

讨论在调整以长期社会福利为目标的机器学习所得决策方面的近期成果
人工智能
描述
作者:Lydia T. Liu、Sarah Dean、Esther Rolf、Max Simchowitz、Moritz Hardt
参与:刘天赐、晓坤
由于机器学习系统容易受到历史数据引入的偏见而导致歧视性行为,人们认为有必要在某些应用场景中用公平性准则约束系统的行为,并期待其能保护弱势群体和带来长期收益。近日,伯克利 AI 研究院发表博客,讨论了静态公平性准则的长期影响,发现结果和人们的期望相差甚远。相关论文已被 ICML 2018 大会接收。
以「最小化预测误差」为目的训练的机器学习系统通常会基于种族、性别等敏感特性(sensitive characteristics),表现出歧视性行为(discriminatory behavior),数据中的历史性偏差可能是其中的一个原因。长久以来,在诸多如贷款、雇用、刑事司法以及广告等应用场景中,机器学习一直被诟病「由于历史原因,潜在地伤害到曾被忽视的、弱势群体」。
本文讨论了研究者们在调整以长期社会福利(long term social welfare)为目标的机器学习所得决策方面的近期成果。通常,机器学习模型产生一个得分(score)来概述关于个体的信息,进而对其作出决策。例如,信用得分(credit score)总结了某人的信用历史和财务行为,来帮助银行评定其信用等级。我们以此贷款场景为例贯穿全文。任何用户群体在信用得分上都有其特定分布,如下图所示。
1. 信用得分和偿还分布
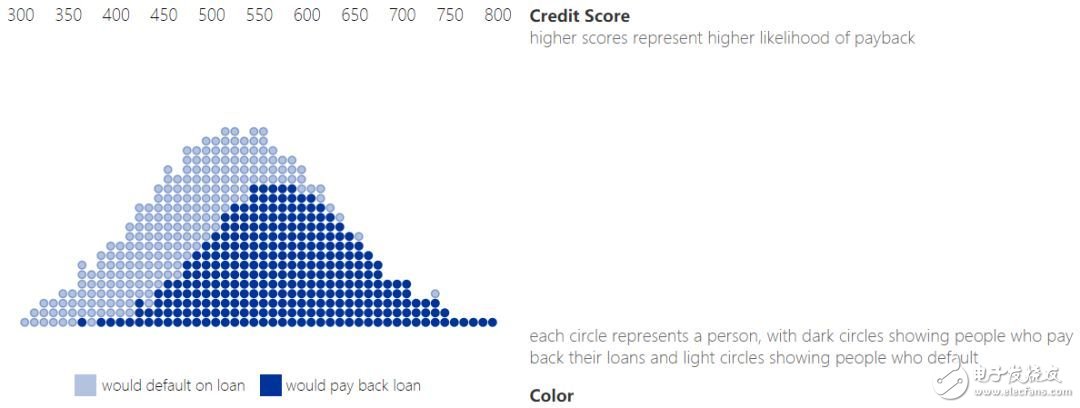
通过定义一个阈值,可以将得分转变为决策。例如,得分高于放贷阈值的人可以获得贷款,而低于放贷阈值的则被拒绝。这种决策规则叫阈值策略(threshold policy)。可以将得分理解为贷款违约的估计概率编码。例如,信用得分为 650 的人中,90% 的人会偿还其贷款。因此,银行可以预估其为信用得分为 650 的用户提供等额贷款的期望收益,同样,可以预测为信用得分高于 650(或任何给定阈值)的全体用户提供贷款的期望收益。
2. 贷款阈值和结果
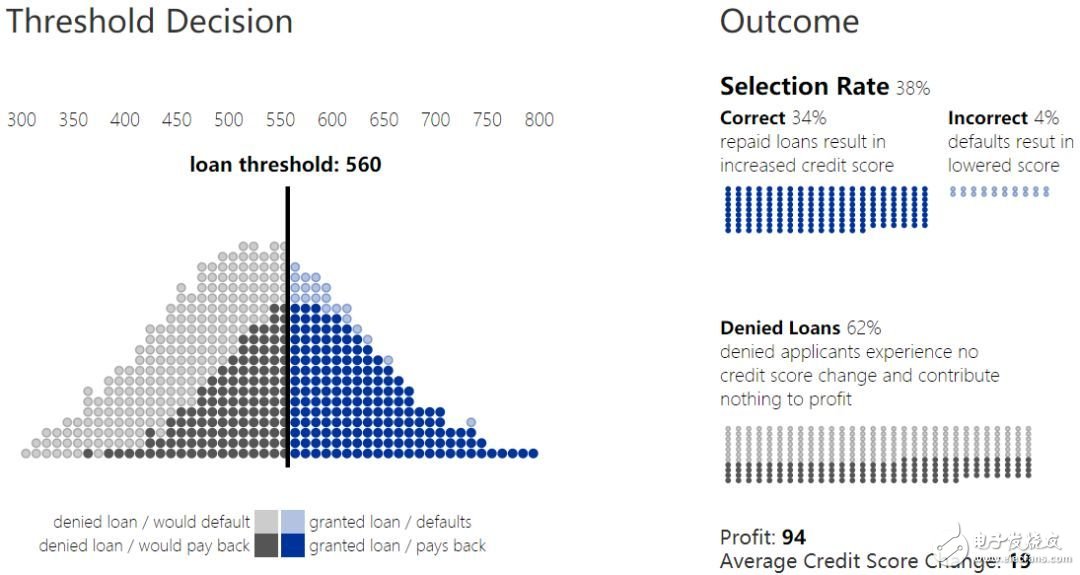
不考虑其他因素的情况下,银行会试图最大化其总收益。收益取决于收回的偿还贷款额与在贷款违约的损失额之间的比。在上图中,收益损失比为 1:-4,由于相较于收益,损失的成本更高,因此银行会更保守的进行放贷,并提高放贷阈值。我们将高于此阈值以上的总体人数占比称为选择率(selection rate)。
结果曲线
贷款决策不仅影响银行机构,也会影响个人。一次违约行为(贷款人无法偿还贷款)中,不仅是银行损失了收益,贷款人的信用得分也会降低。而成功的贷款履约行为中,银行获得收益,同时贷款人的信用得分提升。在本例中,某用户信用得分变化比为 1(履约):-2(违约)
在阈值策略中,结果(outcome)被定义为某群体得分的变化期望,可以参数化为选择率的函数,称此函数为结果曲线(outcome curve)。当某群体的选择率发生变化时,其结果也会发生变化。这些总体人数级别上的结果会同时取决于偿还概率(由得分编码得到)、成本以及个体贷款决策的收益。
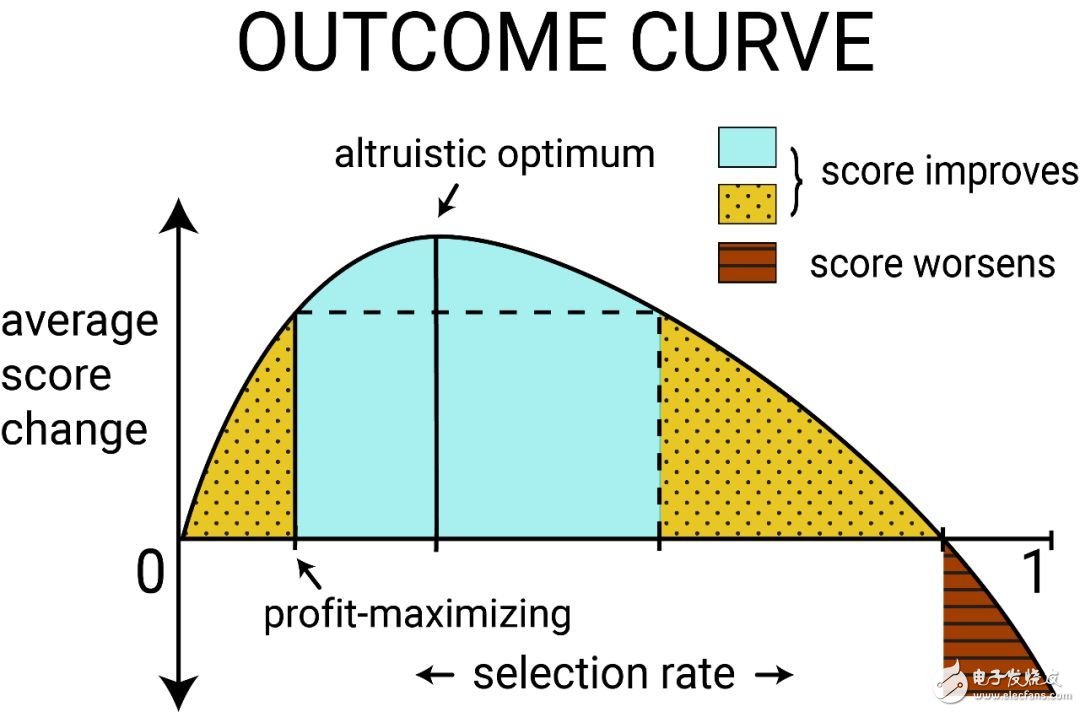
上图展示了某典型群体的结果曲线。当群体内获得贷款并成功偿还的个体足够多时,其平均信用得分就可能增加。这时,如果其平均得分变化(average score change)为正,则可得到无约束收益最大化结果。偏离收益最大化,以给更多人提供贷款时,平均得分变化会增大到最大值。称其为利他最优(altruistic optimum)。也可以将选择率提升到某个值,使平均得分变化低于无约束收益最大化时的平均得分变化、但依然为正,即图中黄色点状阴影所表示的区域。称此区域中的选择率导致了相对损害(relative harm)。但如果无法偿还贷款的用户过多,则平均得分就会降低(平均得分变化为负),从而进入红色横线阴影区域。
4. 贷款阈值和结果曲线
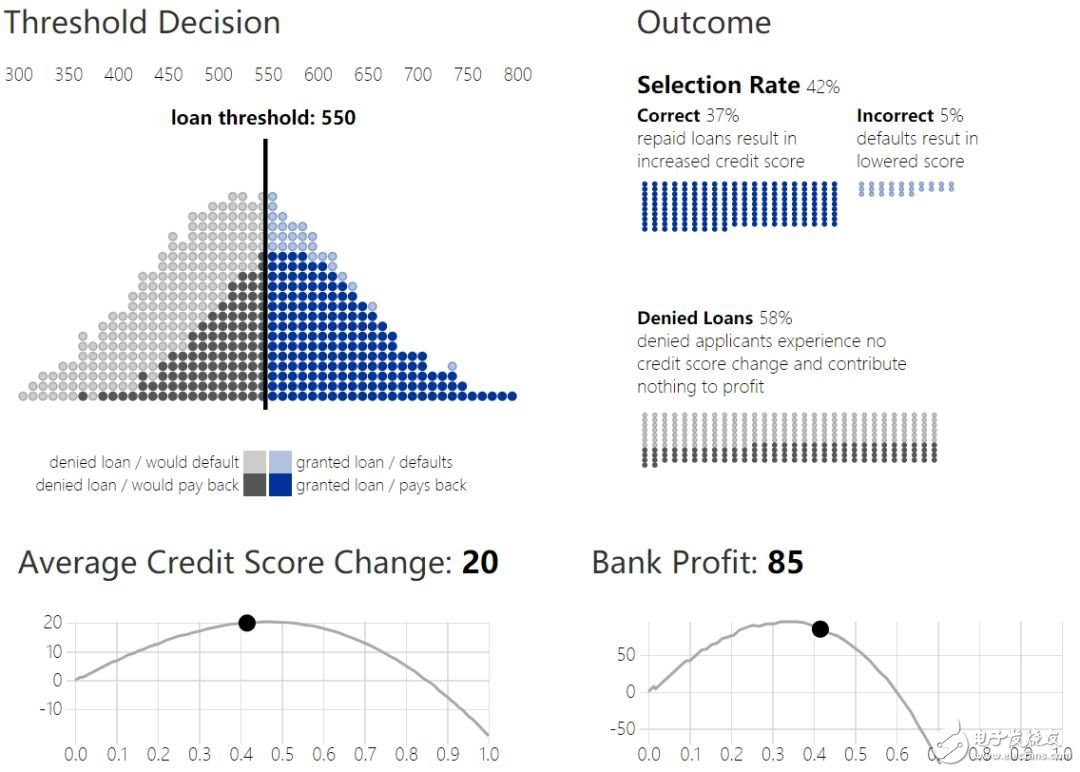
多群体情况
给定的阈值策略如何影响不同群体中的个体?两个拥有不同信用得分分布(credit score distribution)的群体会拥有不同的结果。
假设第二个群体和第一个群体的信用得分分布不同,同时群体内人数也更少,将其理解为历史弱势群体。将其表示为蓝群体,我们希望保证银行的贷款政策不会不合理地伤害、欺骗到他们。
假设银行可以对每个群体选择不同的阈值,虽然这可能面临法律挑战,但为了预防由于固定阈值决策可能带来的差别结果,基于群体的阈值是无法避免的。
5. 不同群体的贷款决策
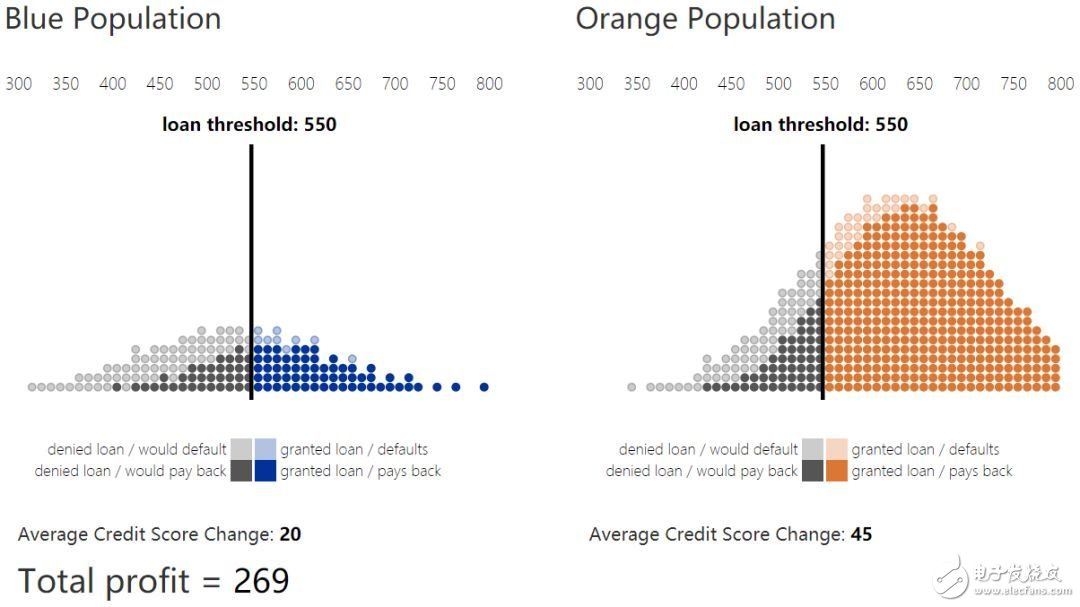
很自然的会出现问题:怎样的阈值选择可以在蓝群体的得分分布中得到期望改善。如上文所述,无约束的银行策略会最大化收益,并选取收支平衡、贷款有利可图的点。事实上,收益最大化阈值(信用得分为 580)在两个群体中是相同的。
公平性准则
拥有不同得分分布的群体会有不同形状的得分曲线(原文图 6 上半部分展示了真实信用得分数据和一个简单结果模型的结果曲线)。作为无约束收益最大化的另一个替代选择是公平性约束(fairness constraints):通过某些目标函数令不同群体的决策平等。目前已经提出了各种公平性准则,诉诸直觉来保护弱势群体。通过结果模型,我们可以正式的回答:公平性约束是否真的鼓励了更多的积极结果。
一个常见的公平性准则,人口统计平等(demographic parity),要求银行在两个群体中给出相同比例的贷款。在此要求下,银行继续尽可能最大化收益。另一个准则,机会平等(equality of opportunity):两个群体中的真阳性率(true positive rate)相等,要求银行对两个群体中会偿还贷款的个体相同的贷款比例。
虽然从要求静态决策公平的角度出发,这些准则都很合理,但它们大多忽略了这些对群体结果的未来效应。原文图 6 通过对比最大化收益、人口统计平等和机会平等下的策略结果,展示了这一点。看看每个贷款策略下银行收益和信用得分的变化。和最大化收益策略相比,人口统计平等和机会平等都降低了银行收益,但是否获得了相较于最大化收益得到提升的蓝群体结果?虽然相较于利他最优,最大化收益策略对蓝群体贷款过低,但机会平等策略则(相较于利他最优)贷款过多,人口统计平等则贷款过多,并达到了相对损害区域。
6. 有约束条件下的贷款决策模拟
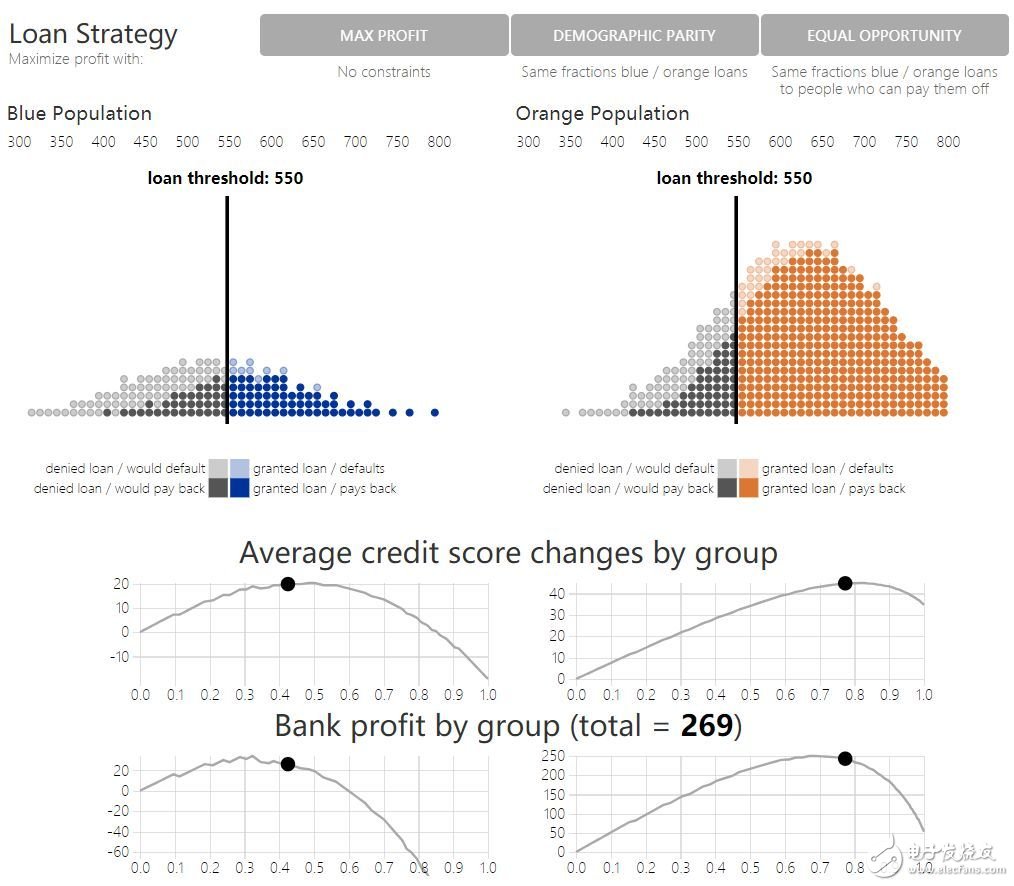
如果公平性准则的目标是「从长期来看,提升或公平化所有群体的幸福」,刚才展示的则表明在某些场景下,公平性准则实际上是违背了这一目的。换言之,公平性约束会进一步降低弱势群体中的现有福利。建立准确模型,以预测策略将对群体结果产生的效应影响,也许可以缓解由于引入公平性约束而产生的意料以外的伤害。
对「公平」机器学习结果的思考
研究者提出了一个基于长期结果的对机器学习「公平性」讨论的视角。如果没有细致的延迟结果模型,就不能来预测公平性准则作为加在分类系统上之后的影响。然而,如果有准确的结果模型,就能以相较于现有公平性准则而言,更直接的方式来优化正例结果。具体而言,结果曲线给出了偏离最大化收益策略,以最直接提升结果的方法。
结果模型是在分类过程中引入领域知识的一个具体方法,并能与许多指出机器学习中的「公平」具有背景敏感特性的研究很好地吻合。结果曲线为此应用特定的权衡过程提供了一个可解释的视觉工具。
更多细节请阅读论文原文,本文将在今年 35 届 ICML 大会上出现。本研究只是对「结果模型可以缓解机器学习算法对社会意料外影响」的初步探索。研究者们相信,未来,随着机器学习算法会影响到更多人的生活,会有更多的研究工作,来保证这些算法的长期公平性。
论文:Delayed Impact of Fair Machine Learning
论文地址:https://arxiv.org/pdf/1803.04383.pdf
-
想学习一些机器人控制方面的工作,要学习什么内容!2015-11-20 0
-
决策支持系统在电子政务中的应用2011-03-04 0
-
未来社会为何更需要搬运机器人2015-12-23 0
-
基于FPGA的实时移动目标的追踪2018-08-10 0
-
人工智能和机器学习的前世今生2018-08-27 0
-
决策树在机器学习的理论学习与实践2019-09-20 0
-
机器学习的决策树介绍2020-04-02 0
-
图形处理在多媒体技术应用方面的经验和成果2021-02-01 0
-
决策树的生成资料2023-09-08 0
-
机器学习简单运用方面的基础知识2017-11-15 1422
-
携程信息安全部在web攻击识别方面的机器学习实践之路2018-01-16 5624
-
介绍Facebook在机器学习方面的软硬件基础架构,来满足其全球规模的运算需求2018-01-24 4284
-
机器学习的决策渗透着偏见,能把决策权完全交给机器吗?2018-05-11 1482
-
深度学习:transformers的近期工作成果综述2022-10-19 662
-
机器学习技术在图像分类和目标检测上的应用2022-10-20 1782
全部0条评论

快来发表一下你的评论吧 !
