

“3D实时换脸”PyTorch实现改进版,每张图的推理时间只需0.27毫秒!
描述
此前,中科院自动化所的一篇论文《所有姿态范围内的面部替换:3D解决方案》引起广泛关注。近日,中科院的一位博士生对“3D实时换脸”论文PyTorch实现改进版,使得每张图的推理时间只需0.27毫秒,同时还增加了实时培训等功能。
2018年4月,针对如何解决所有姿势范围内的面部替换,中科院自动化所的研究人员发表了一篇论文,提出了3D实时解决方法。
近日,Github一位作者cleardusk(主页:https://github.com/cleardusk,目前是中科院自动化所的在读博士生)将“3D实时换脸”PyTorch实现改进版,每张图的推理时间只需0.27毫秒!
这一改进版本帮助Pytorch改进了论文《所有姿态范围内的面部替换:3D解决方案》中提到的方法。该论文的作者之一是来自中科院自动化所的Xiangyu Zhu,根据其个人主页上的信息,他和cleardusk博士期间的导师均是李子青教授,二人可以说是同门师兄弟。
面部对齐使面部模型适合图像并提取面部像素点的语义,已成为计算机视觉领域中的一个重要主题。此前,大多数算法都是针对中小姿态(偏角小于45度)的面部而设计的,缺乏在高达90度的大幅度姿态中对齐面部的能力,这一论文就是针对所有姿态范围内的面部替换所提出来的方法。
而此次这位博士生提出的改进版本还增加了一些额外的工作,包括实时培训、培训策略等,而不仅仅是重新实现“3D实时换脸”。更详细的内容未来将会发布在相关博客中,包括一些重要的技术细节。到目前为止,这个改进版本发布了预训练第一阶段的pytorch模型,其中包括MobileNet-V1结构、训练数据集和代码。在GeForce GTX TITAN X上,每张图像的推理时间约为0.27毫秒(输入批量为128 的情况下)。
以下是关于ALFW-2000数据集的几个训练结果(根据模型phase1_wpdc_vdc.pth.tar进行推断):
那么,改进版能实现哪些应用呢?
首先,它能够实现面部对齐。
其次是面部重塑,实现“变脸”!
如何入门:要求与用法
如果要着手尝试改进版,那么你需要:
PyTorch >= 0.4.1
Python >= 3.6 (Numpy, Scipy, Matplotlib)
Dlib (Dlib用于检测面部和标志。如果你可以提供面部边框线和标志,则无需使用Dlib。可选择性地,你可以使用两步推理策略而无需初始化这些数据。)
OpenCV(Python版,用于图像IO操作。)
# 安装顺序:
sudo pip3 安装torch torchvision。更多选择点击:https://pytorch.org
sudo pip3 安装numpy,scipy,matplotlib
sudo pip3 安装dlib==19.5.0 # 19.15+ 版本,这可能会导致与pytorch冲突,大概需要几分钟
sudo pip3 安装opencv-python版
此外,强烈建议使用Python3.6 +而不是旧版,这样可以实现更好的设计。
接下来具体用法如下:
1、复制下面这个改进版(这可能需要一些时间,因为它有点大)
https://github.com/cleardusk/3DDFA.git或者git@github.com:cleardusk/3DDFA.gitcd 3DDFA
2、使用任意图像作为输入,运行main.py:python3 main.py -f samples/test1.jpg
如果你可以在终端中看到这些输出记录,就可以成功运行它:
Dump tp samples/test1_0.ply
Dump tp samples/test1_0.mat
Save 68 3d landmarks to samples/test1_0.txt
Dump tp samples/test1_1.ply
Dump tp samples/test1_1.mat
Save 68 3d landmarks to samples/test1_1.txt
Save visualization result to samples/test1_3DDFA.jpg
因为test1.jpg有两张人脸,因此有两个mat(存储密集面顶点,可以通过Matlab渲染)和ply文件(可以由Meshlab或Microsoft 3D Builder渲染)预测。
结果samples/test1_3DDFA.jpg如下所示:
附加示例:
python3 ./main.py -f samples/emma_input.jpg --box_init=two --dlib_bbox=false
当输入批量为128 的情况下,MobileNet-V1的推理时间约为34.7毫秒,平均每张图像的推理时间约为0.27毫秒。
评估与训练资源
首先,你需要下载压缩的测试集ALFW和ALFW-2000-3D(下载链接:https://pan.baidu.com/s/1DTVGCG5k0jjjhOc8GcSLOw) ,下载后解压并将其放在根目录中。接下来,通过提供训练的模型路径来运行基准代码。我已经在models目录中提供了四个预先训练的模型。这些模型在第一阶段使用不同的损失进行训练。由于MobileNet-V1结构的高效率,模型大小约为13M。
在第一阶段,不同损失的有效性依次为:WPDC> VDC> PDC,使用VDC来微调WPDC的方法取得了最好的结果,预训练模型的性能如下所示:
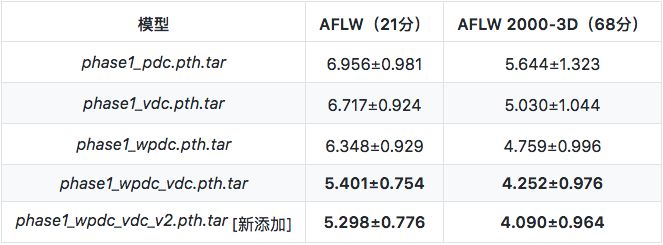
训练脚本位于training目录中,相关资源如下:
1、train.configs(217M),链接:
https://pan.baidu.com/s/1ozZVs26-xE49sF7nystrKQ#list/path=%2F,该目录与3DMM参数和训练数据集的文件列表相对应;
2、train_aug_120x120.zip(2.15G),链接:
https://pan.baidu.com/s/19QNGst2E1pRKL7Dtx_L1MA,增强训练数据集的裁剪图像;
3、test.data.zip(151M),链接:
https://pan.baidu.com/s/1DTVGCG5k0jjjhOc8GcSLOw,AFLW和ALFW-2000-3D测试集的裁剪图像;
4、model_refine.mat(160M),链接:
https://pan.baidu.com/s/1VhWYLpnxNBrlBg5_OKTojA,BFM模型
准备好训练数据集和配置文件后,进入training目录并运行bash脚本进行训练。训练参数都以bash脚本呈现。
-
设计一个延时100毫秒的延时程序2012-06-09 0
-
单片机延时3分8秒8毫秒,用你的准确度向3·8妇女节致敬!2014-03-06 0
-
求arduino nano3.0改进版(换了u***芯片)的原理图啊?2015-04-22 0
-
pwm输出控制直流电机。在软启动时占空比是变化的,每10毫秒输出一次?为什么pwm是每10毫秒输出一次?2017-09-17 0
-
最快的定时器中断能实现一毫秒吗2019-04-23 0
-
什么叫3D微波技术2019-07-02 0
-
3D TOF深度剖析2019-07-25 0
-
PYNQ框架下如何快速完成3D数据重建2021-01-07 0
-
15芯片延时一毫秒软件实现2022-01-12 0
-
微软自研触控技术 可实现延迟低于1毫秒2012-03-12 701
-
HTC回应无线套件延迟问题:2毫秒以下无疑2016-11-16 752
-
奥比中光3D人脸识别技术助力中国地铁首次实现刷脸乘车2019-04-02 616
-
AOC冠捷发布两款新游戏显示器 均为TN面板以及0.5毫秒超快响应时间2019-07-04 5425
-
奥比中光3D刷脸门锁解决方案亮相广州建博会2019-07-11 4126
-
Adobe提出DMV3D:3D生成只需30秒!让文本、图像都动起来的新方法!2024-01-30 855
全部0条评论

快来发表一下你的评论吧 !
