

一种在视觉语言导航任务中提出的新方法,来探索未知环境
电子说
描述
CVPR 2019 接收论文编号公布以来,AI科技大本营开始陆续为大家介绍一些优秀论文。今天推荐的论文,将与大家一起探讨一种在视觉语言导航任务中提出的新方法,来探索未知环境。

作者
这篇论文是 UC Santa Barbara 大学(加州大学圣巴巴拉分校)与微软研究院、Duke 大学合作完成,第一作者系 UC Santa Barbara 大学的王鑫。
据 UC Santa Barbara 计算机科学系助理教授王威廉在其个人微博上发表的喜讯,这篇论文的一作是其组内的成员,获得了 3 个 Strong Accept,在 5165 篇投稿文章中审稿得分排名第一,并且这篇论文已经确定将在 6 月的 CVPR 会议上进行报告。

这篇论文解决的任务 vision-language navigation(VLN)我们之前介绍的并不多,所以,这次营长会先给大家简单介绍 VLN,然后从这项任务存在的难点到解决方法、实验效果等方面为大家介绍,感兴趣的小伙伴们可以从文末的地址下载论文,详细阅读。
什么是 VLN?
视觉语言导航(vision-language navigation, VLN)任务指的是引导智能体或机器人在真实三维场景中能理解自然语言命令并准确执行。结合下面这张图再形象、通俗一点解释:假如智能体接收到“向右转,径直走向厨房,然后左转,经过一张桌子后进入走廊...”等一系列语言命令,它需要分析指令中的物体和动作指令,在只能看到一部分场景内容的情况下,脑补整个全局图,并正确执行命令。所以这是一个结合 NLP 和 CV 两大领域,一项非常有挑战性的任务。

难点
虽然我们理解这项任务好像不是很难,但是放到 AI 智能体上并不像我们理解起来那么容易。对 AI 智能体来说,这项任务通常存在三大难点:
难点一:跨模态的基标对准(cross-modal grounding);简单解释就是将NLP 的指令与 CV 场景相对应。
难点二:不适定反馈(ill-posed feedback);就是通常一句话里面包含多个指令,但并不是每个指令都会进行反馈,只有最终完成任务才有反馈,所以难以判断智能体是否完全按照指令完成任务。
难点三:泛化能力问题;由于环境差异大,VLN 的模型难以泛化。
那这篇论文中,作者又做了哪些工作,获得了评委们的一致青睐,获得了 3 个 Strong Accept 呢?方法来了~
方法
1、RCM(Reinforced Cross-Modal Matching)模型
针对第一和第二难点,论文提出了一种全新的强化型跨模态匹配(RCM)方法,用强化学习方法将局部和全局的场景联系起来。
RCM 模型主要由两个模块构成:推理导航器和匹配度评估器。如图所示,通过训练其中绿色的导航器,让它学会理解局部的跨模态场景,推断潜在的指令,并生成一系列动作序列。另外,论文还设置了匹配度评估器(Matching Critic)和循环重建奖励机制,用于评价原始指令与导航器生成的轨迹之间的对齐情况,帮助智能体理解语言输入,并且惩罚不符合语言指令的轨迹。

以上的方法仅仅是解决了第一个难点,所以论文还提出了一个由环境驱动的外部奖励函数,用于度量每个动作成功的信合和导航器之间的误差。
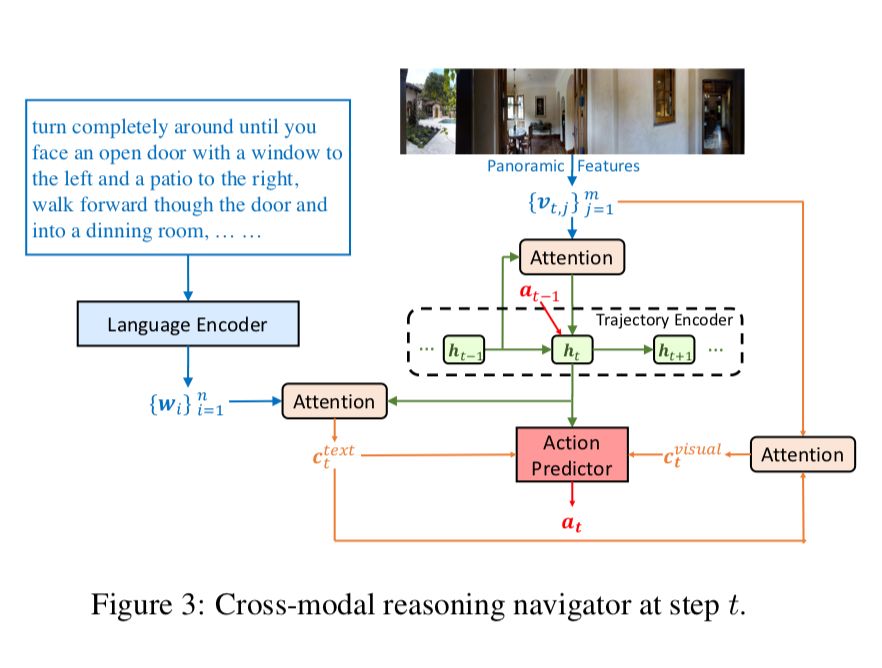
2、SIL(Self-supervised Imitation Learning)方法
为了解决第三个难点,论文提出了一种自监督模仿学习(Self-supervised Imitation Learning, SIL),其目的是让智能体能够自主的探索未知的环境。其具体做法是,对于一个从未见过的语言指令和目标位置,导航器会得到一组可能的轨迹并将其中最优的轨迹(采用匹配度评估器)保存到缓冲区中,然后匹配度评估器会使用之前介绍的循环重建奖励机制来评估轨迹,SIL方法可以与多种学习方法想结合,通过模仿自己之前的最佳表现来得到更优的策略。

测试结果
1、测试集:R2R(Room-to-Room)Dataset;视觉语言导航任务中一个真实 3D环境的数据集,包含 7189 条路径,捕捉了大部分的视觉多样性,21567 条人工注释指令,其平均长度为 29 个单词。
2、评价指标
PL:路径长度(Path Length)
NE:导航误差(Navigation Error)
OSR:Oracle 成功率(Oracle Success Rate)
SR:成功率( Success Rate)
SPL:反向路径长度的加权成功率(Success rate weighted by inverse Path Length)
3、实验对比:与 SOTA 进行对比,此前在 R2R 数据集上效果最优的方法。
Baseline:Random、seq2seq、RPA 和 Speaker-Follower。

测试结果显示,RCM 模型的效果在 SPL 指标上明显优于当前的最优结果。

并且在 SIL 方法学习后,学习效率也有明显的提高,在见过和未见过的场景验证集上,并可视化了其内部奖励指标。

论文地址:
https://arxiv.org/pdf/1811.10092.pdf

-
一种标定陀螺仪的新方法2016-08-17 0
-
一种在金上生成硫醇封端的SAM的新方法2019-10-30 0
-
分享一种中断输入和动态显示的新方法2021-06-07 0
-
一种结构化道路环境中的视觉导航系统详解2023-09-25 0
-
一种求解非线性约束优化全局最优的新方法2009-08-11 680
-
未知雷达辐射源分选的一种新方法2010-02-22 859
-
利用C语言和GEL语言的Flash编程新方法2009-03-29 1597
-
一种级数混合运算产生SPWM波新方法2017-01-07 639
-
一种设计同步时序逻辑威廉希尔官方网站 的新方法2017-02-07 891
-
PC机与单片机串行通信的一种新方法2017-09-04 872
-
一种精确测量储能成本的新方法:LCUS2020-04-06 1514
-
一种复制和粘贴URL的新方法2020-12-21 4013
-
视觉语言导航领域任务、方法和未来方向的综述2022-09-20 4230
-
一种产生激光脉冲的新方法2023-11-20 577
-
一种产生激光脉冲新方法2023-12-07 503
全部0条评论

快来发表一下你的评论吧 !
