
资料下载


基于Versal的图像恢复管道
蒲泛粟
分享资料个
描述
背景
由于我有移动地图方面的背景,我决定构建一个图像恢复管道,以改进来自汽车和无人机等移动地图系统的图像(来源)。移动地图系统通常用于从道路、城市和基础设施中获取 3D 数据。大多数移动系统使用相机和激光扫描仪来捕获 3D 数据。由于映射系统仅从一个场景中获取一张图像,因此图像质量非常重要。因此,这个想法应运而生,旨在构建一个提高图像质量的处理管道。由于移动地图的需求非常特殊,我决定构建一个更通用的解决方案,可以适应移动地图问题。
移动地图应用程序的另一个要求是能源效率。大多数系统的能源资源有限,尤其是无人机。因此,我决定密切关注系统的能耗。我认为这不仅对移动地图应用很重要,因为到 2030 年,云系统的电力消耗几乎呈指数级增长(来源)
由于 VCK5000 卡通常用于数据中心应用,而不是移动测绘汽车,因此决定将我的项目命名为“绿色计算:基于 Versal 的图像恢复管道”
介绍
本项目介绍了基于 UNet 卷积网络的图像恢复处理流水线。图像管道专为 Versal VCK5000 卡设计,并使用中型SIDD数据集进行训练。与基于 GPU 的推理相比,整个处理管道经过优化,可在以每秒帧数 (fps) 衡量的性能和准确性方面高效运行。除了流水线开发之外,还对 Versal 和 GPU 系统之间的功耗进行了详细研究。该项目的重点是涵盖三个不同的要求:
- 图像恢复管道的能耗
- 以特定的模型精度每秒处理特定数量的帧
- 可靠的推理时间和可扩展性
训练图像恢复处理以去除图像的噪声,如下例所示。图像管道针对智能手机相机图像进行了优化。一个可能的应用可能是基于云的图像增强服务。
该项目开发的 VCK5000 图像恢复管道在性能 (fps) 和功耗方面均优于最先进的 GPU。除了性能分析之外,详细的分析还显示了不同的训练和量化步骤如何影响卷积网络的准确性。分析并不固定于特定的模型或网络,所需的步骤可以很容易地适应自定义应用程序。由 Versal VCK5000 处理的最终网络在论文和代码(2022 年 3 月 30 日)上排名前 15 位“SIDD 上的图像去噪”网络。
网络优化后,对 Versal 系统进行详细的功率分析。Versal 系统的功耗与基于 GPU 的推理进行了比较。
限制:除了推理任务外,神经网络的训练和预处理对能量的要求也很高。这项工作的重点是运行时功耗和推理性能。训练和预处理的分析主要取决于训练数据集的大小(作者的意见),不属于本项目的一部分。
项目概况
代码结构的灵感来自 Xilinx/AMD Vitis-ai 教程。所有需要的步骤都被分成不同的 python 或 shell 脚本。脚本 run_all.sh 处理所有步骤以获取整个处理管道。
网络
用于管道的 UNet 网络最初是由弗莱堡大学开发的。该网络最初是为生物医学图像分割任务而设计的。除了分割任务外,UNet 结构还可用于图像恢复。本文提出了一种基于 UNet 的图像恢复网络,该网络在图像恢复任务中优于当前网络。
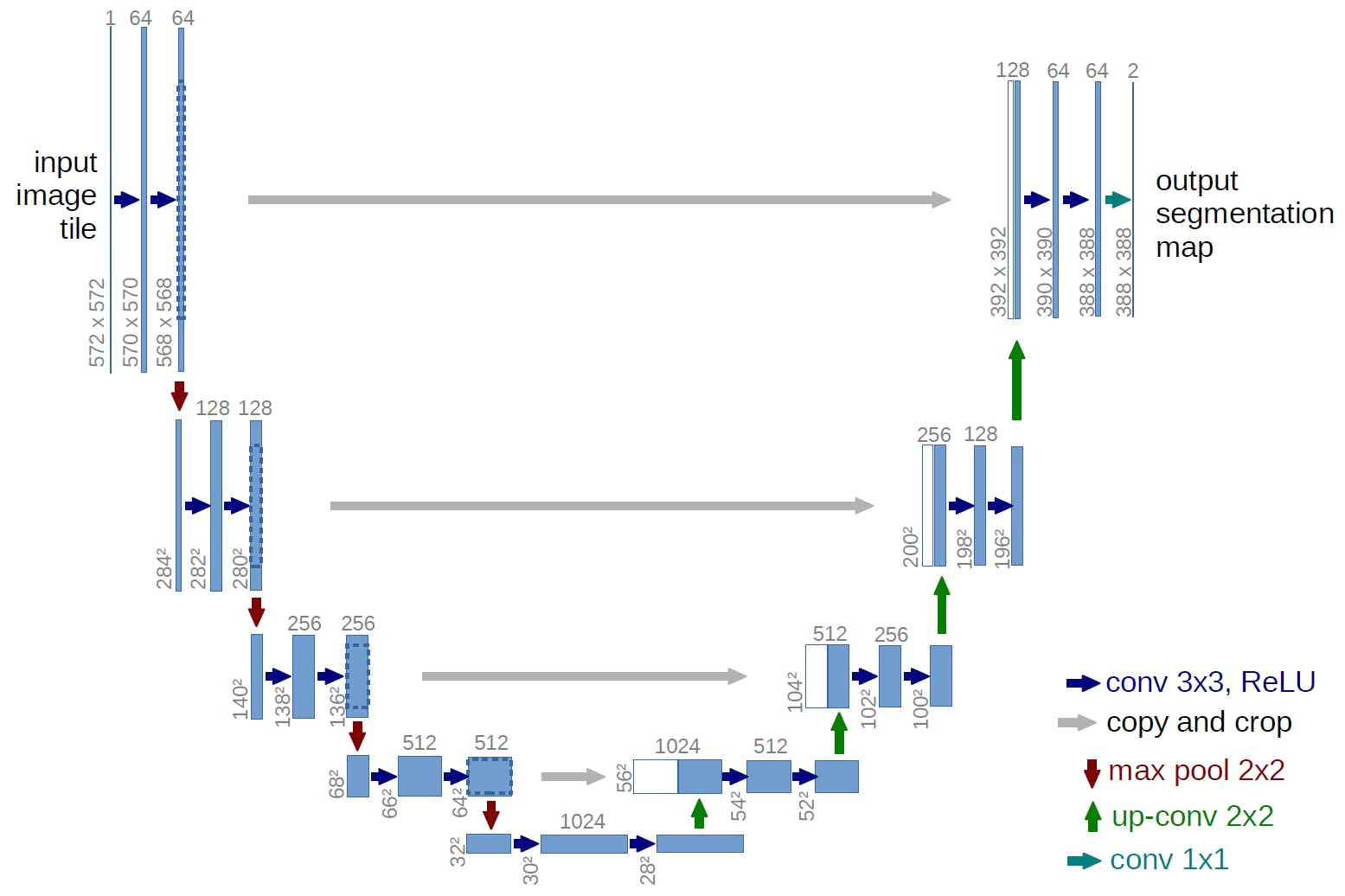
资料来源:弗莱堡大学
该网络是完全卷积的,呈 u 形。“U”的左侧是收缩路径,右侧是扩张路径。UNet 的一个重要特点是上采样部分有大量的特征通道,这使得网络可以将上下文信息传播到更高分辨率的层。
SIDD-数据集
SIDD 是“智能手机图像去噪数据集”的简称。数据集包含使用智能手机相机获得的原始(嘈杂)和处理(真实)图像,并提供三种不同尺寸(小、中、全)。该项目使用大约 20 GB 的中等大小,包含 96.000 张用于训练的图像和 1280 张用于验证的图像。


PSNR/SSIM
用人眼比较图像是很困难的,尤其是在差异很小的时候。在这项工作中,PSNR/SSIM 度量用于比较图像。
峰值信噪比 (PSNR) 用作原始图像和压缩图像之间的质量度量,其单位是分贝 (dB)。由于 PSNR 用于比较 UNet 输出与 ground-truth 图像,因此他的值是比较不同量化方法的一个很好的指标。(来源)。对于训练,我们将来自 UNet 输出的 PSNR 值与相应的真实图像进行比较。
结构相似度指数 (SSIM) 度量用于测量两个给定图像之间的相似度。两个图像之间的比较是在三个基本特征上进行的:亮度、对比度和结构。分别比较这三个特征并进行相等加权以获得比较图像的每个像素的 SSIM 值。( Source ) SSIM 输出范围是从 0 到 1。SSIM 为 1 表示两个图像相同。相反,SSIM 度量为 0 意味着两个图像完全不同。对于训练,我们将来自 UNet 输出的 SSIM 值与相应的真实图像进行比较。
个人电脑系统
PC 系统必须能够运行 RTX3090 和 VCK5000 卡。VCK5000 需要 Ubuntu 18.04(内核 5.8)才能启动和运行。内核版本是使卡运行所必需的。见黑客邮报。为确保功耗相当,两张卡的测量必须使用相同的设置。PC系统的详细配置如下:
- AMD 锐龙 ThreadRipper PRO 3955WX
- 华硕 WRX80 Pro WS Sage SE Wifi(BIOS:PCIe 通道为 3.0)
- 64 GB DDR4 内存
- 华硕 RTX3090 TUF
- 适用于 AMD Ryzen ThreadRipper PRO 的 Ubuntu 18.04(内核 5.8)补丁
- Vitis-AI 1.4.1
- 1200 瓦铂金 PSU
功率计
为了在推断时测量系统的功耗,使用了hama功率计。该功率计用于连续功率测量。功率计可以记录特定时间内的能源消耗并总结能源需求。所有设置的典型测量周期为 1、5 小时。为避免测量中出现初始功率峰值,推理任务运行 2、5 小时。30 分钟后开始功率测量。
FPGA 上的 AI 推理
本章简要介绍了 AI 推理,本文更深入,并提供了有关 FPGA 及其用例的更多详细信息。由于神经网络主要使用浮点数,FPGA 无法直接运行神经网络推理。浮点处理引擎的时钟速度较慢,并且在 FPGA 设备上的可用性较低。这就是为什么必须对神经网络进行量化以进行 FPGA 推理的原因之一。
UNet培训
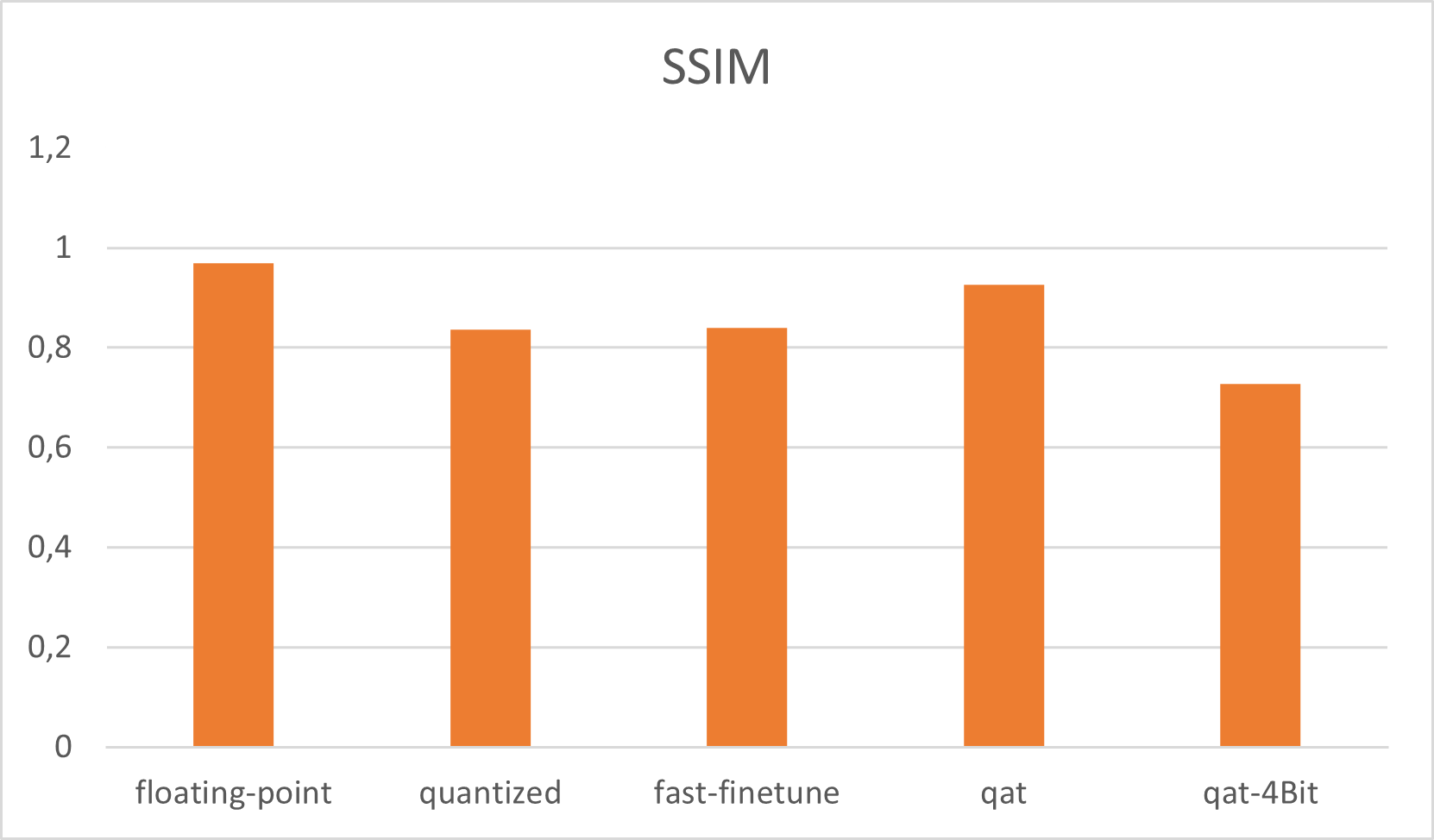
在用 250 个 Epoch 训练 UNet 网络之后,使用 SIDD Medium 数据集训练 UNet 网络。最佳 PSNR 值为39,epoch 228 为 5937 dB。最佳模型权重的 SSIM 为 0,968954。如果网络在 GPU 上以浮点模式处理,这是我们可以获得的最佳输出结果。训练 UNet 网络是 run_all.sh 中的第一步
训练量化后的 UNet
量化是指以低于浮点精度的位宽执行计算和存储张量的技术。量化模型使用整数而不是浮点值对张量执行部分或全部操作。网络参数的量化通常在训练之后进行,通常会导致精度损失。运行正常量化,UNet PSNR 降低到 27,761646 dB SSIM 为 0,836058。UNet 网络的量化是 run_all.sh 中的第二步
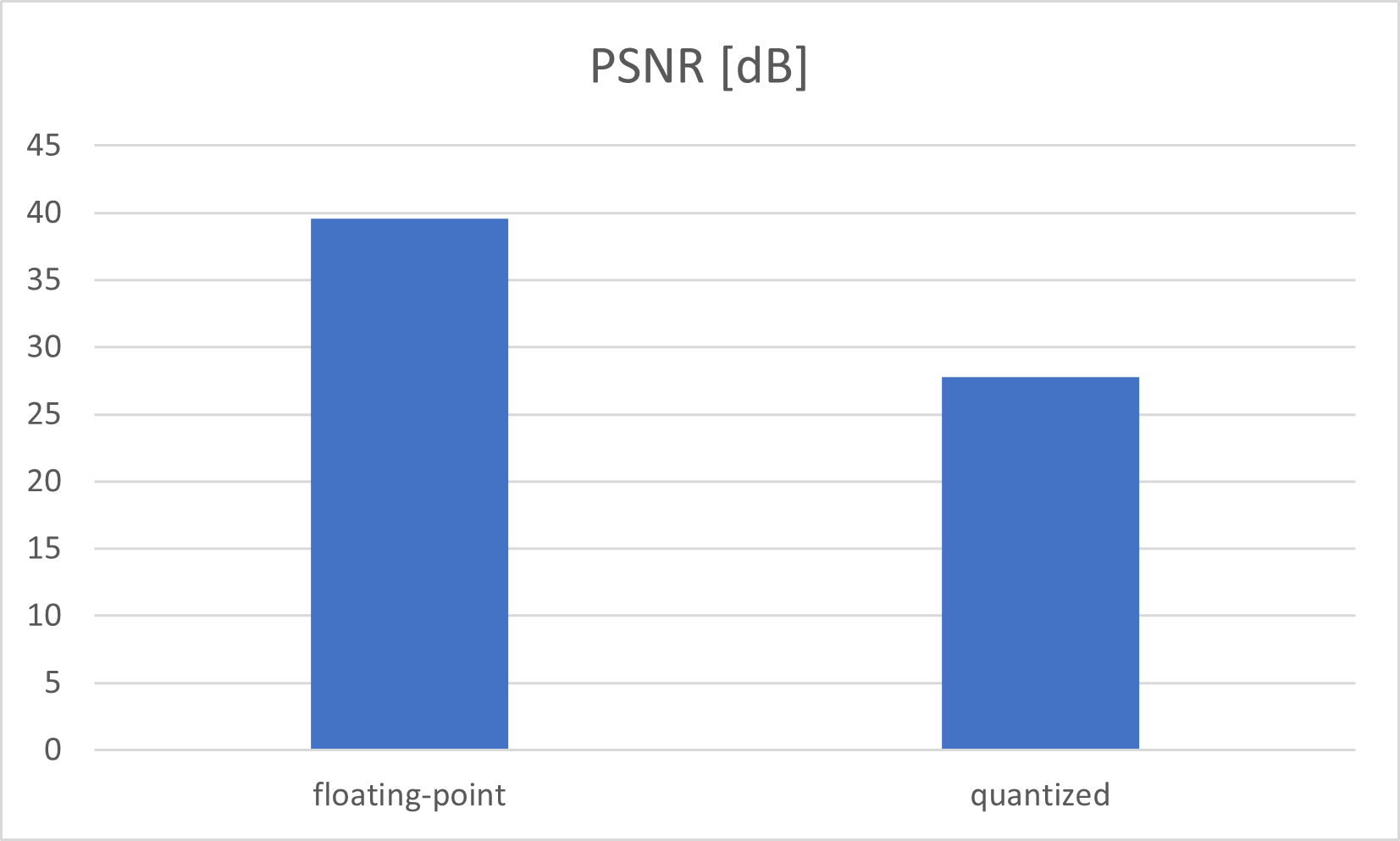
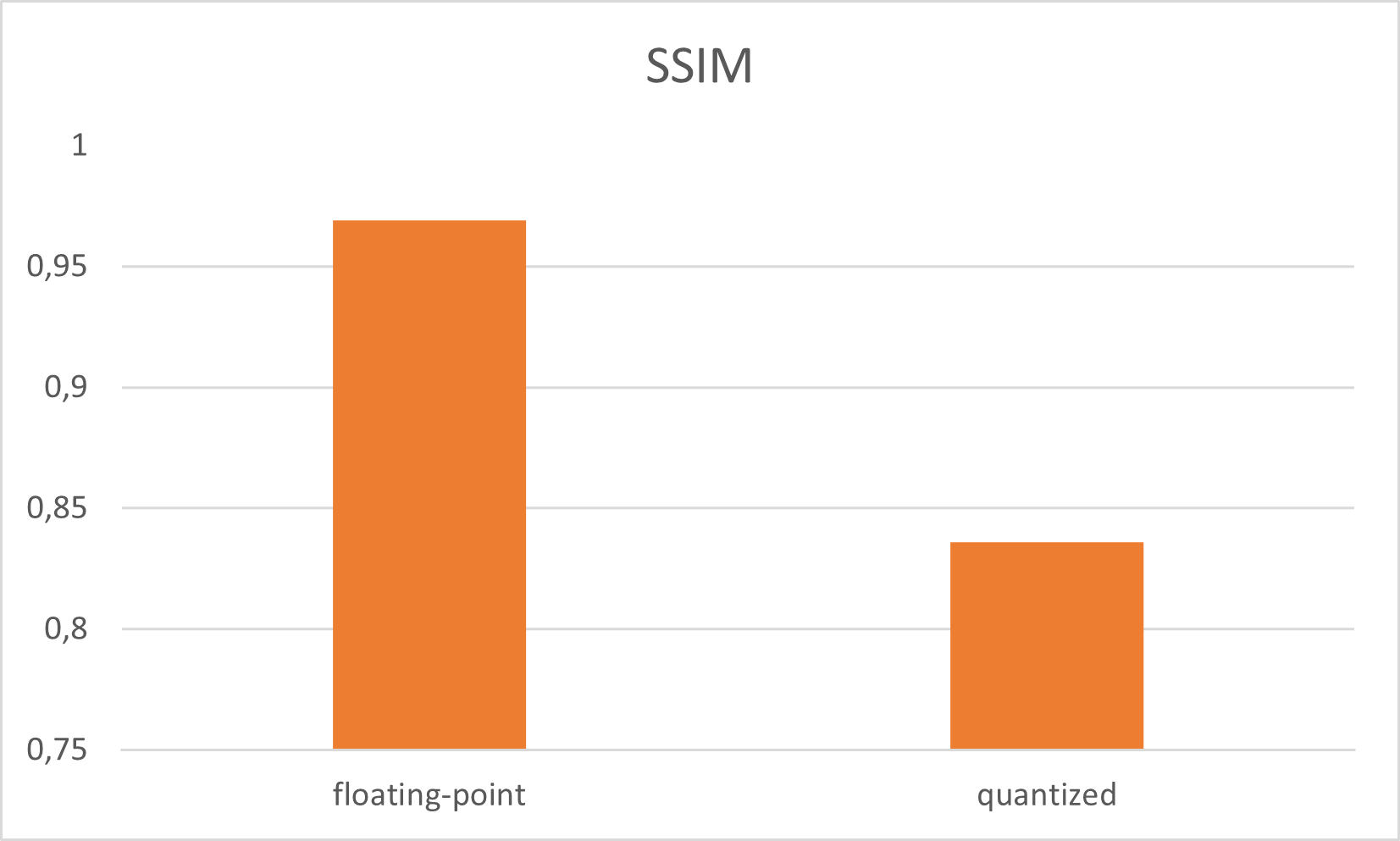
UNet 量化快速微调
正如我们所看到的,量化导致了 12 dB 的精度损失,那么我们需要改进量化结果。Vitis-Ai 提供“快速微调”以提高准确性:基于AdaQuant算法的过程。那么网络输出结果稍微好一点(PSNR: 28, 352730 ; SSIM: 0, 838978)。UNet网络的这个Fastfine-tune是run_all.sh中的第三步
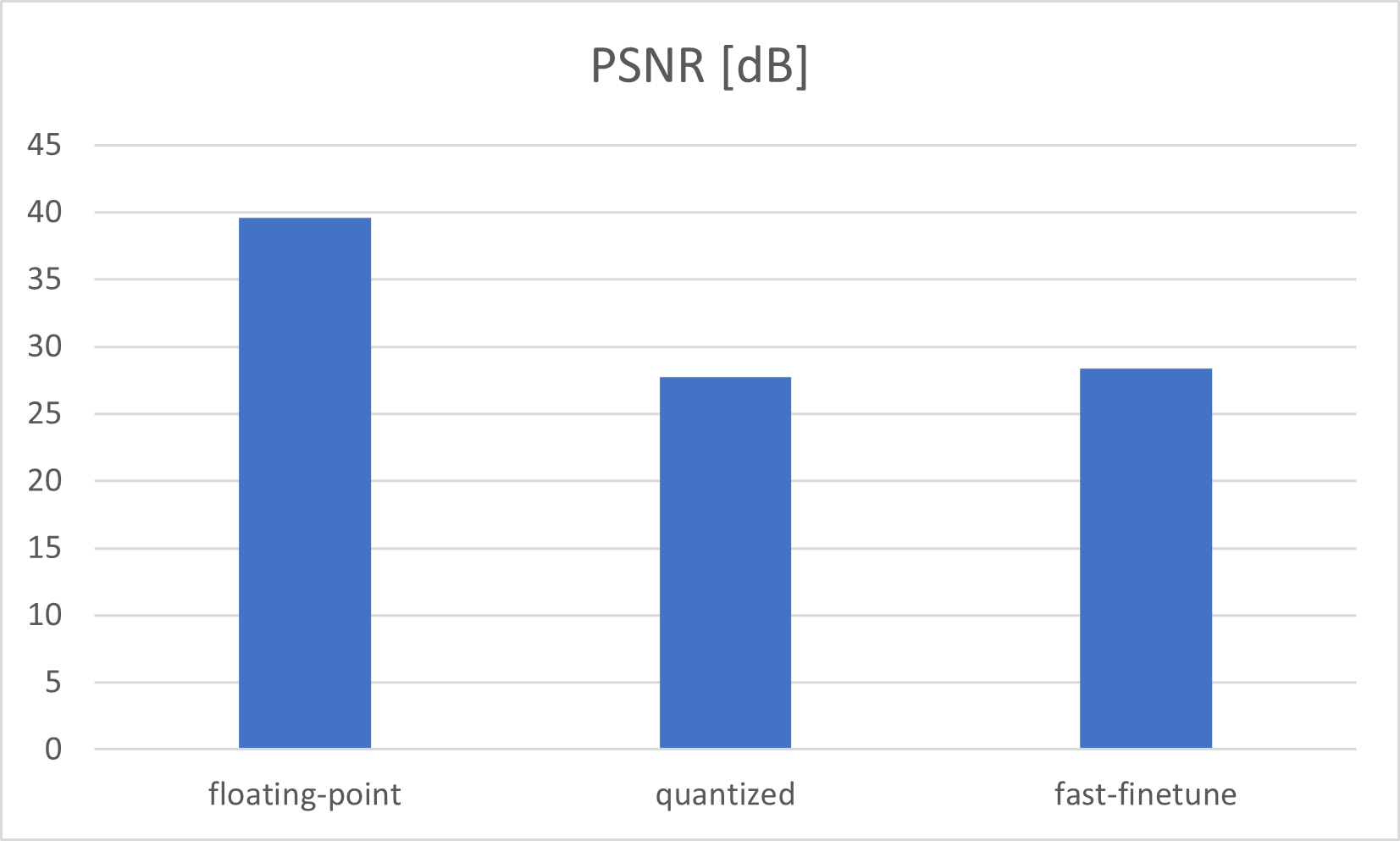
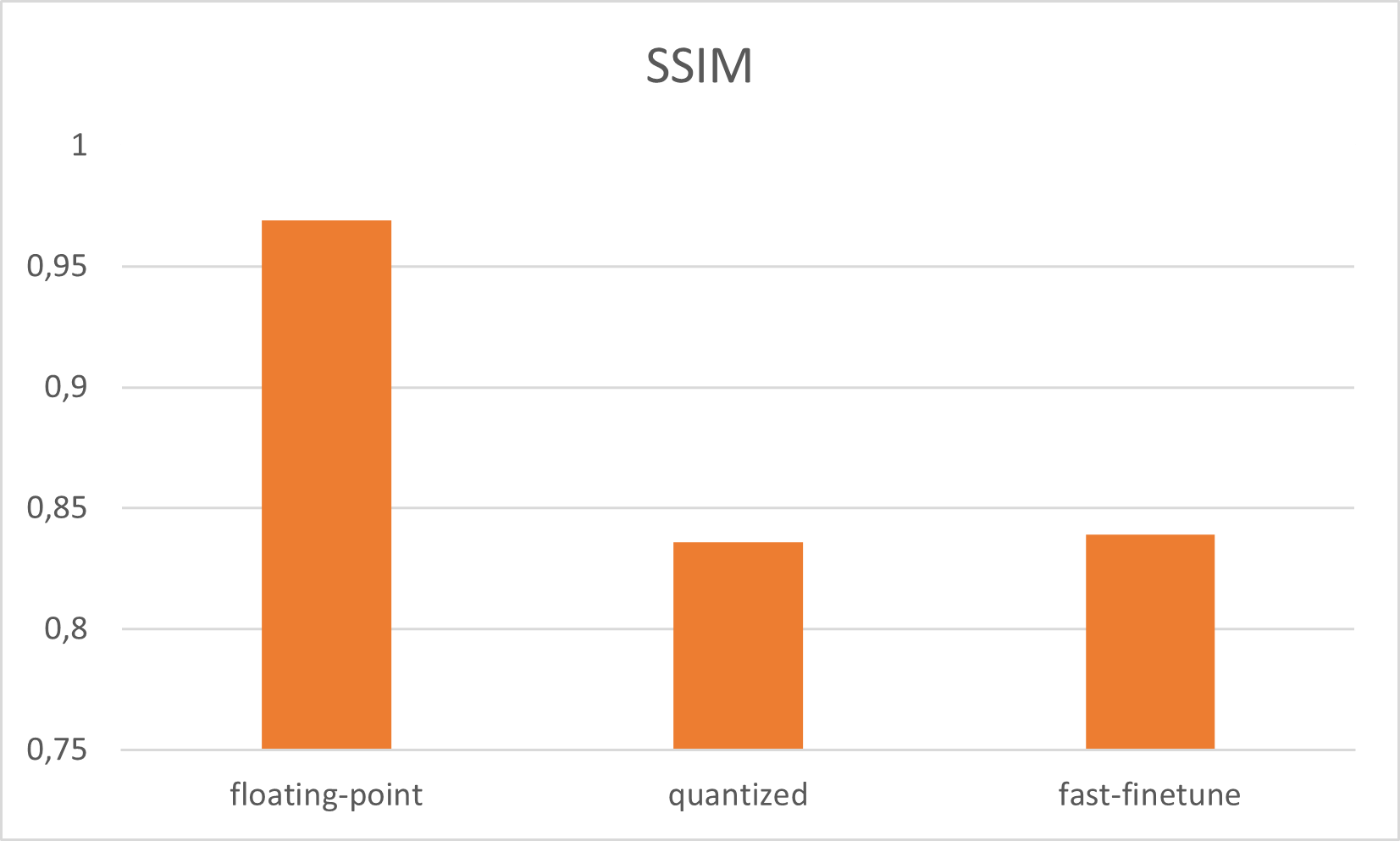
UNet 量化感知训练
之前的两种方法都是使用最终训练的浮点网络作为输入来描述的。本节中描述的第三种方法是从头开始训练网络。量化感知训练(qat)的机制很简单:它在浮点模型到量化整数模型转换过程中发生量化的地方放置量化模块,即量化和反量化模块,以模拟整数值。假量化模块还将监控权重和激活的比例和零点。一旦量化感知训练完成,浮点模型可以立即使用存储在假量化模块中的信息转换为量化整数模型。与其他量化技术相比,qat 从下往上训练网络。
要使用 qat,我们必须修改网络结构以启用 Xilinx QatProcessor。QatProcessor 自动插入所有假层并将浮点数转换为整数。(来源) 我们对模型进行了两个主要的修改:
- 所有可量化的操作都必须是 torch.nn.Module 的实例
- 所有图层必须具有唯一的名称
此时,重要的是在准备 qat 时仔细检查浮点模型的性能,以确保模型以正确的方式工作。模型源代码可以在项目的 GitHub 存储库中找到。我用正常的浮点训练重新训练了 qat 模型,并仔细检查了输出性能。对于 UNet 图像,Restauration 管道量化感知训练将模型输出提高到 PSNR:33、6874 dB 和 SSIM:0、925673。要为 UNet 运行 qat,请在 run_all.sh 中使用 qat.py
与浮点模型相比,使用 qat 进行模型训练的准确性更高。正常量化和 fast_finetune 没有得到模型参数来生成浮点精度。但是使用 qat,我们可以更接近完美的模型输出。Vitis-Ai 模型 Zoo 也使用 qat 进行训练,因此赛灵思为您完成了 qat 训练工作。
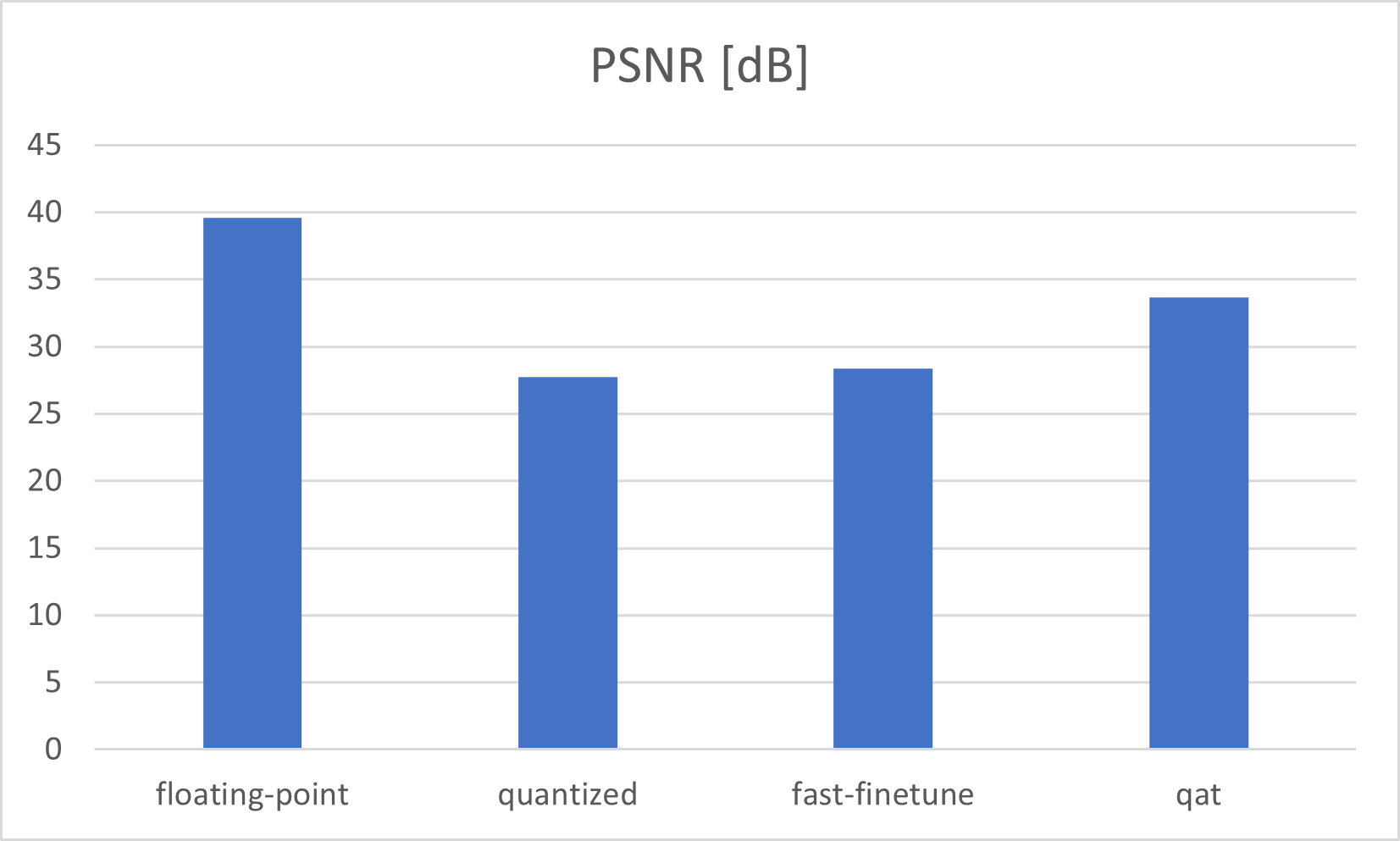
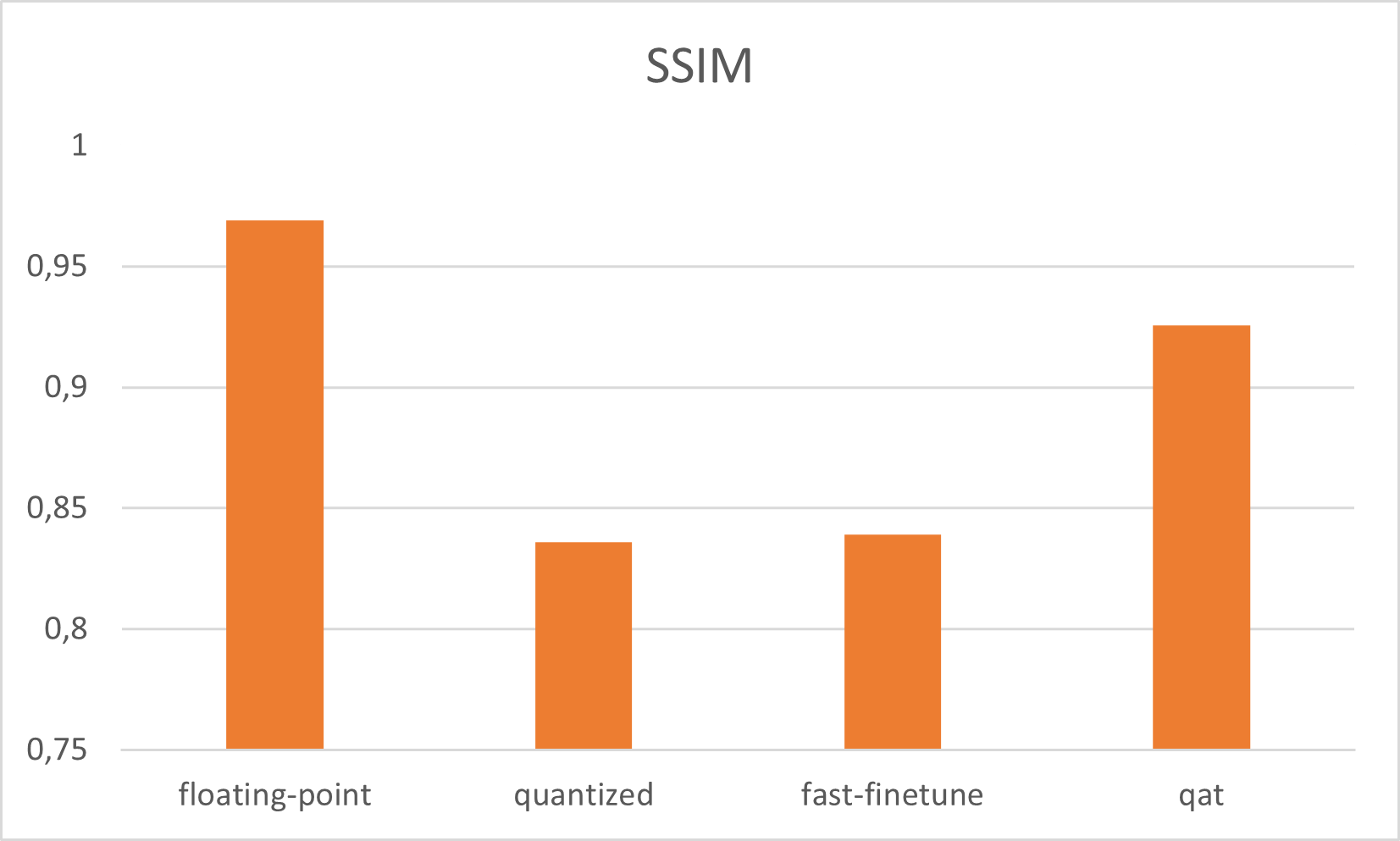
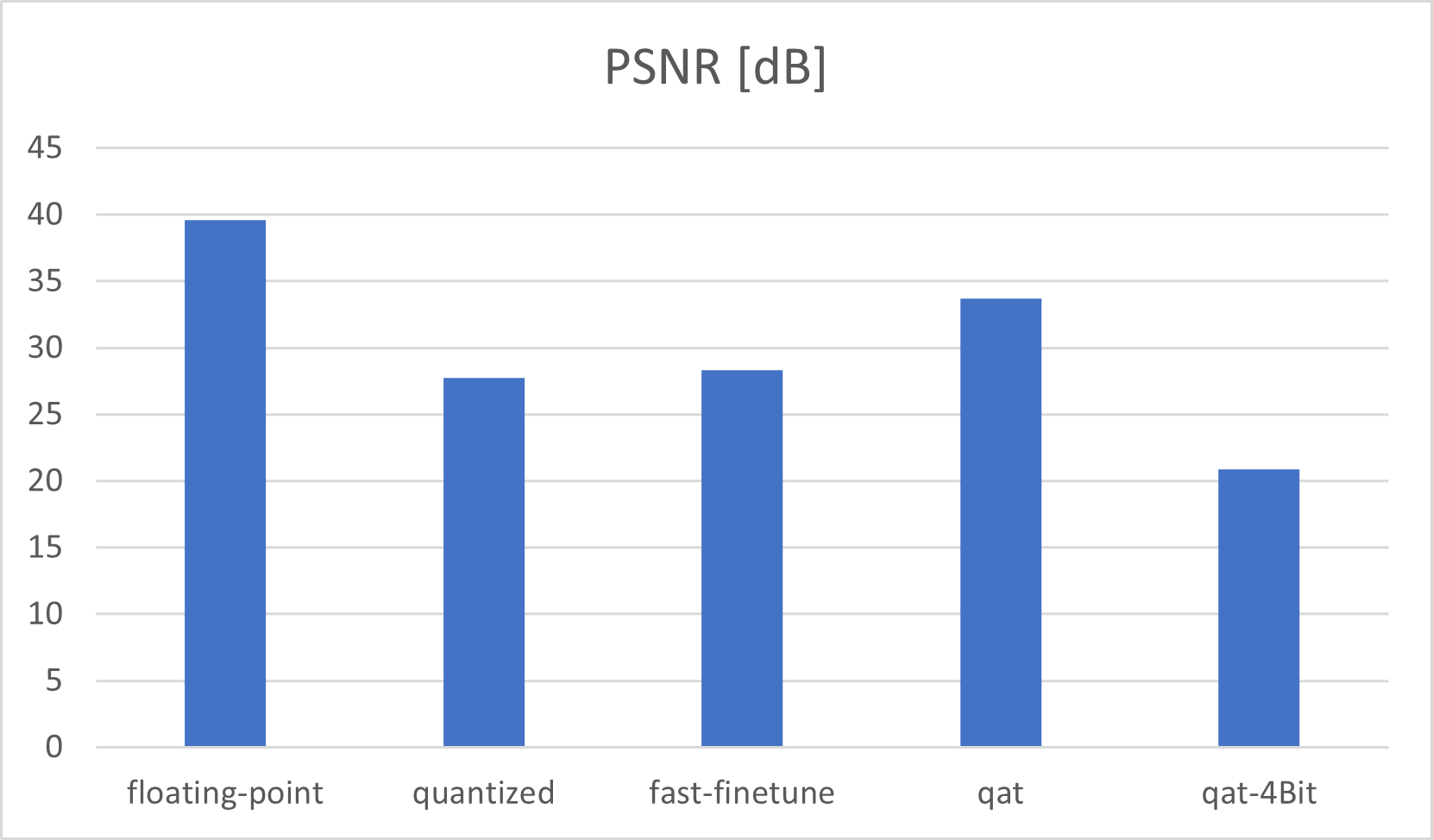
UNet 量化感知训练 4Bit
qat 量化位宽为八位。但是如果我们想要更多的吞吐量来处理更多的帧,我们可以拖尾到四位。减少位宽会导致模型不太准确。但是将模型参数减少到四位会导致更快的执行时间。这一步是可选的,因为我们只在 VCK5000 卡上测试 8 位的 qat 输出性能。更改 qat bit_width 是对 QatProcessor (Source) 的输入参数的简单修改,必须更改。具有四位的 Qat 给出 PSNR:20、8743 dB 和 SSIM:0、728075
推理性能 VCK5000 与 RTX3090 GPU
将 GPU 性能与 FPGA 进行比较并不像听起来那么简单。GPU 的推理任务不同。GPU 任务由软件 (CUDA) 安排,因为我们使用的是 Nvidia RTX3090 GPU。底层调度程序将任务添加到张量或 CUDA 核心。调度器还尝试优化从主 GPU 内存到本地核心内存的数据复制过程,以最大限度地提高核心效率,但这是一个完全不同的问题。(来源,来源)
一般来说,数据复制对于 GPU 或 FPGA 来说是一项耗时的任务,尤其是从主机内存复制数据到设备内存,而在嵌入式设备上这种行为是不同的。RTX3090 GPU 使用 PCIe 4.0 x16,而 VCK5000 使用 PCIe 3.0 x16。为了平衡从主机内存到 PCIe 设备的数据速率,所有 PCIe 通道都通过 BIOS 配置为 PCIe 3.0。PC 系统在没有显示器的情况下运行以减少外部 GPU 负载。
但最终,人工智能推理任务的典型应用需求可以是:
- 能源消耗
- 以特定的模型精度每秒处理特定数量的帧
- 可靠的推理时间和可扩展性
测试设置

推理能耗 VCK5000 vs. RTX3090 GPU
重要提示:VCK5000 正在处理量化的 UNet 网络,而 GPU 正在处理浮点 UNet 网络。
为了在推断时测量能耗,使用了 hama 功率计。推理在 2000 个输入图像的循环中运行。输出图像保存在内部 SSD 上。GPU 处理训练好的浮点模型,CUDA 支持批量大小 1。VCK5000 在 Gen3x16 模式下以 8PE@350 MHz 处理批量大小 1 的 qat 模型。得到的性能不是原始的理论吞吐量,因为网络输出被检查并保存在系统 SSD 上。
仅在一个设备(GPU 或 FPGA)运行时测量功耗。最大限度地减少冷却(源)的强大影响,每个设备都在同一个 PCIe 插槽中进行测量,以使两个设备具有相同的环境条件。室温由记录仪测量,大致恒定在 19、5 摄氏度。所有值 Power, FPS 每 20 分钟手动捕获一次。
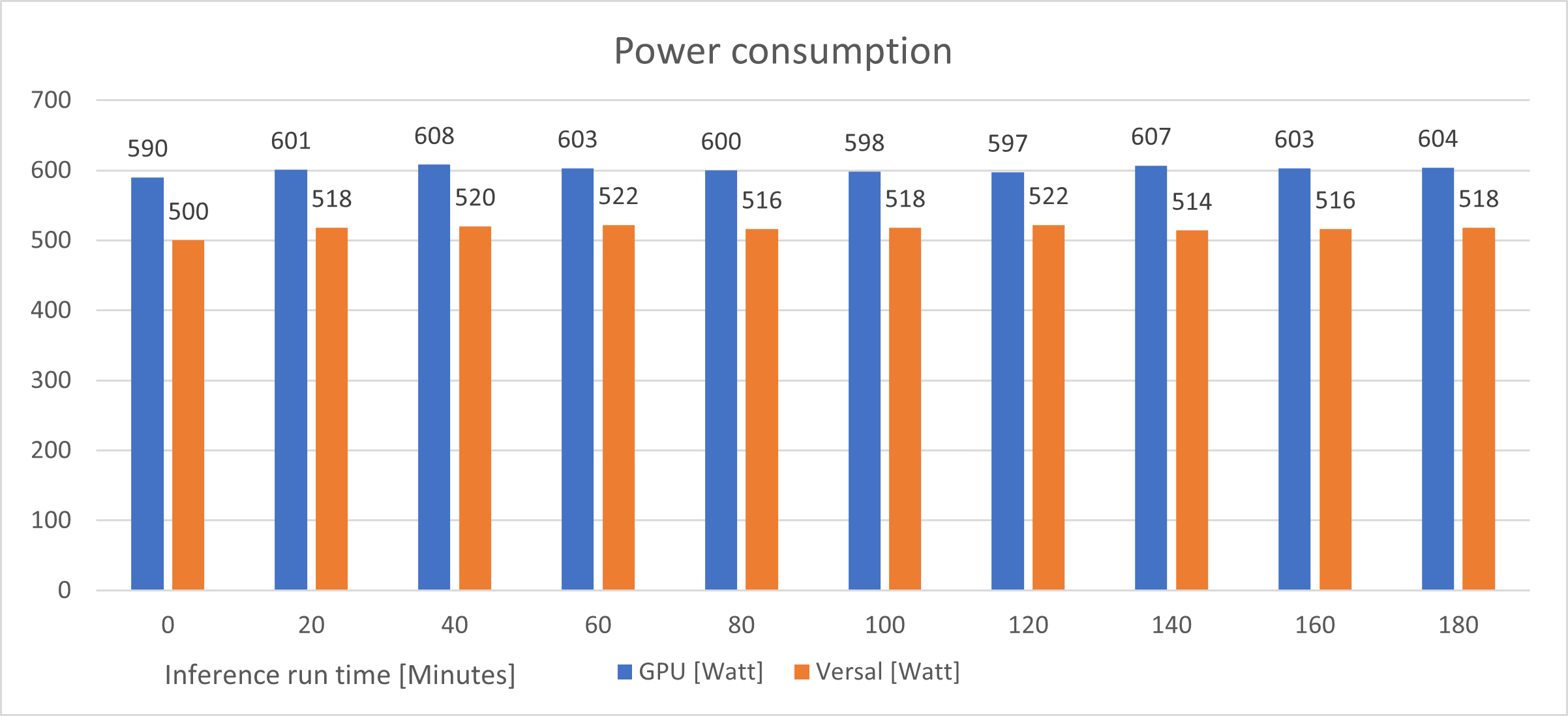
该图显示 Versal 系统比 GPU 更节能。平均功耗比 GPU 低 80 瓦。
推理 FPS VCK5000 与 RTX3090 GPU
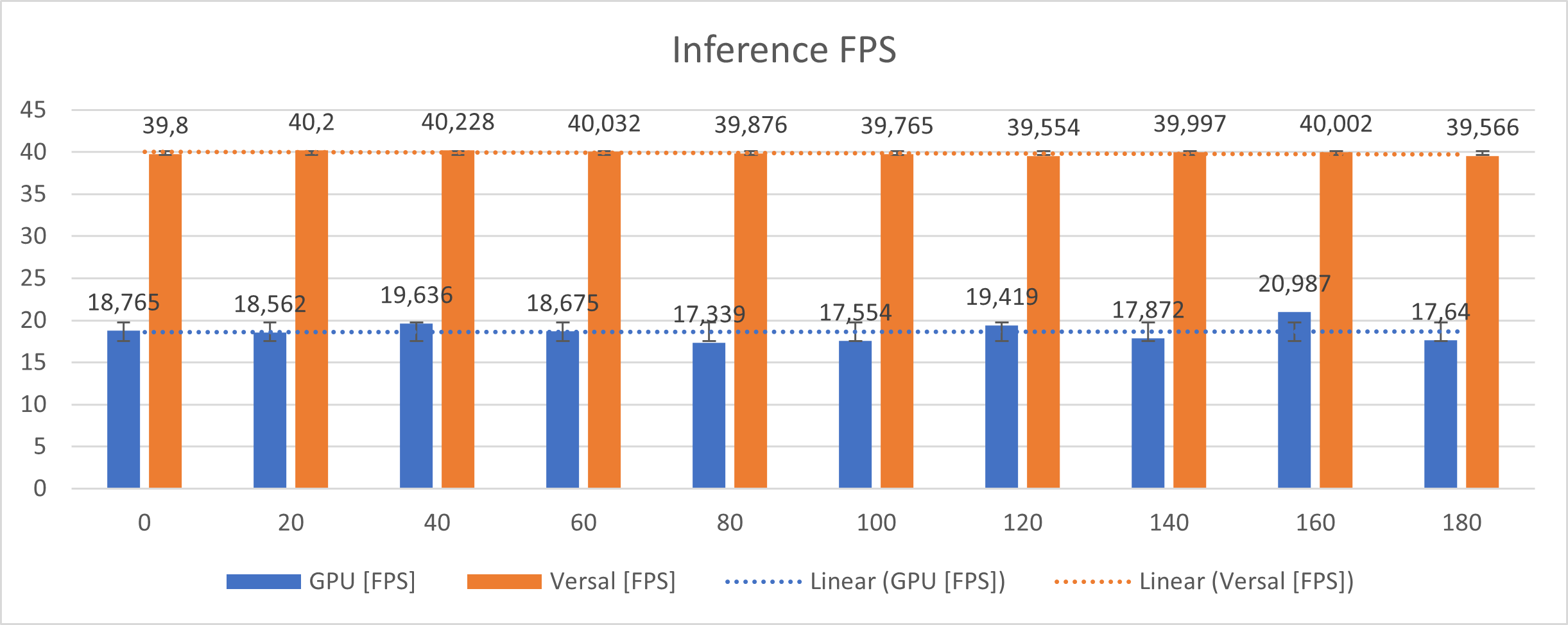
除了功耗之外,还测量了处理能力。该图显示 GPU 以接近 18 FPS 的速度运行,但存在抖动。VCK5000 每秒处理近 40 张图像。每秒处理帧数的标准差:
- GPU: 1, 134 FPS
- Versal: 0, 2344 FPS
未来的工作
该项目只是优化 UNet 管道以提高准确性和功率效率的开始。以下主题可以作为后续改进处理管道:
图像预处理
目前,输入图像由 CPU 预处理以适合作为网络输入。此任务可以在 Versal VCK5000 上轻松实现。
直接 Versal 存储
通过 PCIe DMA 传输将输入图像直接加载到 VCK5000 内存,减少 CPU 读取和写入图像的负载。可以添加直接存储作为图像预处理的顶部,从而消除 AI 处理任务完成的 CPU 负载。微软为 GPU 实现了直接存储(来源)。
批处理和流水线
VCK5000 的内部数据流可以通过流水线图像加载、预处理、人工智能推理和图像存储进行优化。在理想情况下,在 VCK5000 上同时在不同阶段处理四个图像。
结论
该项目的第一部分是最先进的图像恢复管道。流水线可由 VCK5000 Versal 加速卡处理。与其他最先进的网络相比,PSNR 为 33, 6874 和 SSIM 为 0, 925673 的管道在 TOP 15(来源,来源)中的两个指标均排名(日期:03/30/2022 ) 处理 SSID 数据集的网络。
另一方面,开发人员、系统架构师和所有对 FPGA 推理感兴趣的人都可以使用这个项目作为起点来检查他们的推理需求。该项目有助于更好地了解如何满足以下要求:
- 能源消耗
- 以特定的模型精度每秒处理特定数量的帧
- 可靠的推理时间和可扩展性
该项目的第一部分是以简单的方式分析量化的 PyTorch UNet 网络。这是通过三种不同的方法完成的(量化、快速微调量化、量化感知训练)。量化感知训练为 UNet 模型生成最佳输出精度,PSNR 为 33,6874 dB。与浮点模型相比,PSNR 低 6 dB。
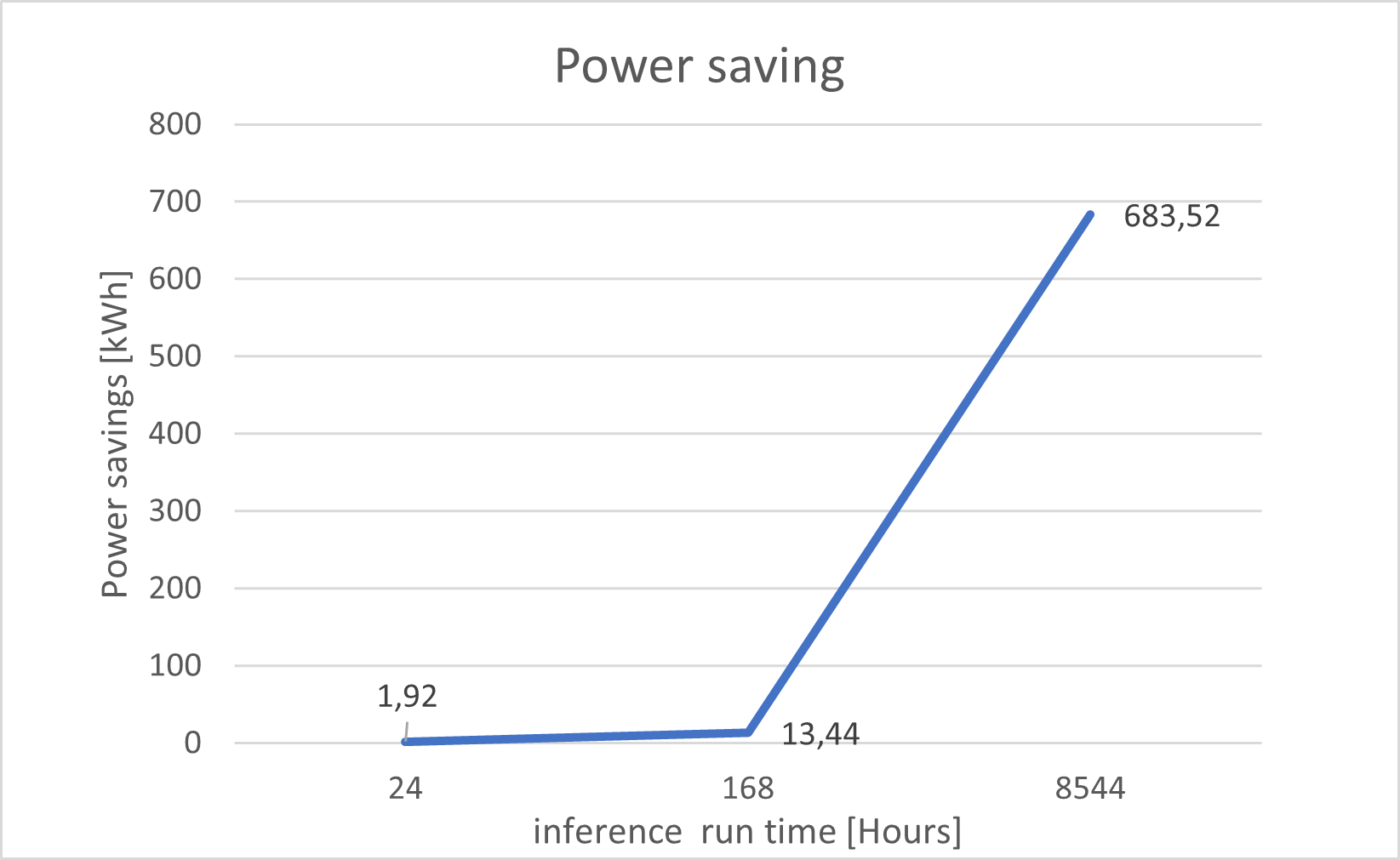
在项目的第二部分中,将 Versal 卡的模型计算的功耗与 GPU 进行了比较。功耗通常比 GPU 所需的低 80 瓦。假设 24/7 工作负载,Versal VCK5000 可以在 24 小时内节省:1、92 千瓦、13、44 千瓦一周和 683 千瓦一年。
该项目的第三部分比较了 Versal 和 GPU 之间的处理性能。在 FPGA 上处理二进制网络可以提高 100% 的 fps。除了处理更多帧的效果外,Versal 管道在每秒帧数方面具有更恒定的处理流程。三小时推理的标准差为:0, 2344 FPS
从一开始就结束循环,人工智能模型有助于解决农作物歉收、食物浪费、交通转向等基本问题,这些问题可以通过 FPGA 进行计算。基于 FPGA 加速器的人工智能推理非常有效,因此 FPGA 可以帮助减少计算系统的全球能源需求并节省大量资源。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 相关下载
- 相关文章




