

如何处理CPU乱序调度中的内存数据依赖
描述
要处理CPU乱序调度中的内存数据依赖,通常涉及两个步骤:
1.计算内存访问的有效地址
2.检查所有未处理完的load/store的地址,并确保冲突的load/store不能乱序执行
A Load / Store Processing Model
load/store处理模型,如下图所示。
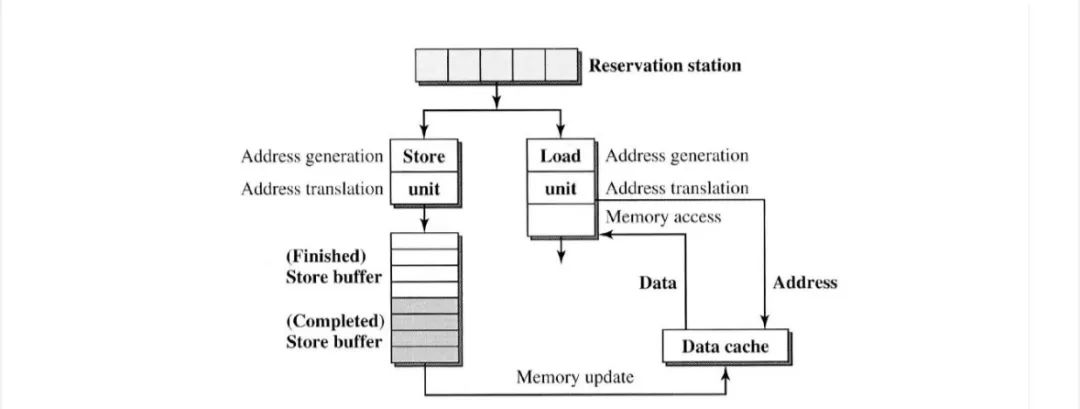
load和store指令首先发给reservation station ,然后发送到load单元或store 单元。
在store单元中,store 指令首先经过有效的地址计算和地址转换,然后驻留在“Finished ”store 缓冲区中。 “completed ”store 缓冲区中的store 指令最终会提交到内存中。
同样,load指令首先通过地址生成和翻译,并最终读取数据cache 以从内存中获取数据。
我们可以做出的一个假设是,store 指令需要按程序顺序完成,因此WAW数据依赖性是默认强制执行的。从本质上讲,处理数据依赖项可以简化为处理load/store 依赖项(RAW和WAR)。
Handling Data Dependencies with In-order Load / Store Dispatch
最直接的解决方案是按程序顺序向公共reservation station 发出load/store 指令,并从reservation station 按FIFO顺序发送。只有当store 缓冲区为空时,才能发送load。然而,load指令的延迟很长,不可预测。尽早执行load至关重要。
改进的方案是支持不同地址的load bypass ,如果store 缓冲区中有地址匹配,则stall load指令。因此,不同地址的load可以继续进行。
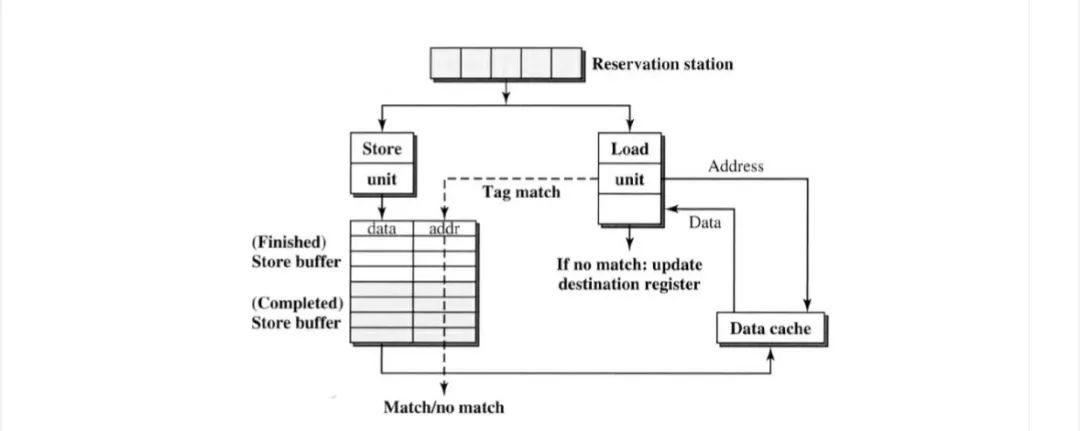
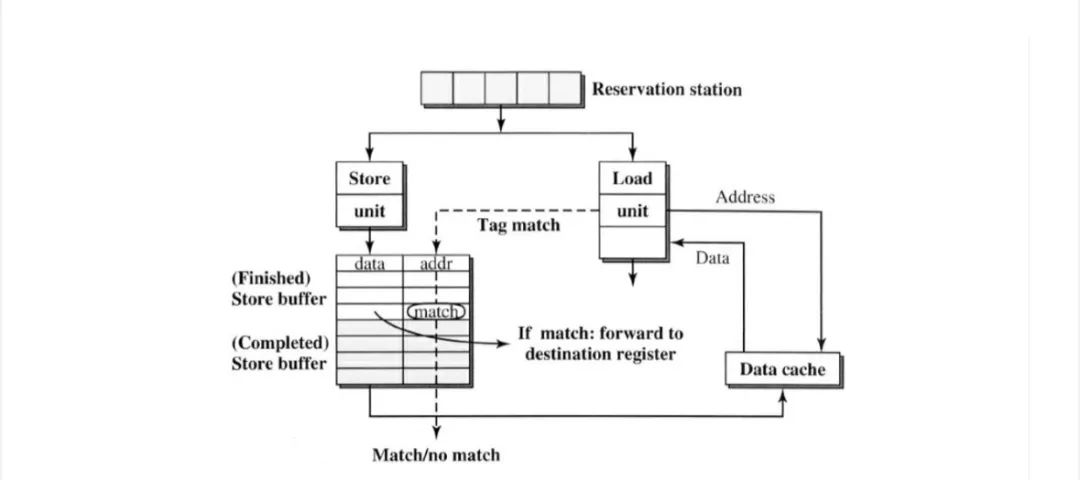
为了进一步加快load。如果存在地址匹配,但store buffer数据不可用,则load stall;如果存在地址匹配和store 数据可用,则将数据直接forward 到load。由于load直接从store buffer接收数据,因此可以尽早执行load指令,并避免数据cache 访问。
Handling Data Dependencies with Out-of-order Load / Store Dispatch
如果我们乱序调度load/store,可以在store之前发放load。由于无法检查地址匹配,因此存在潜在的RAW依赖关系。
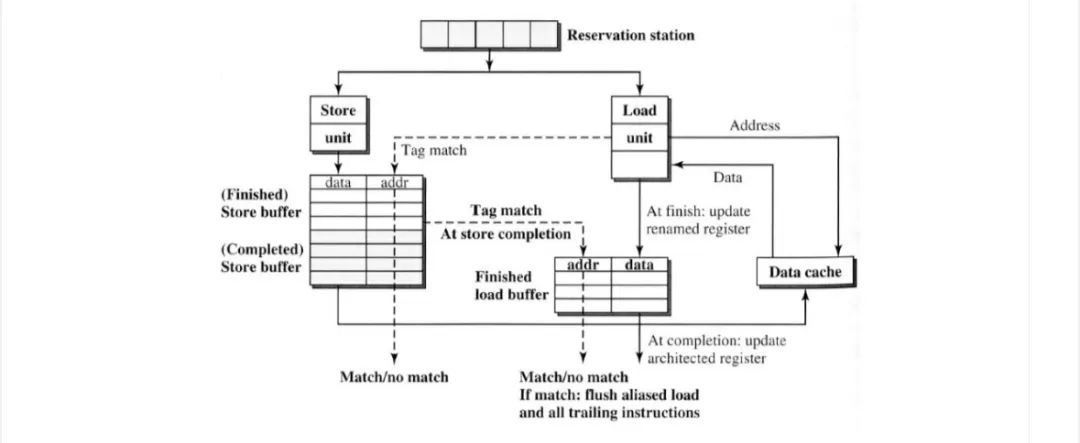
与store指令类似,如果从reservation station 发送的store在“finished ”load buffer中发现匹配的load,则应刷新所有指令。
这种放松也引入了可能的WAR数据依赖性。load地址可能与后续store的地址匹配,因此会触发不正确的数据forward 。一个简单的解决方案是stall 匹配地址的“finished ” store的load,仅具有匹配地址的“completed ”store上数据forward 给load。
-
Cjson协议申请不到内存如何处理?2020-04-26 0
-
如何处理好FPGA设计中跨时钟域间的数据2021-07-29 0
-
labview写入access数据库乱序问题2021-08-09 0
-
如何处理存储在非易失性设备中的内存数据集损坏2021-12-24 0
-
如何处理才能使CPU的效率更高呢?2022-01-27 0
-
stm32如何处理数组中数据2022-02-21 0
-
编译器优化的静态调度介绍2023-03-17 0
-
什么是CPU分枝/乱序执行?2010-02-04 895
-
如何处理cpu风扇转速过快2010-02-25 10015
-
小型Hadoop集群的数据分层调度处理算法分析2017-11-03 488
-
基于GPU/CPU的流程序多粒度划分与调度2017-11-23 752
-
互联车辆如何处理数据:3个常见问题2022-10-31 313
-
证明CPU指令是乱序执行的2023-03-15 961
-
当我们在谈论cpu指令乱序的时候,究竟在谈论什么?2023-05-19 1331
-
MQ消息乱序问题解析与实战解决方案2024-12-06 176
全部0条评论

快来发表一下你的评论吧 !
