是region的startkey和stopkey。
最佳实践:
1.TableScanMR设计为OLAP场景使用,因此在离线扫描时尽可能使用该种方式
2.TableScanMR原理上主要实现了ScanAPI的并行化,将scan按照region边界进行切分。这种场景下整个scan的时间基本等于最大region扫描的时间。在某些有数据倾斜的场景下可能出现某一个region上有大量待扫描数据,而其他大量region上都仅有很少的待扫描数据。这样并行化效果并不好。针对这种数据倾斜的场景TableScanMR做了平衡处理,它会将大region上的scan切分成多个小的scan使得所有分解后的scan扫描的数据量基本相当。这个优化默认是关闭的,需要设置参数”hbase.mapreduce.input.autobalance”为true。因此建议大家使用TableScanMR时将该参数设置为true。
3.尽量将扫描表中相邻的小region合并成大region,而将大region切分成稍微小点的region
SnapshotScanMR
SnapshotScanMR与TableScanMR相同都是使用MR并行化对数据进行扫描,两者用法也基本相同,直接使用TableScanMR的用法,在此基础上做部分修改即可,它们最大的区别主要有两点:
1.SnapshotScanMR扫描于原始表对应的snapshot之上(更准确来说根据snapshot restore出来的hfile),而TableScanMR扫描于原始表。
2.SnapshotScanMR直接会在客户端打开region扫描HDFS上的文件,不需要发送Scan请求给RegionServer,再有RegionServer扫描HDFS上的文件。在客户端直接扫描HDFS上的文件,这类scanner称之为ClientSideRegionScanner。

总体来看和TableScanMR工作流程基本一致,最大的不同来自region扫描HDFS这个模块,TableScanMR中这个模块来自于regionserver,而SnapshotScanMR中客户端直接绕过regionserver在客户端借用region中的扫描机制直接扫描hdfs中数据。这样做的优点如下:
1.减小对RegionServer的影响。很显然,SnapshotScanMR这种绕过RegionServer的实现方式最大限度的减小了对集群中其他业务的影响。
2.极大的提升了扫描效率。SnapshotScanMR相比TableScanMR在扫描效率上会有2倍~N倍的性能提升(下一小节对各种扫描用法性能做个对比评估)。主要原因如下:扫描的过程少了一次网络传输,对于大数据量的扫描,网络传输花费的时间是非常庞大的,这主要可能牵扯到数据的序列化以及反序列化开销。TableScanMR扫描中RegionServer很可能会成为瓶颈,而SnapshotScanMR扫描并没有这个瓶颈点。
性能对比(来自网图)

3、业界常用的数据迁移方案
Hadoop层数据迁移
Hadoop层的数据迁移主要用到DistCp(Distributed Copy), HBase的所有文件都存储在HDFS上,因此只要使用Hadoop提供的文件复制工具distcp将HBASE目录复制到同一HDFS或者其他HDFS的另一个目录中,就可以完成对源HBase集群的备份工作。
缺点:源集群需要停写,不可行。
HBase层数据迁移
- copyTable
copyTable也是属于HBase层的数据迁移工具之一,从0.94版本开始支持,以表级别进行数据迁移。通过MapReduce程序全表扫描待备份表数据并写入另一个集群,与DistCp不同的时,它是利用MR去scan 原表的数据,然后把scan出来的数据写入到目标集群的表。
缺点:全表臊面+数据深拷贝,对源表的读写性能有很大影响,效率低。需要在使用过程中限定扫描原表的速度和传输的带宽,且copyTable不保证数据一致性,在大型集群迁移上这个工具使用比较少,很难控制。
- Export/Import
此方式与CopyTable类似,主要是将HBase表数据转换成Sequence File并dump到HDFS,也涉及Scan表数据,与CopyTable相比,还多支持不同版本数据的拷贝,同时它拷贝时不是将HBase数据直接Put到目标集群表,而是先转换成文件,把文件同步到目标集群后再通过Import到线上表。
- Snapshot
Snapshot备份以快照技术为基础原理,备份过程不需要拷贝任何数据,因此对当前集群几乎没有任何影响,备份速度非常快而且可以保证数据一致性。笔者推荐在0.98之后的版本都使用Snapshot工具来完成在线备份任务。 参考: https://hbase.apache.org/book.html#ops.backup
4、Snapshot功能
常用场景
HBase在0.98版本推出在线Snapshot备份功能,使用在线snapshot备份功能常用于如下两种情况:
•全量/增量备份。
○使用场景一:通常情况下,对于重要的业务数据,建议每天执行一次Snapshot来保存数据的快照记录,并且定期清理过期快照,这样如果业务发生严重错误,可以回滚到之前的一个快照点。
○使用场景二:如果要对集群做重大升级,建议升级前对重要的表执行一次Snapshot,一旦升级有任何异常可以快速回滚到升级前。
•数据迁移
可以使用ExportSnapshot功能将快照导出到另一个集群,实现数据的迁移。
○使用场景一:机房在线迁移。比如业务集群在A机房,因为A机房机位不够或者机架不够需要将整个集群迁移到另一个容量更大的B集群,而且在迁移过程中不能停服。基本迁移思路是,先使用Snapshot在B集群恢复出一个全量数据,再使用replication技术增量复制A集群的更新数据,等待两个集群数据一致之后将客户端请求重定向到B机房。
○使用场景二:利用Snapshot将表数据导出到HDFS,再使用HiveSpark等进行离线OLAP分析,比如审计报表、月度报表等。
基本原理
Snapshot机制并不会拷贝数据,可以理解为它是原数据的一份指针。在HBase的LSM树类型系统结构下是比较容易理解的,我们知道HBase数据文件一旦落到磁盘就不再允许更新删除等原地修改操作,如果想更新删除只能追加写入新文件。这种机制下实现某个表的Snapshot,只需为当前表的所有文件分别新建一个引用(指针)。对于其他新写入的数据,重新创建一个新文件写入即可。如下图所示

实践过程
我在阿里云上搭建了一个轻量级的haddop和HBase集群,使用Snapshot功能步骤如下:
- 在目标集群上建立表结构一样的表。
$ hbase shell
hbase > create 'myTable', 'cf1', 'cf2'
- 在原集群上对表初始化数据。
$ hbase shell
hbase > put 'myTable', 'row1', 'cf1:a', 'value1'
hbase > put 'myTable', 'row2', 'cf2:b', 'value2'
hbase > scan 'myTable'
ROW COLUMN+CELL row1 column=cf1:a, timestamp=2023-08-09T16:43:10.024, value=value1 row2 column=cf2:b, timestamp=2023-08-09T16:43:20.036, value=value2
- 使用 hbase shell 在原始集群中创建一个快照。
$ hbase shell
hbase >snapshot 'myTable', 'myTableSnapshot'
这里 'myTable' 是 hbase 的表名,'myTableSnapshot' 是快照的名称。创建完成后可使用 list_snapshots 确认是否成功,或使用 delete_snapshot 删除快照。
hbase > delete_snapshot 'myTableSnapshot'
- 在源集群中导出快照到目标集群。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot myTableSnapshot -copy-to hdfs://10.0.0.38:4007/hbase/snapshot/myTableSnapshot
这里 10.0.0.38:4007 是目标集群的 **activeip:**rpcport,导出快照时系统级别会启动一个 mapreduce 的任务,可以在后面增加 -mappers 16 -bandwidth 200 来指定 mapper 和带宽。其中200指的是200MB/sec。
- 快照还原到目标集群的目标 HDFS,在目标集群中执行如下命令。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot myTableSnapshot -copy-from /hbase/snapshot/myTableSnapshot -copy-to /hbase/
- 在目标集群从 hdfs 恢复相应的 hbase 表及数据。
hbase > disable "myTable"
hbase > restore_snapshot 'myTableSnapshot'
hbase > enable 'myTable'
- 对于新表进行测试
注意事项
订单本地化HDD目前order_info_2023这张表分布在1500多个不同的region上,按照各种参考资料的理论来说,使用snapshot易超时,该如何解决这个问题?有没有什么方法能使做Snapshot更高效?网上关于这部分的资料太少,目前找不到太深入全面的解析。还有测试环境如何走这个流程?
使用snapshot注意需要申请zk、hbase-master节点的shell的管理员权限。
5、读数据时的注意事项
关于scan时缓存的设置
原理:HBase业务通常一次scan就会返回大量数据,因此客户端发起一次scan请求,实际并不会一次就将所有数据加载到本地,而是分成多次RPC请求进行加载,这样设计一方面因为大量数据请求可能会导致网络带宽严重消耗进而影响其他业务,另一方面因为数据量太大可能导致本地客户端发生OOM。在这样的设计体系下,用户会首先加载一部分数据到本地,然后遍历处理,再加载下一部分数据到本地处理,如此往复,直至所有数据都加载完成。数据加载到本地就存放在scan缓存中,默认为100条数据。通常情况下,默认的scan缓存设置是可以正常工作的。但是对于一些大scan(一次scan可能需要查询几万甚至几十万行数据),每次请求100条数据意味着一次scan需要几百甚至几千次RPC请求,这种交互的代价是很大的。因此可以考虑将scan缓存设置增大,比如设为500或者1000条可能更加合适。《HBase原理与实践》作者提到,之前做过一次试验,在一次scan 10w+条数据量的条件下,将scan缓存从100增加到1000条,可以有效降低scan请求的总体延迟,延迟降低了25%左右。
建议:大scan场景下将scan缓存从100增大到500或者1000,用以减少RPC次数。
关于离线批量读时缓存的设置
原理:通常在离线批量读取数据时会进行一次性全表扫描,一方面数据量很大,另一方面请求只会执行一次。这种场景下如果使用scan默认设置,就会将数据从HDFS加载出来放到缓存。可想而知,大量数据进入缓存必将其他实时业务热点数据挤出,其他业务不得不从HDFS加载,进而造成明显的读延迟毛刺。
建议:离线批量读取请求设置禁用缓存,scan.setCacheBlocks (false)。
四、方案设计
五、代码实现
对于HBase各种常用的DDL、DML操作的api汇总到这里
http://xingyun.jd.com/codingRoot/yanghelin3/hbase-api/
使用mapreduce方式迁移实现汇总到这里
http://xingyun.jd.com/codingRoot/yanghelin3/hbase-mapreduce/
REFERENCE
参考资料
HBase官方文档:[http://hbase.apache.org/book.html#arch.overview]
HBase官方博客:[https://blogs.apache.org/hbase]
cloudera官方HBase博客:[https://blog.cloudera.com/blog/category/hbase]
HBasecon官网:[http://hbase.apache.org/www.hbasecon.com]
HBase开发社区:[https://issues.apache.org/jira/pr
HBase中文社区:[http://hbase.group]
《Hbase原理与实践 》
snapshot功能介绍
[https://blog.cloudera.com/introduction-to-apache-hbase-snapshots/]
[https://blog.cloudera.com/introduction-to-apache-hbase-snapshots-part-2-deeper-dive/]
[https://hbase.apache.org/book.html#ops.backup]
如何使用snapshot进行复制
[https://docs.cloudera.com/documentation/enterprise/5-5-x/topics/cdh_bdr_hbase_replication.html#topic_20_11_7]
审核编辑 黄宇
-
再谈全局网HBase八大应用场景2018-04-11 0
-
HBase性能优化方法总结2018-04-20 0
-
阿里HBase的数据管道设施实践与演进2018-05-29 0
-
大数据时代数据库-云HBase架构&生态&实践2018-05-29 0
-
企业打开云HBase的正确方式,来自阿里云云数据库团队的解读2018-05-31 0
-
HBase read replicas 功能介绍系列2018-06-12 0
-
大数据学习之Hbase shell的基本操作2018-06-15 0
-
兑吧:从自建HBase迁移到阿里云HBase实战经验2018-06-19 0
-
hbase开源数据库相关模块作用2019-08-01 0
-
hbase数据库方法2019-09-18 0
-
hbase工作原理_hbase超详细介绍2017-12-27 18414
-
hbase性能测试总结2017-12-27 10099
-
HBase是什么 HBase八大应用场景介绍2018-11-11 10332
-
阿里云HBase推出普惠性高可用服务,独家支持用户的自建、混合云环境集群2019-11-14 344
-
3种常用的Elasticsearch数据迁移方案2022-04-02 4083
全部0条评论

快来发表一下你的评论吧 !
