简单情况
这种情况不常见,我们对此并不感兴趣。更常见的是需要图形工作负载之前发生的计算工作负载。这可能是某种顶点处理,计算剔除,几何图形生成或图像帧中要求的其他操作。通常顶点着色器需要这些数据,在这种情况下我们将需要在vkCmdDispatchCompute和vkCmdDrawXXX之间插入vkCmdPipelineBarrier,以实现这种事前发生的关系。
调用流程看起来如下所示:
计算调度--》Barrier(源:计算,目标:图形/顶点)-》绘制-》展示
或者可能正好相反,例如执行一些计算后处理任务。但是这意味着直接通过计算(compute)写入缓冲区,这通常不是理想的情况:片段流水线为写入帧缓冲区进行了优化,具有帧缓冲区压缩等诸多优点。
绘制-》Barrier(源:图形/片段,目标:计算)-》计算调度-》展示
可能会错误的期望会发生这样的事情,实际上如果我们只对缓冲区进行双缓冲或进行某种形式的过度同步操作,我们可能最终会失败。
如果我们使用双缓冲而不是三重缓冲则需要等待Vsync才能继续渲染,因此可能会丢失很多并行操作
————————
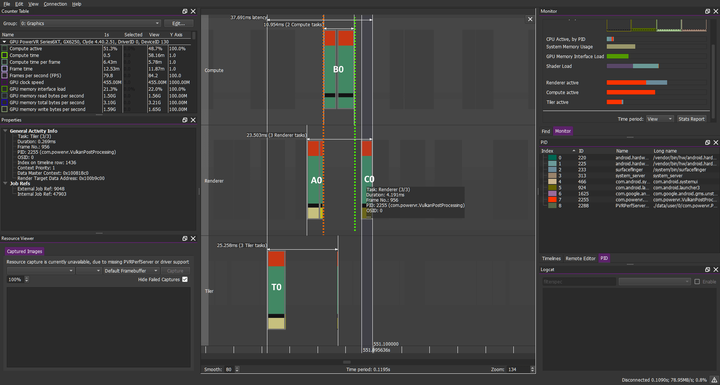
计算负载:B0 B1 B2 B3 B4.。.
图形负载:A0 A1 A2 A3 A4.。.
BARRIER计算->Vertex(橙色虚线)可正确防止AN/BN重叠->其他因素可防止AN/BN+1重叠
注:此图只是理论上的,假设满足以下条件:
我们正在使用三重缓冲
未启用Vsync或我们尚未达到硬件平台的最大FPS
如果我们正确同步并以最大Vsync fps(通常为60fps)进行同步,则这种情况变得完全有效:如果没有足够的负载要执行,GPU将更加省力甚至处于空闲状态,从而节省功耗,并且任务会像这样自然的序列化执行。在这些情况下这是有效且可取的。此处的转折点是对于低于最大FPS运行的应用程序不应该发生这种情况。
在这种情况下我们期望的重叠要好得多,如果我们使用三重缓冲并且不过度同步通常会发生什么。GPU应该能够通过下一帧(N+1)的计算操作来调度这一帧(N),因为通常不会存在Barrier来阻止这种情况的发生。如前文所述我们需要这种并行性来实现最佳性能。
————————
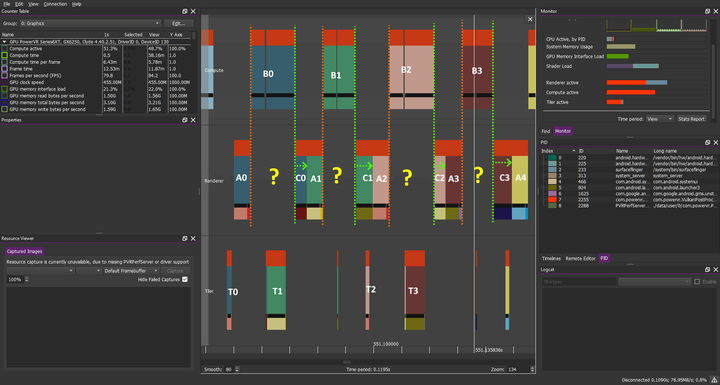
计算负载:B0 B1 B2 B3.。.
图形负载:A0 A1 A2 A3.。..

在图形之前计算,BARRIER计算顶点(橙色部分)可以正确方式AN-TN/BN的混叠,但允许BN+1/TN-AN的重叠
在绘制对象之前我们需要准备好它们,不过在很多情况下我们不需要前一帧的渲染即可渲染后一帧,因此在这种情况下GPU可以自由的允许BN+1/AN 重叠并很好的进行封装以提高性能。
简单情况
这种情况不常见,我们对此并不感兴趣。更常见的是需要图形工作负载之前发生的计算工作负载。这可能是某种顶点处理,计算剔除,几何图形生成或图像帧中要求的其他操作。通常顶点着色器需要这些数据,在这种情况下我们将需要在vkCmdDispatchCompute和vkCmdDrawXXX之间插入vkCmdPipelineBarrier,以实现这种事前发生的关系。
调用流程看起来如下所示:
计算调度--》Barrier(源:计算,目标:图形/顶点)-》绘制-》展示
或者可能正好相反,例如执行一些计算后处理任务。但是这意味着直接通过计算(compute)写入缓冲区,这通常不是理想的情况:片段流水线为写入帧缓冲区进行了优化,具有帧缓冲区压缩等诸多优点。
绘制-》Barrier(源:图形/片段,目标:计算)-》计算调度-》展示
可能会错误的期望会发生这样的事情,实际上如果我们只对缓冲区进行双缓冲或进行某种形式的过度同步操作,我们可能最终会失败。
如果我们使用双缓冲而不是三重缓冲则需要等待Vsync才能继续渲染,因此可能会丢失很多并行操作
————————
计算负载:B0 B1 B2 B3 B4.。.
图形负载:A0 A1 A2 A3 A4.。.
BARRIER计算->Vertex(橙色虚线)可正确防止AN/BN重叠->其他因素可防止AN/BN+1重叠
注:此图只是理论上的,假设满足以下条件:
我们正在使用三重缓冲
未启用Vsync或我们尚未达到硬件平台的最大FPS
如果我们正确同步并以最大Vsync fps(通常为60fps)进行同步,则这种情况变得完全有效:如果没有足够的负载要执行,GPU将更加省力甚至处于空闲状态,从而节省功耗,并且任务会像这样自然的序列化执行。在这些情况下这是有效且可取的。此处的转折点是对于低于最大FPS运行的应用程序不应该发生这种情况。
在这种情况下我们期望的重叠要好得多,如果我们使用三重缓冲并且不过度同步通常会发生什么。GPU应该能够通过下一帧(N+1)的计算操作来调度这一帧(N),因为通常不会存在Barrier来阻止这种情况的发生。如前文所述我们需要这种并行性来实现最佳性能。
————————
计算负载:B0 B1 B2 B3.。.
图形负载:A0 A1 A2 A3.。..
在图形之前计算,BARRIER计算顶点(橙色部分)可以正确方式AN-TN/BN的混叠,但允许BN+1/TN-AN的重叠
在绘制对象之前我们需要准备好它们,不过在很多情况下我们不需要前一帧的渲染即可渲染后一帧,因此在这种情况下GPU可以自由的允许BN+1/AN 重叠并很好的进行封装以提高性能。

 举报
举报


 举报
举报
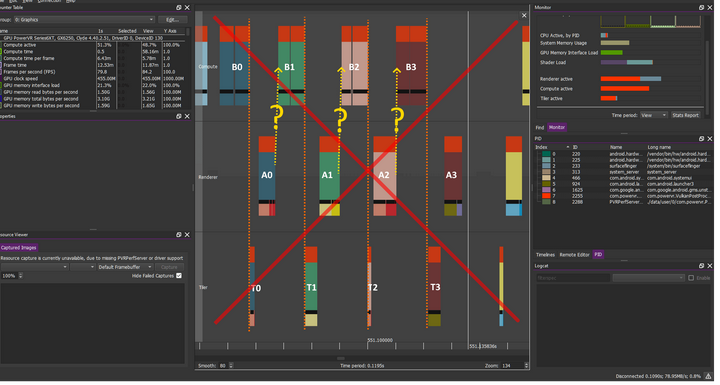
 异常琐碎的工作负载,没有同步原语会阻止不同任务的重叠,这是琐碎且罕见的情况。
异常琐碎的工作负载,没有同步原语会阻止不同任务的重叠,这是琐碎且罕见的情况。