2)摘自《STM32F7 开发指南(HAL 库版)》关注官方微信号公众号,获取更多资料:正点原子
3)全套实验源码+手册+视频下载地址:http://www.openedv.com/thread-13912-1-1.html
 第五十二章 手写识别实验
第五十二章 手写识别实验
现在几乎所有带触摸屏的
手机都能实现手写识别。本章,我们将利用 ALIENTEK 提供的手
写识别库,在 ALIENTEK 水星 STM32 开发板上实现一个简单的数字字母手写识别。本章分为
如下几个部:
52.1 手写识别简介
52.2 硬件设计
52.3 软件设计
52.4 下载验证
52.1 手写识别简介
手写识别,是指对在手写设备上书写时产生的有序轨迹信息进行识别的过程,是人际交互
最自然、最方便的手段之一。随着智能手机和平板电脑等移动设备的普及,手写识别的应用也
被越来越多的设备采用。
手写识别能够使用户按照最自然、最方便的输入方式进行文字输入,易学易用,可取代键
盘或者鼠标。用于手写输入的设备有许多种,比如电磁感应手写板、压感式手写板、触摸屏、
触控板、超声波笔等。水星 STM32 开发板自带的 TFTLCD 触摸屏(2.8/3.5/4.3/7 寸等),可以
用来作为手写识别的输入设备。接下来,我们将给大家简单介绍下手写识别的实现过程。
手写识别与其他识别系统如语音识别图像识别一样分为两个过程:训练学习过程;识别过
程。如图 52.1.1 所示:
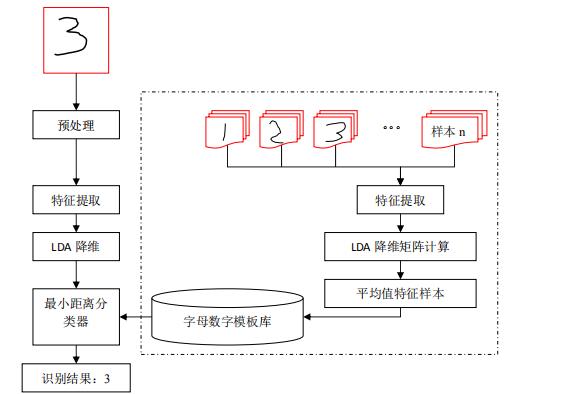
图 52.1.1 字母数字识别系统示意图。
上图中虚线部分为训练学习过程,该过程首先需要使用设备采集大量数据样本,样本类别数目为 0~9,a~z,A~Z 总共 62 类,每个类别 5~10 个样本不等(样本越多识别率就越高)。对
这些样本进行传统的把方向特征提取,提取后特征维数为 512 维,这对 STM32 来讲,计算量
和模板库的存储量来说都难以接受,所以需要运行一些方法进行降维,这里采用 LDA 线性判
决分析的方法进行降维,所谓线性判决分析,即是假设所有样本服从高斯分布(正态分布)对
样本进行低维投影,以达到各个样本间的距离最大化。关于 LDA 的更多知识可以阅读
(
http://wenku.baidu.com/view/f05c731452d380eb62946d39.html)等参考文档。这里将维度降到
64 维,然后针对各个样本类别进行平均计算得到该类别的样本模板。
而对于识别过程,首先得到触屏输入的有序轨迹,然后进行一些预处理,预处理主要包括
重采样,归一化处理。重采样主要是因为不同的输入设备不同的输入处理方式产生的有序轨迹
序列有所不同,为了达到更好的识别结果我们需要对训练样本和识别输入的样本进行重采样处
理,这里主要应用隔点重采样的方法对输入的序列进行重采样;而归一化就是因为不同的书写
风格采样分辨率的差异会导致字体太小不同,因此需要对输入轨迹进行归一化。这里把样本进
行线性缩放的方法归一化为 64*64 像素。
接下来进行同样的八方向特征提取操作。所谓八方向特征就是首先将经过预处理后的
64*64 输入进行切分成 8*8 的小方格,每个方格 8*8 个像素;然后对每个 8*8 个小格进行各个
方向的点数统计。如某个方格内一共有 10 个点,其中八个方向的点分别为:1、3、5、2、3、4、
3、2 那么这个格子得到的八个特征向量为[0.1, 0.3, 0.5,0.2, 0.3, 0.4, 0.3, 0.2]。总共有 64
个格子于是一个样本最终能得到 64*8=512 维特征,更多八方向特征提取可以参考一下两个文
档:
1,
http://wenku.baidu.com/view/d37e5a49e518964bcf847ca5.html;
2,
http://wenku.baidu.com/view/3e7506254b35eefdc8d333a1.html;
由于训练过程进行了 LDA 降维计算,所以识别过程同样需要对应的 LDA 降维过程得到最
终的 64 维特征。这个计算过程就是在训练模板的过程中可以运算得到一个 512*64 维的矩阵,
那么我们通过矩阵乘运算可以得到 64 维的最终特征值。
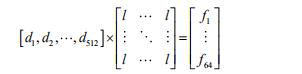
最后将这 64 维特征分别与模板中的特征进行求距离运算。得到最小的距离为该输入的最佳
识别结果输出。
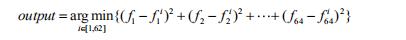
关于手写识别原理,我们就介绍到这里。如果想自己实现手写识别,那得花很多时间学习
和研究,但是如果只是应用的话,那么就只需要知道怎么用就 OK 了,相对来说,简单的多。
ALIENTEK 提供了一个数字字母识别库,这样我们不需要关心手写识别是如何实现的,只
需要知道这个库怎么用,就能实现手写识别。ALIENTEK 提供的手写识别库由 4 个文件组成:
ATKNCR_M_V2.0.lib、ATKNCR_N_V2.0.lib、atk_ncr.c 和 atk_ncr.h。
ATKNCR_M_V2.0.lib 和 ATKNCR_N_V2.0.lib 是两个识别用的库文件(两个版本),使用
的时候,选择其中之一即可。ATKNCR_M_V2.0.lib 用于使用内存管理的情况,用户必须自己
实现 alientek_ncr_malloc 和 alientek_ncr_free 两个函数。而 ATKNCR_N_V2.0.lib 用于不使用内
存管理的情况,通过全局变量来定义缓存区,缓存区需要提供至少 3K 左右的 RAM。大家根据
自己的需要,选择不同的版本即可。ALIENTEK 手写识别库资源需求:FLASH:52K 左右,RAM:
6K 左右。
atk_ncr.c 代码如下:
#include "atk_ncr.h"#include "malloc.h"//内存设置函数void alientek_ncr_memset(char *p,char c,unsigned long len){mymemset((u8*)p,(u8)c,(u32)len);}//内存申请函数void *alientek_ncr_malloc(unsigned int size){return mymalloc(SRAMIN,size);}//内存清空函数void alientek_ncr_free(void *ptr){myfree(SRAMIN,ptr);}这里,主要实现了 alientek_ncr_malloc、alientek_ncr_free 和 alientek_ncr_memset 等三个函数。atk_ncr.h 则是识别库文件同外部函数的接口函数声明#ifndef __ATK_NCR_H#define __ATK_NCR_H//当使用 ATKNCR_M_Vx.x.lib 的时候,不需要理会 ATK_NCR_TRACEBUF1_SIZE 和//ATK_NCR_TRACEBUF2_SIZE//当使用 ATKNCR_N_Vx.x.lib 的时候,如果出现识别死机,请适当增加//ATK_NCR_TRACEBUF1_SIZE 和 ATK_NCR_TRACEBUF2_SIZE 的值#define ATK_NCR_TRACEBUF1_SIZE500*4//定义第一个 tracebuf 大小(单位为字节),如果出现死机,请把该数组适当改大#define ATK_NCR_TRACEBUF2_SIZE250*4//定义第二个 tracebuf 大小(单位为字节),如果出现死机,请把该数组适当改大//输入轨迹坐标类型__packed typedef struct _atk_ncr_point{short x; //x 轴坐标short y; //y 轴坐标}atk_ncr_point;//外部调用函数//初始化识别器//返回值:0,初始化成功// 1,初始化失败unsigned char alientek_ncr_init(void);void alientek_ncr_stop(void); //停止识别器//识别器识别//track:输入点阵集合//potnum:输入点阵的点数,就是 track 的大小//charnum:期望输出的结果数,就是你希望输出多少个匹配结果//mode:识别模式//1,仅识别数字//2,进识别大写字母//3,仅识别小写字母//4,混合识别(全部识别)//result:结果缓存区(至少为:charnum+1 个字节)void alientek_ncr(atk_ncr_point * track,int potnum,int charnum,unsigned char mode,char*result);void alientek_ncr_memset(char *p,char c,unsigned long len); //内存设置函数//动态申请内存,当使用 ATKNCR_M_Vx.x.lib 时,必须实现.void *alientek_ncr_malloc(unsigned int size);//动态释放内存,当使用 ATKNCR_M_Vx.x.lib 时,必须实现.void alientek_ncr_free(void *ptr);#endif此段代码中,我们定义了一些外部接口函数以及一个轨迹结构体等。
alientek_ncr_init,该函数用与初始化识别器,该函数在.lib 文件实现,在识别开始之前,我
们应该调用该函数。
alientek_ncr_stop,该函数用于停止识别器,在识别完成之后(不需要再识别),我们调用
该函数,如果一直处于识别状态,则没必要调用。该函数也是在.lib 文件实现。
alientek_ncr,该函数就是识别函数了。它有 5 个参数,第一个参数 track,为输入轨迹点的
坐标集(最好 200 以内);第二个参数 potnum,为坐标集点坐标的个数;第三个参数 charnum,
为期望输出的结果数,即希望输出多少个匹配结果,识别器按匹配程度排序输出(最佳匹配排
第一);第四个参数 mode,该函数用于设置模式,识别器总共支持 4 中模式:
1,仅识别数字
2,进识别大写字母
3,仅识别小写字母
4,混合识别(全部识别)
最后一个参数是 result,用来输出结果,注意这个结果是 ASCII 码格式的。
alientek_ncr_memset、alientek_ncr_free 和 alientek_ncr_free 这 3 个函数在 atk_ncr.c 里面实现,
这里就不多说了。
最后,我们看看通过 ALIENTEK 提供的手写数字字母识别库实现数字字母识别的步骤:
1) 调用 alientek_ncr_init 函数,初始化识别程序
该函数用来初始化识别器,在手写识别进行之前,必须调用该函数。
2) 获取输入的点阵数据
此步,我们通过触摸屏获取输入轨迹点阵坐标,然后存放到一个缓存区里面,注意至
少要输入 2 个不同坐标的点阵数据,才能正常识别。注意输入点数不要太多,太多的话,
需要更多的内存,我们推荐的输入点数范围:100~200 点。
3) 调用 alientek_ncr 函数,得到识别结果.
通过调用 alientek_ncr 函数,我们可以得到输入点阵的识别结果,结果将保存在 result
参数里面,采用 ASCII 码格式存储
4) 调用 alientek_ncr_stop 函数,终止识别.
如果不需要继续识别,则调用 alientek_ncr_stop 函数,终止识别器。如果还需要继续识
别,重复步骤 2 和步骤 3 即可。
以上 4 个步骤,就是使用 ALIENTEK 手写识别库的方法,十分简单。
52.2 硬件设计
本章实验功能简介:开机的时候先初始化手写识别器,然后检测字库,之后进入等待输入
状态。此时,我们在手写区写数字/字符,在每次写入结束后,自动进入识别状态,进行识别,
然后将识别结果输出在 LCD 模块上面(同时打印到串口)。通过按 KEY0 可以进行模式切换
(4 种模式都可以测试),通过按 KEY1,可以进入触摸屏校准(如果发现触摸屏不准,请执
行此操作)。DS0 用于指示程序运行状态。
本实验用到的资源如下:
1) 指示灯 DS0
2) KEY0 和 KEY1 两个按键
3) 串口
4) LCD 模块(含触摸屏)
5) SPI FLASH
这些用到的硬件,我们在之前都已经介绍过,这里就不再介绍了。
52.3 软件设计
打开本章实验工程目录可以看到,我们在工程根目录文件夹下新建一个 ATKNCR 的文件夹。
将 ALIETENK 提供的手写识别库文件(ATKNCR_M_V2.0.lib、ATKNCR_N_V2.0.lib、atk_ncr.c
和 atk_ncr.h 这四个个文件,在光盘→ 4,程序源码→5,ATKNCR(数字字母手写识别库) 文件
夹里面)拷贝到该文件夹下,然后在工程里面新建一个 ATKNCR 的组,将 atk_ncr.c 和
ATKNCR_M_V2.0.lib 加入到该组下面(这里我们使用内存管理版本的识别库)。最后,将
ATKNCR 文件夹加入头文件包含路径。
关于 ATKNCR_M_V2.0.lib 和 atk_ncr.c 前面已有介绍,我们这里就不再多说,我们在 main.c
里面修改代码如下:
//最大记录的轨迹点数atk_ncr_point READ_BUF[200];//画水平线//x0,y0:坐标 len:线长度 color:颜色void gui_draw_hline(u16 x0,u16 y0,u16 len,u16 color){if(len==0)return;LCD_Fill(x0,y0,x0+len-1,y0,color);}//画实心圆//x0,y0:坐标 r:半径 color:颜色void gui_fill_circle(u16 x0,u16 y0,u16 r,u16 color){……//省略部分非关键代码,具体代码请参考实验源码}//两个数之差的绝对值//x1,x2:需取差值的两个数//返回值:|x1-x2|u16 my_abs(u16 x1,u16 x2){……//省略部分非关键代码,具体代码请参考实验源码}//画一条粗线//(x1,y1),(x2,y2):线条的起始坐标//size:线条的粗细程度 color:线条的颜色void lcd_draw_bline(u16 x1, u16 y1, u16 x2, u16 y2,u8 size,u16 color){……//省略部分非关键代码,具体代码请参考实验源码}int main(void){ u8 i=0, tcnt=0,res[10],key;u16 pcnt=0;u8 mode=4;//默认是混合模式u16 lastpos[2];//最后一次的数据 Cache_Enable(); //打开 L1-Cache HAL_Init(); //初始化 HAL 库 Stm32_Clock_Init(432,25,2,9); //设置时钟,216Mhz delay_init(216); //延时初始化uart_init(115200); //串口初始化usmart_dev.init(108);//初始化 USMART LED_Init(); //初始化 LED KEY_Init(); //初始化按键 SDRAM_Init(); //初始化 SDRAM LCD_Init(); //初始化 LCD W25QXX_Init();//初始化 W25Q256 tp_dev.init(); //初始化触摸屏 my_mem_init(SRAMIN); //初始化内部内存池 my_mem_init(SRAMEX); //初始化外部 SDRAM 内存池 my_mem_init(SRAMDTCM); //初始化内部 CCM 内存池 alientek_ncr_init(); //初始化手写识别 while(font_init())//检查字库{LCD_ShowString(60,50,200,16,16,"Font Error!");delay_ms(200);LCD_Fill(60,50,240,66,WHITE);//清除显示}RESTART:……//此处省略部分代码tcnt=100;tcnt=100;while(1){key=KEY_Scan(0);if(key==KEY1_PRES&&(tp_dev.touchtype&0X80)==0){TP_Adjust();//屏幕校准LCD_Clear(WHITE);goto RESTART;//重新加载界面}if(key==KEY0_PRES){LCD_Fill(20,115,219,314,WHITE);//清除当前显示mode++;if(mode>4)mode=1;switch(mode){case 1:Show_Str(80,207,200,16,"仅识别数字",16,0);break;case 2:Show_Str(64,207,200,16,"仅识别大写字母",16,0);break;case 3:Show_Str(64,207,200,16,"仅识别小写字母",16,0);break;case 4:Show_Str(88,207,200,16,"全部识别",16,0);break;}tcnt=100;}tp_dev.scan(0);//扫描if(tp_dev.sta&TP_PRES_DOWN)//有按键被按下{delay_ms(1);//必要的延时,否则老认为有按键按下.tcnt=0;//松开时的计数器清空if((tp_dev.x[0]<(lcddev.width-20-2)&&tp_dev.x[0]>=(20+2))&& (tp_dev.y[0]<(lcddev.height-5-2)&&tp_dev.y[0]>=(115+2))){if(lastpos[0]==0XFFFF){lastpos[0]=tp_dev.x[0];lastpos[1]=tp_dev.y[0];}lcd_draw_bline(lastpos[0],lastpos[1],tp_dev.x[0],tp_dev.y[0],2,BLUE);/画线lastpos[0]=tp_dev.x[0];lastpos[1]=tp_dev.y[0];if(pcnt<200)//总点数少于 200{if(pcnt){if((READ_BUF[pcnt-1].y!=tp_dev.y[0])&& (READ_BUF[pcnt-1].x!=tp_dev.x[0]))//x,y 不相等{READ_BUF[pcnt].x=tp_dev.x[0];READ_BUF[pcnt].y=tp_dev.y[0];pcnt++;}}else{READ_BUF[pcnt].x=tp_dev.x[0];READ_BUF[pcnt].y=tp_dev.y[0];pcnt++;}}}}else //按键松开了{lastpos[0]=0XFFFF;tcnt++;delay_ms(10);//延时识别i++;if(tcnt==40){if(pcnt)//有有效的输入{printf("总点数:%drn",pcnt);alientek_ncr(READ_BUF,pcnt,6,mode,(char*)res);printf("识别结果:%srn",res);pcnt=0;POINT_COLOR=BLUE;//设置画笔蓝色LCD_ShowString(60+72,90,200,16,16,res);}LCD_Fill(20,115,lcddev.width-20-1,lcddev.height-5-1,WHITE);}}if(i==30){i=0;LED0_Toggle;}}}这里代码看上去比较多,其实很多都是为 lcd_draw_bline 函数服务的,lcd_draw_bline 函数用
于实现画指定粗细的直线,以得到较好的画线效果。而 main 函数,则实现 58.1.2 节提到的功能。
其中,READ_BUF 用来存储输入轨迹点阵,大小为 200,即最大输入不能超过 200 点,注意:
这里我们采集的都是不重复的点阵(即相邻的坐标不相等)。这样可以避免重复数据,而重复的
点阵数据对识别是没有帮助的。
至此,本实验的软件设计部分结束。
52.4 下载验证
在代码编译成功之后,我们下载代码到 ALIENTEK 水星 STM32 开发板上,得到,如图 52.4.1
所示:
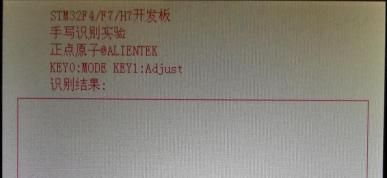
图 52.4.1 手写识别界面
此时,我们在手写区写数字/字母,即可得到识别结果,如图 52.4.2 所示:

图 52.4.2 手写识别结果
按下 KEY0 可以切换识别模式,同时在识别区提示当前模式。按下 KEY1 可以进行屏幕校
准(仅限电阻屏,电容屏无需校准)。每次识别结束,会在串口打印本次识别的输入点数和识别
结果,大家可以通过串口助手查看。


